
This post has been republished via RSS; it originally appeared at: Skype for Business Blog articles.
First published on TECHNET on Aug 30, 2016by Steve Schiemann , UC Escalation Engineer – Microsoft
Reviewed by - Jason Epperly, Windows Escalation Engineer, Microsoft
Introduction
I am a Skype for Business Escalation Engineer. This means that I see some of the most interesting problems reported by customers. This is one of those issues that I just HAD to write about, because of the odd twists and turns encountered on the way to producing a fix. This is a high-level view of the issue, in that many technical details were left out. But I hope it leads to a better understanding of how a bug actually gets fixed through our internal processes, and why at times, it may seem like progress is not as fast as we (or customers) would like.
Scenario
One of Microsoft’s Premier customers created a support case, because several of the application pools on multiple Lync 2013 Front End Servers would crash several times per week, thus impacting service to end users. These affected processes included the DataMCUSvc, IMMCUSvc, ASMCUSvc, and also (less frequently) RtcHost.exe.
Data
The customer saw an event IDs 1000 and 1026 in quick succession in the application log, for example:
Time: 12/15/2015 2:13:57 AM
ID: 1000
Level: Error
Source: Application Error
Machine: Servername.domain.com
Message: Faulting application name: DataMCUSvc.exe, version: 5.0.8308.0, time stamp: 0x5050e3de
Faulting module name: mscorlib.ni.dll, version: 4.0.30319.36331, time stamp: 0x561e0e38
Exception code: 0xc0000005
Fault offset: 0x00000000005450d4
Faulting process id: 0x23d8
Faulting application start time: 0x01d1367cd6e190fb
Faulting application path: D:\Program Files\Microsoft Lync Server 2013\Web Conferencing\DataMCUSvc.exe
Faulting module path: C:\WINDOWS\assembly\NativeImages_v4.0.30319_64\mscorlib\322be87054b632752961a02ac84a27c7\mscorlib.ni.dll
Report Id: c99ad6ad-a303-11e5-80f9-005056a309a8
Time: 12/15/2015 2:13:57 AM
ID: 1026
Level: Error
Source: .NET Runtime
Machine: Servername.domain.com
Message: Application: DataMCUSvc.exe
Framework Version: v4.0.30319
Description: The process was terminated due to an unhandled exception.
Exception Info: System.NullReferenceException
Stack:
at System.Threading._IOCompletionCallback.PerformIOCompletionCallback(UInt32, UInt32, System.Threading.NativeOverlapped*)
User-mode memory dumps were also sent in, from the crashing processes. We had to use special syntax with procdump , to get the context of the crashes:
procdump -ma -e 1 -f NullReferenceException -accepteula DataMCUSvc.exe
This syntax allowed us to capture the dump at the time of the first-chance NullReferenceException, which correlates to the “Exception Info” from the event ID 1026.
Analysis and First-Chance Exception (mine)
I’m not going to go deeply into the analysis of the memory dumps, but here is the faulting call stack:
0:027> kcn
# Call Site
00 ntdll!ZwWaitForSingleObject
01 KERNELBASE!WaitForSingleObjectEx
02 clr!CLREventWaitHelper2
03 clr!CLREventWaitHelper
04 clr!CLREventBase::WaitEx
05 clr!Thread::WaitSuspendEventsHelper
06 clr!Thread::WaitSuspendEvents
07 clr!Thread::RareEnablePreemptiveGC
08 clr!Thread::EnablePreemptiveGC
09 clr!Thread::RareDisablePreemptiveGC
0a clr!Thread::DisablePreemptiveGC
0b clr!EEDbgInterfaceImpl::DisablePreemptiveGC
0c clr!GCHolderEEInterface<0,1,1>::LeaveInternal
0d clr!GCHolderEEInterface<0,1,1>::{dtor}
0e clr!Debugger::SendExceptionHelperAndBlock
0f clr!Debugger::SendExceptionEventsWorker
10 clr!Debugger::SendException
11 clr!Debugger::FirstChanceManagedException
12 clr!EEToDebuggerExceptionInterfaceWrapper::FirstChanceManagedException
13 clr!ExceptionTracker::ProcessManagedCallFrame
14 clr!ExceptionTracker::ProcessOSExceptionNotification
15 clr!ProcessCLRException
16 ntdll!RtlpExecuteHandlerForException
17 ntdll!RtlDispatchException
18 ntdll!KiUserExceptionDispatch
19 KERNELBASE!RaiseException
1a clr!NakedThrowHelper2
1b clr!NakedThrowHelper_RspAligned
1c clr!zzz_AsmCodeRange_End
1d mscorlib_ni!System.Threading._IOCompletionCallback.PerformIOCompletionCallback(UInt32, UInt32, System.Threading.NativeOverlapped*)
1e clr!CallDescrWorkerInternal
1f clr!CallDescrWorkerWithHandler
20 clr!DispatchCallSimple
21 clr!BindIoCompletionCallBack_Worker
22 clr!ManagedThreadBase_DispatchInner
23 clr!ManagedThreadBase_DispatchMiddle
24 clr!ManagedThreadBase_DispatchOuter
25 clr!ManagedThreadBase_FullTransitionWithAD
26 clr!ManagedThreadBase::ThreadPool
27 clr!BindIoCompletionCallbackStubEx
28 clr!BindIoCompletionCallbackStub
29 clr!ThreadpoolMgr::CompletionPortThreadStart
2a clr!Thread::intermediateThreadProc
2b kernel32!BaseThreadInitThunk
2c ntdll!RtlUserThreadStart
Based on dump analysis, the root cause was far from clear, but it seemed that the problem was with the Common Language Runtime (CLR). There isn’t even a Lync Server module present in this stack! The issue continued even after the customer updated to the latest .NET patches. I mean, the event IDs above pointed to a .NET problem. I could also see an error code associated with the first chance exception: E0434F4DSystem.NullReferenceException
Looking this error code up with err.exe :
0x80131506 (2148734214): COR_E_EXECUTIONENGINE - corerror.h: An internal error happened in the Common Language Runtime's Execution Engine
OK, this is a .NET bug! Microsoft Customer Service and Support (CSS) has specialists for just about every product we produce, so I engaged the .NET team for input. Now I can just let them do the heavy lifting and fix their component! Wrong.
The .Net team found no issue with their product. As a matter of fact, they said that this was clearly a Lync Server issue. Lync Server code has not properly synchronized the access to the OVERLAP structure, perhaps double-freeing the NativeOverlapped object. Nothing to see here, move along. Rats!
Next Step
After extensive debugging by myself and the .NET team, there was still no clear cause for the crashes, and no resolution for the customer. So, I engaged the Skype for Business (SfB, formerly Lync) product group (PG) by opening a bug. I stated the symptoms, analysis done so far by all parties, and the .NET team’s suspicions that this was not their problem, but ours.
Fortunately, one of our excellent SfB developers had spent some time developing/debugging core Windows applications. He was able to identify the issue, even without a kernel dump. He had seen it before with a different Lync Server issue . In that case, the PG was able to code around the problem even though it was not truly a Skype for Business problem. With these app pool crashes, the fix had to come from the source component, which was NOT part of Lync Server code.
Root Cause at Last!
This was a Windows problem, that bubbled up through .NET and hit Lync Servers. Short story, the Windows I/O Manager, starting with Vista, has the ability to use thread agnostic I/O . This means that the original thread which issued the I/O no longer has to be present when the I/O it issues completes. In our case, the FO_QUEUE_IRP_TO_THREAD flag on the FILE_OBJECT structure effectively disables this feature, and queues the I/O Request Packet (IRP) to the issuing thread. The status code returned to the issuing thread by CloseHandle was incorrect; the code returned was STATUS_BUFFER_OVERFLOW, rather than STATUS_PENDING. This caused processes on Lync Servers to see unexpected double completions, which resulted in the crashes.
The Road to Releasing a Fix
So, now that the root cause was understood, it was time to engage our Windows support team, and ask them to open a bug with THEIR product group, and get this fixed. I did this, and based on the strong Business Impact Statement (BIS) from my customer, and the fact that several more cases had been opened for this issue, a bug was filed, and the Windows PG agreed to fix this. Yay! Not so fast…first, the problem was also in the next Windows Server version (2016), that wasn’t even released yet. The fix had to be “baked” or tested in our internal labs on Server 2016 for several weeks, and if all went well, backported to Server 2012 R2. The Lync 2013 Server crash cases that had come in were all running this version.
Unfortunately, the first version of the fix did not fully resolve the issue, so the stress tests on Server 2016 had to be restarted, and run again. This time, there was no issue with the fix, and it was backported to Server 2012 R2.
Finding the Fix
It is within this rollup:
3179574 August 2016 update rollup for Windows RT 8.1, Windows 8.1, and Windows Server 2012 R2
http://support.microsoft.com/kb/3179574/EN-US
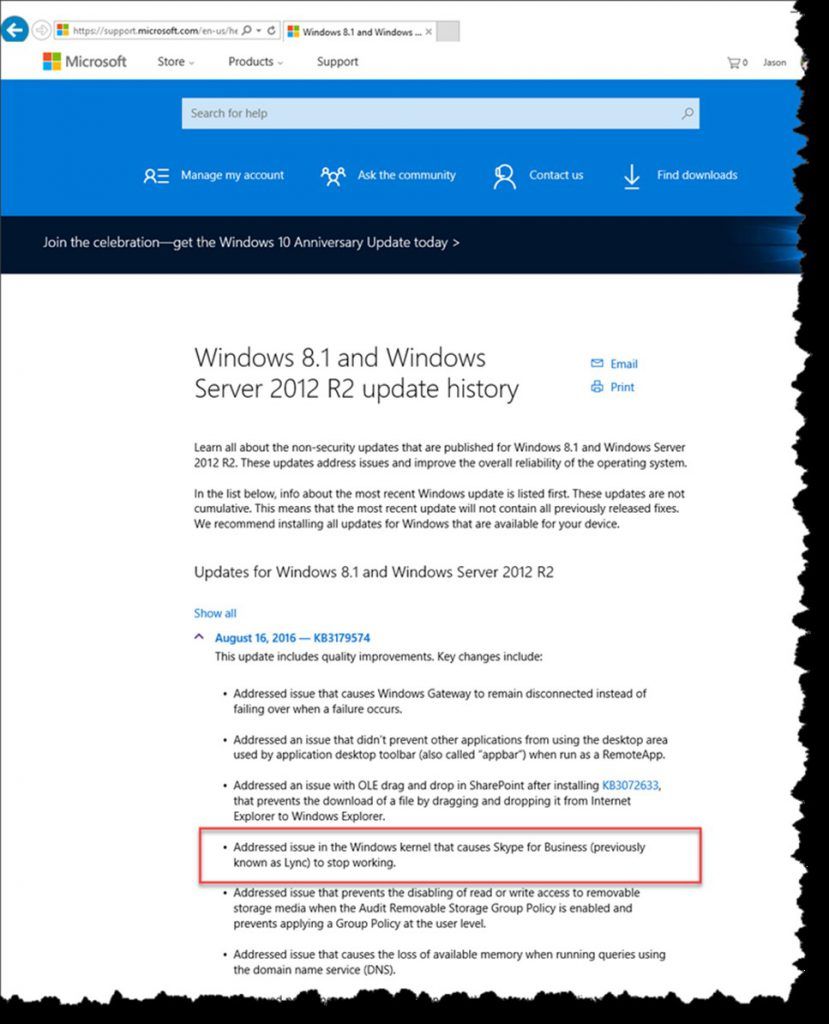
You can verify that it is installed by looking for KB3179574 in add/remove programs. There is no individual KB for the issue at this time, but it is listed as one of the fixes in the rollup see below.
At Last
The whole process, from the opening the first case, to the release of a public fix, took almost a year. During this time, several support teams and product groups were involved, customers went on vacation, private versions of the fix were tested by various customers, and internal tests failed. But finally, a solid fix is publicly available and this problem should not be seen anymore. We strive daily to make our products better, and need to improve our processes so that customers see resolution to similar issues more quickly. I hope this article gives some insight as to what goes on when a code change is needed in a product- sometimes the product that exhibits the symptom is not really at fault.
Why did this problem affect Lync 2013 Front-End (FE) servers exclusively? Well, these FE servers use the .NET HTTP Listener API to asynchronously retrieve a client certificate. Our certificates tend to be rather large, and do not fit into the default buffer. This results in the asynchronous completion returning STATUS_BUFFER_OVERFLOW. When STATUS_BUFFER_OVERFLOW is returned to the caller, it expects no asynchronous completion. The fix was to return STATUS_PENDING instead.