
This post has been republished via RSS; it originally appeared at: Microsoft Research.
There is growing interest in exploring the use of variational auto-encoders (VAE), a deep latent variable model, for text generation. Compared to the standard RNN-based language model that generates sentences one word at a time without the explicit guidance of a global sentence representation, VAE is designed to learn a probabilistic representation of global language features such as topic, sentiment or language style, and makes the text generation more controllable. For example, VAE can generate sentences with a specific tense, sentiment or topic.
However, training VAE on languages is notoriously difficult due to something called KL vanishing. While VAE is designed to learn to generate text using both local context and global features, it tends to depend solely on local context and ignore global features when generating text. When this happens, VAE is essentially behaving like a standard RNN language model.
In “Cyclical Annealing Schedule: A Simple Approach to Mitigating KL Vanishing,” to be presented at 2019 Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), researchers at Microsoft Research AI and Duke University propose an extremely simple remedy to KL vanishing as well as their proposal to make the code publicly available on Github. The remedy is based on a new scheduling scheme called Cyclical Annealing Schedule. Intuitively, during the course of VAE training, we periodically adjust the weight of the KL term in the objective function, providing the model opportunities to learn to leverage the global latent variables in text generation, thus encoding as much global information in the latent variables as possible. The paper briefly describes KL vanishing and why it happens, introduces the proposed remedy, and illustrates the VAE learning process using a synthetic dataset.
What is KL vanishing and why does it happen?
VAEs aim to learn probabilistic representations z of natural languages x, with an objective consisting of two terms: (1) reconstruction to guarantee the inferred latent feature z can represent its corresponding observed sentence; and (2) KL regularization to leverage the prior knowledge to modulate language understanding. The two terms are balanced by a weighting hyper-parameter β:
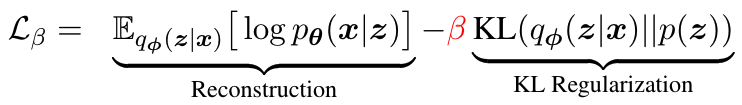
When applied on text corpora, VAEs typically employ an auto-regressive decoder, which sequentially generates the word tokens based on ground-truth words in the previous steps, in conjunction with latent z. Recent work has found that naïve training of VAEs (keeping constant β=1) leads to model degeneration—the KL term becomes vanishingly small. This issue causes two undesirable outcomes: (1) the learned features are almost identical to the uninformative Gaussian prior, for all observed languages; and (2) the decoder completely ignores the latent feature, and the learned model reduces to a simpler neural language model. Hence, the KL vanishing issue.
This negative result is so far poorly understood. We developed a two-path competition interpretation to shed light on the issue. Let’s first look at the standard VAE in Figure 1 (a), below. The reconstruction of sequence x=[x1 ,…,xT] depends only on one path passing through the encoder ϕ, latent representation z and decoder Θ. However, when an auto-regressive decoder is used in a VAE, there are two paths from observed x to its reconstruction, as shown in Figure 1(b). Path A is the same as that in the standard VAE, where z serves as the global representation that controls the generation of x; Path B leaks the partial ground-truth information of x at every time step of the sequential decoding. It generates xt conditioned on x<t=[x1,…,xt-1]. Therefore, Path B can potentially bypass Path A to generate xt, leading to KL vanishing. From this perspective, we hypothesize that the KL vanishing problem is related to the low quality of z at the beginning phase of decoder training. This is highly possible when the naive constant schedule of β=1 is used, as the KL term pushes z close to an uninformative prior, less representative of the corresponding observations. This lower quality z introduces more difficulties in reconstructing x, and eventually blocks the information flow via Path A. As a result, the model is forced to learn an easier solution to decoding—generating x via Path B only.

Figure 1: Illustration of information flows on (a) one path in a standard VAE, and (b) two paths in a VAE with an auto-regressive decoder.
Cyclical Annealing Schedule
A simple remedy via scheduling β during VAE training was proposed by Bowman, et al, as shown in Figure 2(a). It starts with β=0 at the beginning of training, and gradually increases β until β=1 is reached. This monotonic schedule of β has become the de facto standard in training text VAEs, and has been widely adopted in many NLP tasks. Why does it improve the performance empirically? When β<1, z is trained to focus more on capturing useful information for reconstruction of x. When the full VAE objective is considered (β=1), z learned earlier can be viewed as VAE initialization; such latent features are much more informative than the random start in constant schedule and thus are ready for the decoder to use.
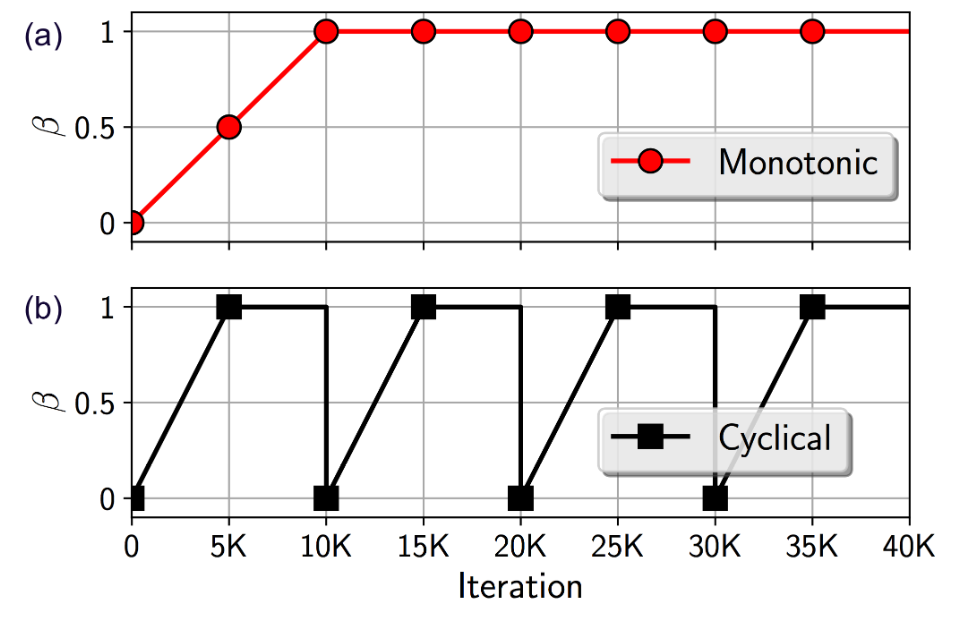
Figure 2: Annealing β with (a) the monotonic schedule and (b) the cyclical schedule.
Is there a better schedule? It is key to have meaningful latent z at the beginning of training the decoder, so that Path A is utilized. The monotonic schedule under-weights the prior regularization when β<1; the learned z tends to collapse into a point estimate. This underestimation can result in sub-optimal decoder learning. A natural question concerns how one can get a better distribution estimate for z as initialization, while decoder has the opportunity to leverage such z in learning.
Our proposal is to use the latent z trained under the full VAE objective as initialization. To learn to progressively improve z we propose a cyclical schedule for β that simply repeats the monotonic schedule multiple times as shown in Figure 2(b). We start with β=0, increase β at a fast rate, and then stay at β=1 for subsequent learning iterations. This completes one period of monotonic schedule. It encourages the model to converge towards the VAE objective, and infers its first raw full latent distribution. Unfortunately, β=1 gradually blocks Path A, forbidding more information from passing through z. Crucially, we then start the second period of β annealing and training is continued at β=0 again. This perturbs the VAE objective, dislodges it from the convergence, and reopens Path A. Importantly, the decoder now (1) has the opportunity to directly leverage z, without obstruction from KL; and (2) is trained with the better latent z than point estimates, as the full distribution learned in the previous period is fed in. We repeat this β annealing process several times to achieve better convergences.
Visualization of learning dynamics in the latent space
To visualize the learning processes on an illustrative problem, let’s consider a synthetic dataset consisting of 10 different sequences, as well as a VAE model with a 2-dimensional latent space, and an LSTM encoder and decoder.
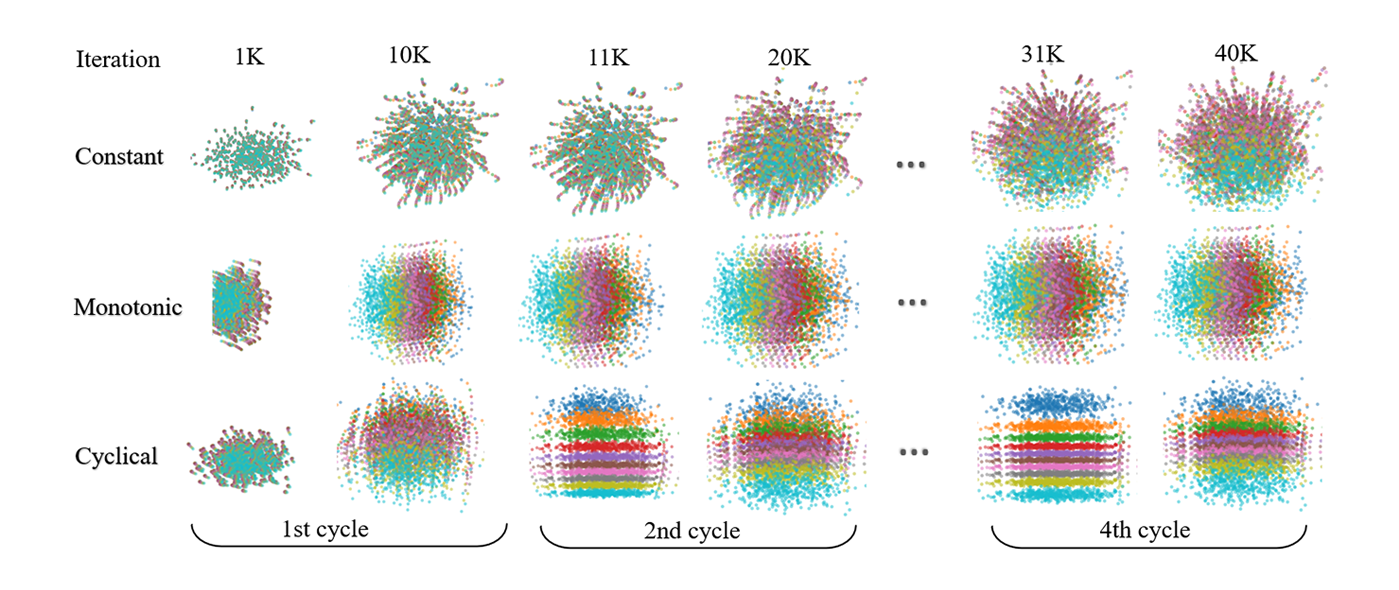
We visualize the resulting division of the latent space for different training steps in Figure 3, where each color corresponds to the latent probabilistic representation of a sequence. We observe that:
- The constant schedule produces heavily mixed latent codes z for different sequences throughout the entire training process.
- The monotonic schedule starts with a mixed z, but soon divides the space into a mixture of 10 cluttered Gaussians in the annealing process (the division remains cluttered in the rest of training).
- The cyclical schedule behaves similarly to the monotonic schedule in the 1st cycle. But starting from the 2nd cycle, much more divided clusters are shown when learning on top of the 1st period results. However, β<1 leads to some holes between different clusters. This is alleviated at the end of the 2nd cycle, as the model is trained with β=1. As the process repeats, we see clearer patterns in the 4th cycle than the 2nd cycle for both β<1 and β=1. It shows that more structured information is captured in z, using the cyclical schedule.
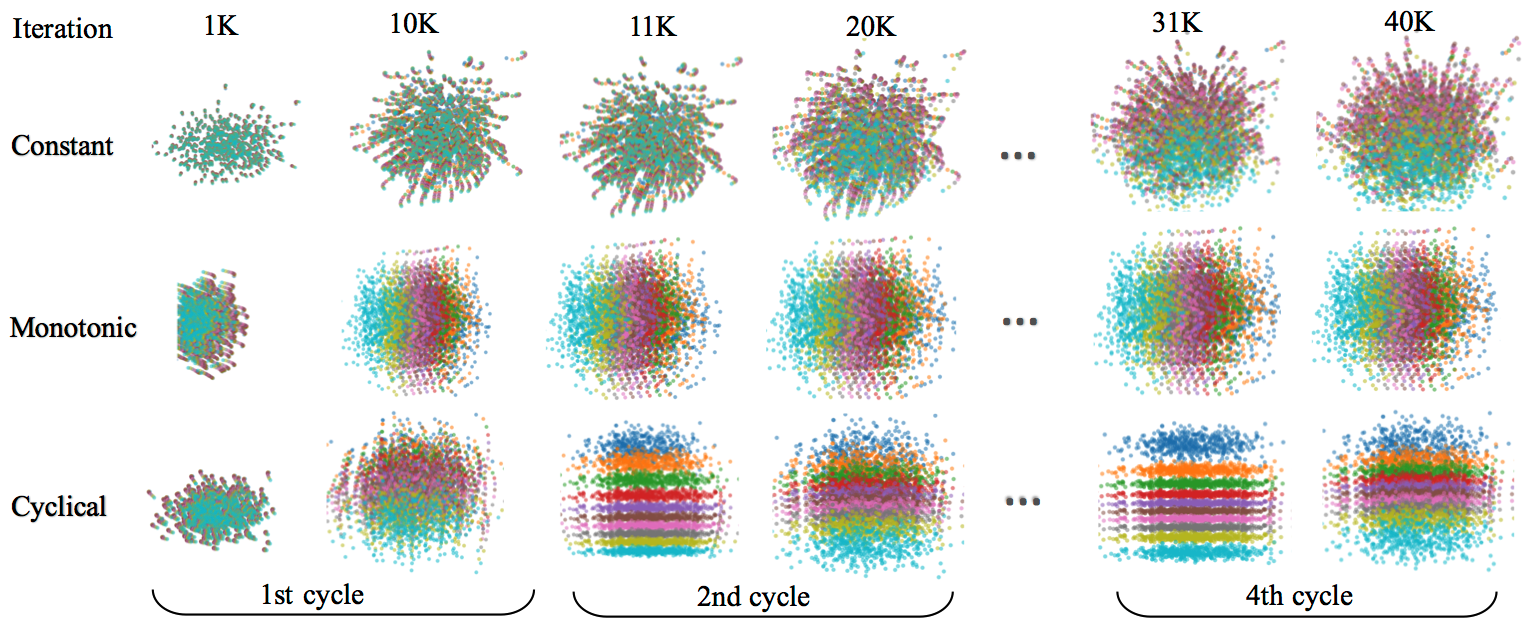
Figure 3: The process of learning probabilistic representations in the latent space for three schedules.
The learning curves for the VAE objective (ELBO), reconstruction error, and KL term are shown in Figure 4. The three schedules share very similar ELBO values. However, the cyclical schedule provides substantially lower reconstruction error and higher KL divergence. Interestingly, the cyclical schedule improves the performance progressively; it becomes better than the previous cycle, and there are clear periodic patterns across different cycles. This suggests that the cyclical schedule allows the model to use the previously learned results as a warm-restart to achieve further improvement.
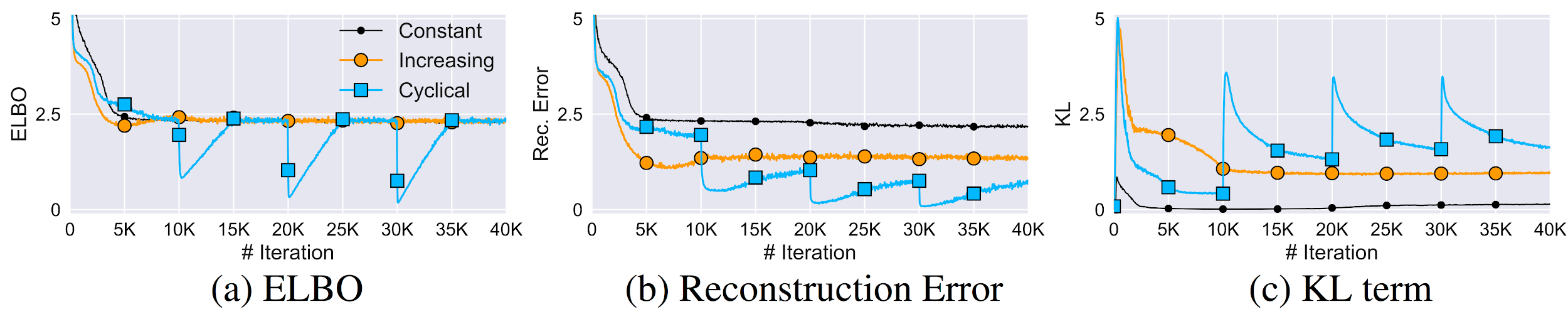
Figure 4: Comparison of terms in VAE for three schedules.
Improving performance on NLP tasks
The new cyclical schedule has been demonstrated to be effective in improving probabilistic representations of synthetic sequences on the illustrative example, but is it beneficial in downstream real-world natural language processing (NLP) applications? We tested it on three tasks:
- Language Modeling. On the Penn Tree-Bank dataset, the cyclical schedule can provide more informative language representations (measured by the improved KL term), while retaining the similar perplexity. It is significantly faster than existing methods, and can be combined to improve upon them.
- Dialog response generation. It is key to have probabilistic representations for conversational context, reasoning stochastically for different but relevant responses. On the SwitchBoard dataset, the cyclical schedule generates highly diverse answers that cover multiple plausible dialog acts.
- Unsupervised Language Pre-training. On the Yelp dataset, a language VAE model is first pre-trained to extract features, then a classifier is fine-tuned with different proportions of labelled data. The cyclical schedule provides robust distribution-based representations of sentences, yielding strong generalization on testing datasets.
We hope to see you at NAACL-HLT this June to discuss these approaches in more detail and we’ll look forward to hearing what you think!
Acknowledgements
This research was conducted by Chunyuan Li, Hao Fu, Xiaodong Liu, Jianfeng Gao, Asli Celikyilmaz, and Lawrence Carin. Additional thanks go to Yizhe Zhang, Sungjin Lee, Dinghan Shen, and Wenlin Wang for their insightful discussion. The implementation in our experiments heavily depends on three NLP applications published on Github repositories; we acknowledge all the authors who made their code public, which tremendously accelerates our project progress.
The post Less pain, more gain: A simple method for VAE training with less of that KL-vanishing agony appeared first on Microsoft Research.