
This post has been republished via RSS; it originally appeared at: Microsoft Research.

Have you ever wondered what happens when you ask a search engine to search for something as seemingly simple as “how do you grill salmon”? Have you found yourself entering multiple searches before arriving at a webpage with a satisfying answer? Perhaps it was only after finally entering “how to cook salmon on a grill” that you found the webpage you wanted in the first place, leaving you wishing search engines simply had the intelligence to understand that when you entered your initial search, your intent was to cook the salmon on a grill.
Microsoft has taken a step toward providing a deeper understanding of web search queries with Microsoft Generic Intent Encoder, or MS GEN Encoder, for short. The neural network maps queries with similar click results to similar representations, enabling it to capture what people expect to see and want to click as a result of a specific search as opposed to just a query’s semantic meaning. With this technology, search engines won’t only recognize that “how do you grill salmon” and “how to cook salmon on a grill” are the same, but also understand that while you may enter “miller brain disease,” results for “miller syndrome lissencephaly” would be equally relevant.
MS GEN Encoder, which was trained on hundreds of millions of Bing web searches, is currently being used in the Microsoft search engine, and we’re thrilled to announce that we’re making the functionality of the technology available to academic researchers as an Azure service. We hope such access, which is being overseen by program manager Maria Kang and software engineer Zhengzhu Feng, will help accelerate research in the academic community by allowing researchers to tap into the power of users’ behavioral data provided by the large-scale search logs MS GEN Encoder leverages.

In weak supervision, if two queries in the logs result in the same document, they’re considered to have the same or similar intent. This may not always be true, which is why it’s a “weak” label.
MS GEN Encoder and the challenge of intent
Understanding web search intent—what people want to see and will click on—requires a deep knowledge of both web content and a person’s informational needs based on their search. In particular, a person may choose a phrase like the above’s “miller brain disease” to find information on the condition, while the author of a webpage may use the expression “miller syndrome lissencephaly.” This “vocabulary mismatch” problem—first identified and described by Microsoft Technical Fellow Deputy Managing Director Susan Dumais and her colleagues in the 1980s, prior to Dumais joining Microsoft—is due primarily to the high variability and flexibility language provides us to say the same thing in many different ways.
To help overcome this and other semantic challenges, we and co-authors Hongfei Zhang, Xia Song, Nick Craswell, and Saurabh Tiwary turned to deep learning methods to train MS GEN Encoder to specifically identify the intent behind language used in search queries and learn a representation of each query such that similar intents are mapped to similar embeddings.
A two-phase training strategy
To appropriately model search intent, we deploy a two-phase training strategy. In the first phase—weak supervision—we leverage large-scale click signals in Bing search logs as an approximation of a person’s search intent and train a recurrent neural network model to map search queries clicking on the same URLs close in the embedding space. For example, different search queries that result in the selection of the same URLs are interpreted as likely looking for the same results despite differences in word choice and mapped closer together. This type of weak supervision reduces the need for manual labeling and is useful for learning a very rich model from data available at scale—the type of interaction data we have in abundance from Bing search logs and which doesn’t contain people’s personal data.
In the second phase of training, manually labeled data is introduced in a multi-task learning setting to extend the generalization ability of MS GEN Encoder to unseen search queries. In this phase, the encoder is trained on datasets with query or question pairs manually labeled by human annotators as having or not having similar search intents. These additional tasks both steer the model to greater generalization and help provide human oversight on the semantics encoded by the neural network.

MS GEN Encoder’s recurrent neural network architecture uses a hybrid character and word embedding to address never-before-seen search terms, whether they be a result of a misspelling, new concepts, or words borrowed from a different language.
Alleviating tail sparsity
The power of the model lies in how it handles very rare, or tail, search queries. Search engines encounter a large number of queries that either are searched infrequently or have never been searched at all because of the variety in language, misspelled words, rare concept names, product IDs, new trending topics, and ever-evolving words borrowed from different languages. This is a phenomenon known as a long tail distribution, and it can lead to poor search results.
To handle terms that haven’t been seen before in the model’s training data, we designed a new recurrent neural network architecture that uses a hybrid character and word embedding as the first layer within a more common multilayer sequential modeling architecture. This hybrid embedding gives the model flexibility to manage language variations and unseen terms. For example, the misspelled word “restarant” and the word “restaurant” are mapped to similar embeddings by MS GEN Encoder, as they share similar character sequences and also lead to clicks on similar web content.
MS GEN Encoder proved capable of addressing the long tail sparsity challenge with high precision. In our study, we first removed navigational queries, adult queries, and very common queries for all of the following analysis. From a six-month period, we collected a uniform sample of 700 million queries, then collected a set of 1 million queries sampled immediately after. In the sample of 1 million queries, we defined those queries that had less than 16 occurrences in the larger set to be tail-ish. In fact, 39 percent of the 1 million queries were so tail-ish they had never been seen at all in the historical set. However, “expanding” the unseen queries with their approximate nearest neighbors reduced the number of unseen searches to only 20 percent by matching unseen searches to historical searches with very similar MS GEN encodings.
Bonus capability—identifying higher-level search goals
While MS GEN Encoder was trained to map search queries with the same intent into similar representations, an unplanned—and interesting—capability arose: MS GEN Encoder naturally reflects different categories of search behaviors based on how similar the embeddings of two queries are.
In the table below, each row includes two search queries from the same person; the query in the second column was entered shortly after the first. In the second pair of queries, the individual clearly entered a different but related term, both falling under the larger topic of Revolutionary War battles. This relationship is identified despite the typo “2776” instead of “1776.” In this case, the person was likely in a “learning mode,” seeking to gain a broad understanding of the topic. The third pair of queries indicates the individual was looking for more specific information, while the fourth pair demonstrates a reformulation with the same intent. MS GEN Encoder is able to quantify these relationships to get a sense of people’s search behavior. Such insights can help improve downstream tasks such as ranking and query suggestion.
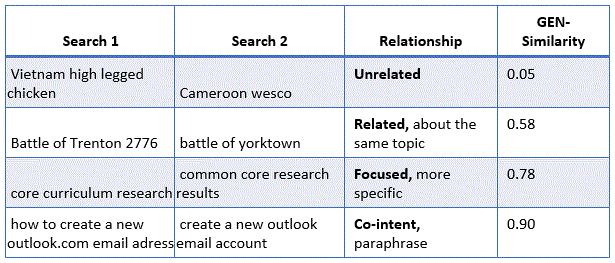
MS GEN Encoder can help categorize search query pairs to see where people are going in their search sessions. For instance, if a person is asking about different battles in the Revolutionary War, then his or her trajectory is lateral within that topic.
The work behind MS GEN Encoder is further detailed in our paper “Generic Intent Representation in Web Search,” which we’re presenting at the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval. We encourage readers to check it out, and if you’re an academic researcher, we invite you to take the next steps in trying out MS GEN Encoder, which you can do using the Microsoft Machine Reading Comprehension, or MS MARCO, dataset. We’ve already started onboarding a few universities from the United States and Australia and are excited to see what findings come out of these research studies.
The post Learning web search intent representations from massive web search logs appeared first on Microsoft Research.