
This post has been republished via RSS; it originally appeared at: AzureCAT articles.
First published on MSDN on Aug 14, 2018
Written by Kanchan Mehrotra, Tony Wu, and Rakesh Patil from AzureCAT. Reviewed by Solliance. Edited by Nanette Ray.
This article is also available as an eBook:
When customers ask our team (AzureCAT) to help them deploy large-scale cluster computing on Microsoft Azure, we tell them about Parallel Virtual File Systems (PVFSs). Several open-source systems are available, such as the Lustre, GlusterFS, and BeeGFS file systems, and we have worked with them all. But how well do they scale on Azure? To find out, we ran several informal performance tests using default configurations to compare Lustre, GlusterFS, and BeeGFS.
A PVFS distributes file data across multiple servers and provides concurrent access by multiple tasks of a parallel application. Used in high-performance computing (HPC) environments, a PVFS delivers high-performance access to large data sets.
A PVFS cluster includes nodes designated as one or more clients, plus management servers, storage servers, and metadata servers. Storage servers hold file data, while metadata servers store statistics, attributes, data file-handles, directory entries, and other metadata. Clients run applications that use the file system by sending requests to the servers over the network.
This document explains our testing process and the results we received. We looked at the performance requirements for maximum throughput and input/output operations per sec (IOPs). We also walked through the installation and configuration of each PVFS and compared the ease of setup. Lustre, GlusterFS, and BeeGFS all performed well on Azure.
We hope this default configuration serves as a baseline you can refer to when designing and sizing a PVFS architecture on Azure that meets your needs. We also show how to install the tools we used for performance testing, so you can try your own comparison tests. The test scripts are available from the az-cat/HPC-Filesystems repository on GitHub.
Performance results
All our tests were performed on Linux virtual machines on Azure. The DS14v2 size was used for its balance of performance and cost backed by solid-state drives (SSD) with locally redundant storage (LRS). The test environment setup is shown in Figure 1. 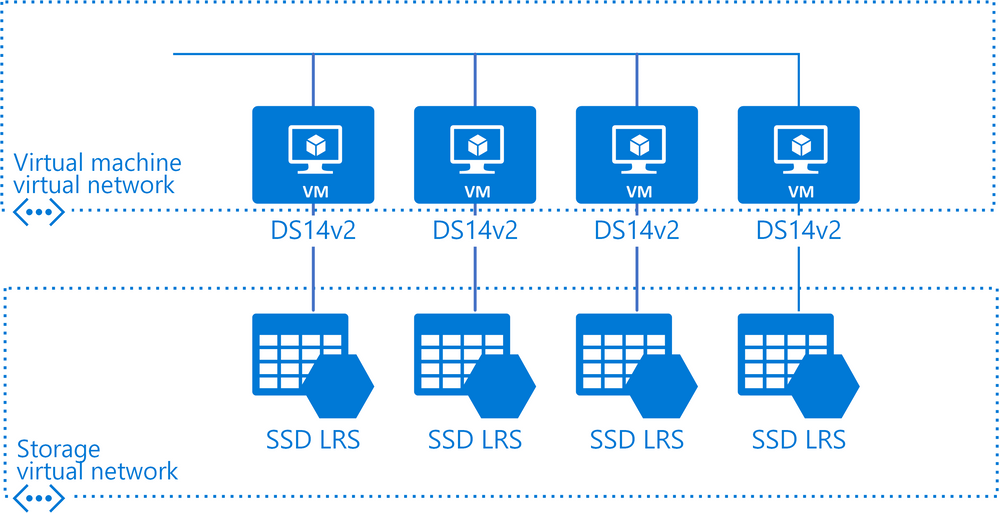
Figure 1. Simplified diagram of the test environment setup on Azure
Although our team would have liked to do more comprehensive testing, our informal efforts clearly showed that performance tuning was the key to getting the best results. Overall, performance scaled as expected as more nodes were added to the cluster.
Table 1 compares the best throughput performances from our tests. Later sections of this document describe our processes and results in detail for each PVFS, but in general, the tests showed a linear performance gain as storage size in terabytes (TB) increased for all three PVFSs. We were not able to investigate every unusual result, but we suspect that the Lustre caching effect (described later in this document) boosted its test results. The IOPs testing is based on a 4K transfer size with a random pattern and a 32 MB transfer size with a sequential pattern for the throughput (bandwidth) testing.
For more information, including NFS baselines, see Parallel File Systems for HPC Storage on Azure. 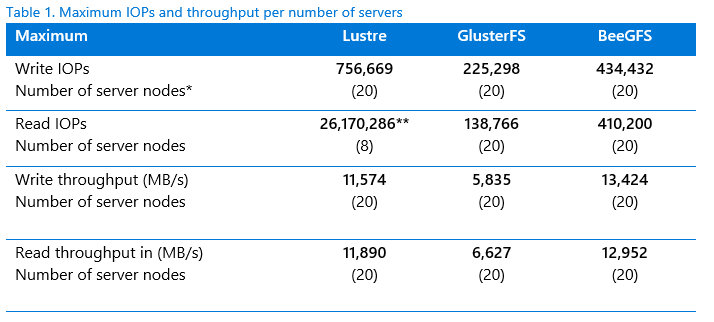
* 10 clients with multiple processes running, each client using all the CPU cores and networking bandwidth of the client virtual machine.
** This high value likely reflects a caching effect for the Lustre testing. We used default testing parameters without performance-tuning.
Ease of deployment
We also wanted to find out how easy each PVFS was to deploy on Azure. We compared the main components of the architecture (Table 2), which can include multiple nodes—such a metadata server (MDS), metadata target (MDT), management server (MGS), object storage server (OSS)—and file system clients. Table 2 summarizes top-level deployments points. 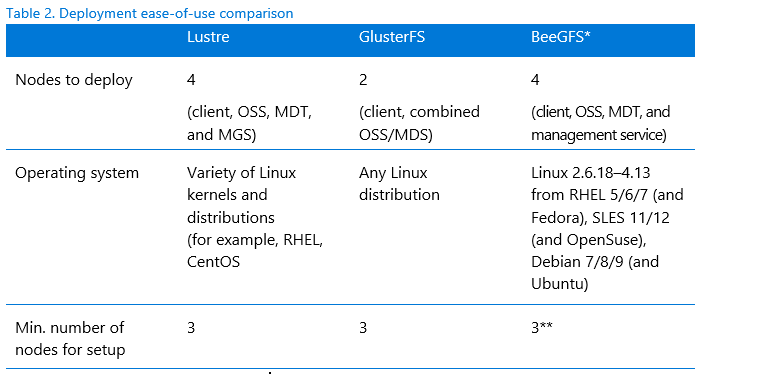
* BeeGFS data and metadata servers support mirroring only. There are no RAID considerations. BeeGFS replicates between high availability nodes automatically for the managed data.
** Technically speaking, you can install all four BeeGFS components on one node, but practically speaking, at least three nodes should be used.
Based on our team’s experiences during testing, we developed the following unofficial ease-of-use rating system—the Cloudies—as shown in Table 3. For more results, see the specific file system sections later in this document. 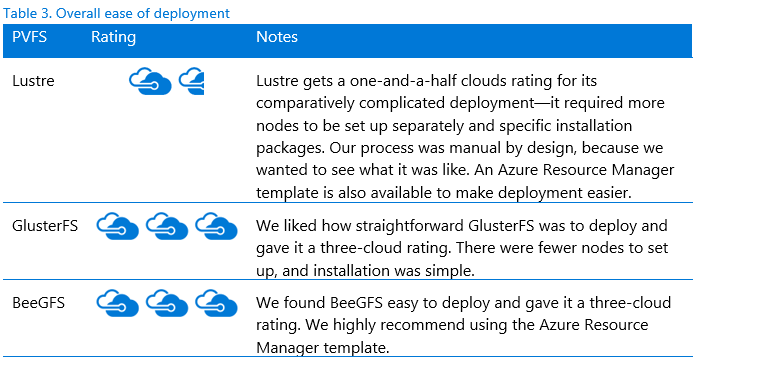
Thank you for reading!
This article is also available as an eBook:

AzureCAT Guidance
"Hands-on solutions, with our heads in the Cloud!"