
This post has been republished via RSS; it originally appeared at: Microsoft Research.

From February 26–28, researchers gathered in Boston for the 16th USENIX Symposium on Networked Systems Design and Implementation (NSDI), one of the top conferences in the networking and systems field. Microsoft, a silver sponsor of the event, was represented by researchers serving on the program committee, as well as those presenting papers, including two research teams using novel abstractions to empower and better serve cloud users.
“Both papers describe new ways to cope with the ever-increasing scale and complexity of what it means to do state-of-the-art computing in the cloud,” said Thomas Moscibroda, Microsoft Partner Research Scientist, Azure Compute.
With their respective work, the teams seek to simplify the underlying operations—or what Microsoft Principal Scientist Konstantinos Karanasos, co-author on the other paper, calls “the magic”—to deliver a more efficient and seamless user experience.
Direct Universal Access: A communications architecture
Field programmable gate arrays (FPGAs) are becoming widely used in today’s data centers. These reprogrammable circuits combine the advantages of hardware speed while offering some of the flexibility that makes software ideal for programming. But taking advantage of their full potential at cloud computing scale has been extremely challenging for several reasons, and researchers in the Networking Research Group at Microsoft Research Asia, in collaboration with engineering leaders in Microsoft Azure, are hoping to change that by addressing one such obstacle: the absence of an efficient, reliable, easy-to-use communications layer.
In their paper “Direct Universal Access: Making Data Center Resources Available to FPGA,” they present a new communications architecture, one that Microsoft Researcher Peng Cheng and his co-authors liken to the Internet Protocol or the operating system of a computer.
“Our challenge has been, how do we provide a software-like IP layer inside this hardware-based platform,” said Cheng, adding that the goal is a unified platform.
Currently, communication between pairs of FPGAs and other data center resources, such as CPUs, GPUs, memory, and storage, is complex, making programming large-scale heterogenous applications impractical and, at times, nearly impossible.
There are several reasons for this, the researchers explain in their paper: First, the communications paradigms used for connecting resources that are local to a server and resources that are remote—that is, located on a different server in the data center—are different and use vastly different communications stacks. Secondly, resources are named in a way that is specific to the server they live on. And lastly, current FPGA architecture is inefficient when it comes to multiplexing multiple diverse communications links to different local and remote resources.
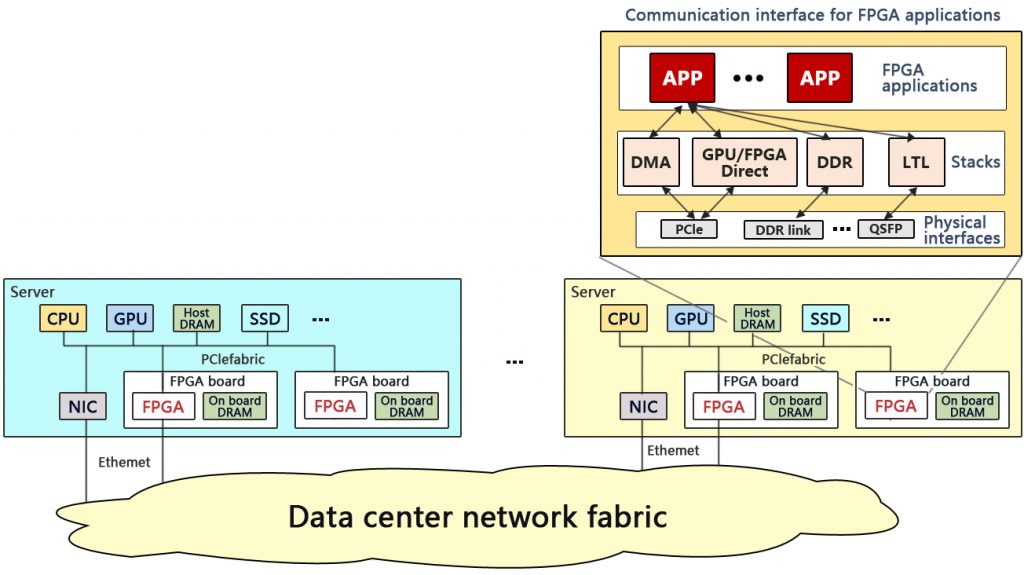

Current FPGA communications architecture (top) compared to an ideal FPGA communications architecture. Deploying a common communications interface, a global unified naming scheme, and an underlying network service providing routing and multiplexing, the ideal architecture captured by DUA will allow designers and developers to build large-scale heterogenous FPGA-based applications.
Direct Universal Access (DUA) makes communication among data center resources possible and easier by providing a common communications interface, a global unified naming scheme, and an underlying network service that provides routing and resource multiplexing, creating a common resource pool that can be accessed uniformly and efficiently. The architecture is implemented as an overlay network—a layer between the developer and the various data center communications stacks and resources—and supports systems and communications protocols currently in place. This is critical because it means that no manufacturing overhaul of existing devices is required; DUA can be deployed as is on existing frameworks.
“DUA connects all resources in a data center regardless of location and type of resource,” explained Microsoft Associate Researcher Ran Shu. “All these resources are in a unified naming space and unified IP-based networking scheme, so each application can access different resources with the same code, so it is easy for developers to port their code, and it greatly reduces application development time.”
The researchers hope DUA will allow developers to build large-scale, diverse, and novel FPGA-based applications that, before this, haven’t been within reach.
“The proliferation of FPGAs in the cloud is a reality and offers gigantic promise because if we can make it easy for developers to use and connect the different types of data center resources in an efficient way, they can build novel types of applications that are inconceivable otherwise,” said Moscibroda.
To demonstrate this potential, the research team has built two large-scale FPGA applications—regular expression matching for packet inspection and deep crossing, a machine learning algorithm—on top of DUA.
The team is in the process of making DUA open-source, and it will be available on GitHub soon.
Hydra: A resource management framework
Cloud services for storing, analyzing, and managing big data can process thousands of jobs for thousands of users in a single day. No small order. And it’s the responsibility of the service’s resource manager to make sure these jobs go off without a hitch. The resource management infrastructure determines where a particular job and its tasks should run and what share of resources each user should get to accomplish said job. For smaller-scale services, the challenges of task placement and share determination can generally be tackled together. But Microsoft is no small-scale operation.
Serving 10,000 users and running half a million jobs daily across hundreds of thousands of machines, Microsoft was in need of a new approach, so its researchers set out to deliver a resource manager capable of offering the scalability and utilization of its existing infrastructure while also meeting several additional key requirements: It needed to be able to handle not only a high volume of work but also a diverse workload, including both internal Microsoft applications and open-source frameworks; it needed to allocate resources in a more principled and efficient way; and it needed to make the testing of new features easier.
The result of their work is Hydra, the main resource manager behind the big-data analytics clusters of Microsoft today. The infrastructure has actually been in place for a few years now, the team migrating 99 percent of users over in real-time while continuing services. “This is what we call changing airplane engines mid-flight,” Karanasos said with a laugh.
In their paper “Hydra: A Federated Resource Manager for Data-Center Scale Analytics,” Karanasos and his co-authors unveil the newest—and arguably one of the most important components—to Hydra, the federated architecture it leverages to divide and conquer task placement and share determination.
“With our requirements, we had to split the problem,” explained Karanasos. “Anything else would not scale or would give up quality.”

With its federated architecture (above), Hydra can scale to individual clusters of over 50,000 machines and perform scheduling decisions at rates that are 10 times to 100 times higher than existing resource managers.
A federated architecture offers a middle-of-the-road design solution, falling in between a centralized architecture, which is effective at share determination but harder to scale, and a distributed architecture, which can scale well but makes it difficult to impose strong scheduling guarantees.
With a federated architecture, each cluster of machines is separated into loosely coordinating subclusters, allowing Hydra to determine placement and resource sharing separately. Placement is handled locally in each subcluster while share determination is based on an aggregate view of cluster resources. With this architecture, Hydra can scale to individual clusters of over 50,000 machines and perform scheduling decisions at rates that are 10 times to 100 times higher than existing resource managers. Hydra’s decisions are determined by a set of policies that can be dynamically adjusted based on the cluster conditions and the user needs, providing great flexibility to the cluster operators.
“Hydra’s carefully designed architecture and policies hide from the users the existence of multiple subclusters, providing them with the illusion of a single massive cluster,” said Karanasos. “Users simply submit their jobs to the cluster, and Hydra decides the machines that the jobs’ tasks will run on, possibly including machines spread across subclusters.”
Since its deployment, Hydra has scheduled a trillion tasks and processed over a zettabyte of data. The good news is Hydra is open-source as an extension of the Apache Hadoop YARN resource management project.
The post Researchers seek to simplify the complex in cloud computing appeared first on Microsoft Research.