
This post has been republished via RSS; it originally appeared at: Microsoft Research.
One of the core directions of Project Malmo is to develop AI capable of rich interactions. Whether that means learning new skills to apply to challenging problems, understanding complex environments, or knowing when to enlist the help of humans, reinforcement learning (RL) is a core enabling technology for building these types of AI. In order to perform RL well, agents need to do exploration efficiently, which means understanding when to try new things out and how to assess future outcomes.
Similar to the human experience of exploration, exploration in RL means taking calculated risks—involving a balance somewhere between overestimating and underestimating potential outcomes. Current RL methods have difficulty achieving sample efficiency, which means they need millions of environmental interactions to learn a policy. In particular, modern actor-critic methods present some challenges that need to be addressed.
In our paper accepted at the thirty-third Conference on Neural Information Processing Systems (NeurIPS 2019), “Better Exploration with Optimistic Actor Critic,” Kamil Ciosek (Microsoft Research Cambridge), together with summer Microsoft Research intern Quan Vuong (University of California, San Diego), as well as Robert Loftin and Katja Hofmann (Microsoft Research Cambridge), present a new actor-critic algorithm that uses an upper bound on the critic to mitigate the problems caused by greedy exploration in RL, leading to more efficient learning.
Modern actor-critic methods use an approximate lower bound to estimate the critic
Actor-critic methods in RL use two components: actor and critic. The policy is represented by a neural network called an actor. In order to obtain updates to the actor, we need to compute a critic. One problem is that, in practice, the critic is a neural network trained on a small amount of off-policy data and is often simply wrong. Since the consequences of underestimating the true critic value are easier to bear than overestimating it, the usual fix is to use an approximate lower bound of the critic. In practice, modern actor-critic methods just estimate the critic twice and take the minimum of the two whenever a value is needed.
Actor-critic methods use the actor for two purposes—it represents both the current best guess of the optimal policy and is used for exploration. Here lies another problem: greed is bad, as it again turns out. For exploration, using an update that greedily maximizes the lower bound turns out to be a really inefficient and inaccurate method. In our paper, we explore two reasons why this happens: pessimistic underexploration and directional uninformedness.
Understanding the problems with using greedy exploration

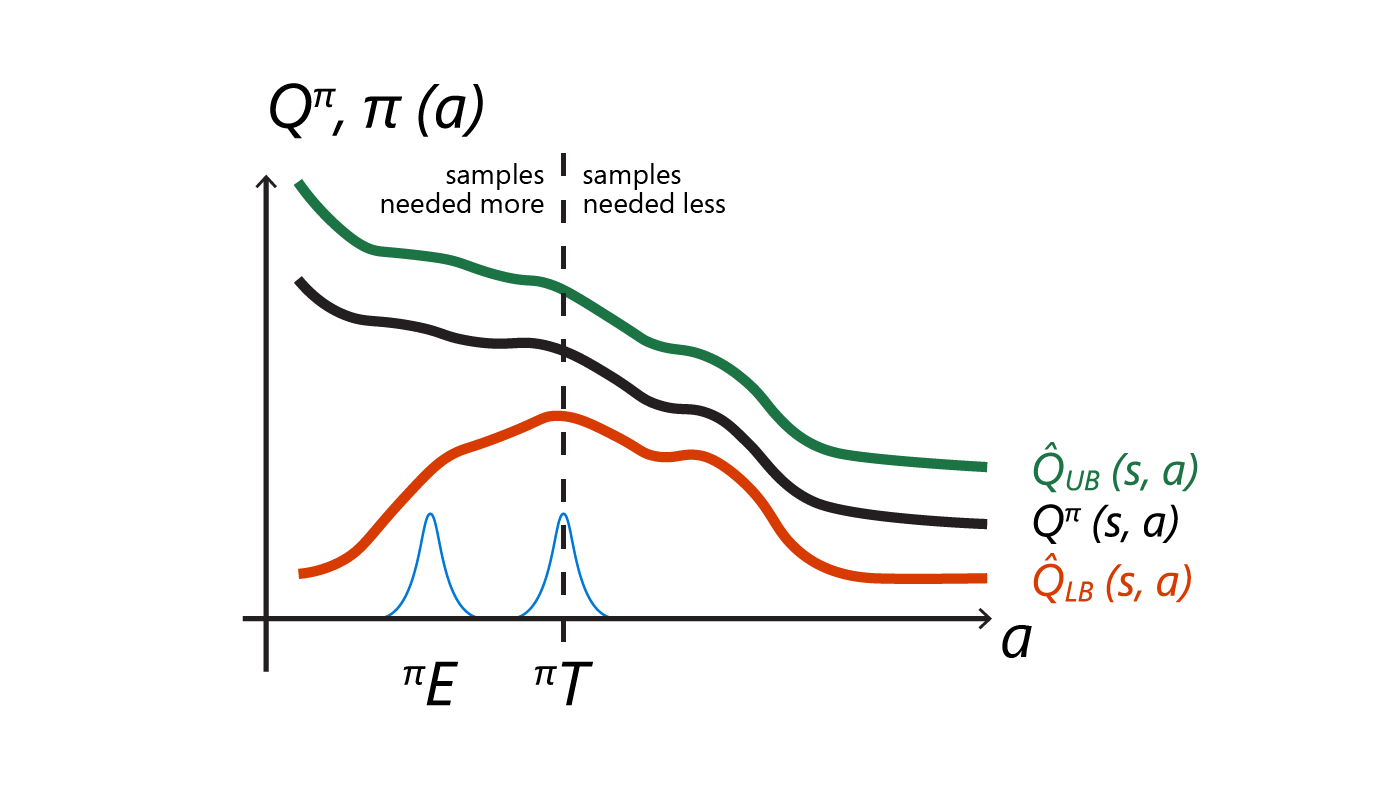
Figure 1: Pessimistic underexploration and directional uninformedness are two key reasons why greedy exploration falls short.
Pessimistic underexploration is shown in Figure 1a. By greedily maximizing the lower bound, the policy becomes very concentrated near a maximum. When the critic is inaccurate, the maximum is often spurious. In other words, the true critic, represented with a black line in Figure 1a, does not have a maximum at the same point.
This can be very harmful. At first, the agent explores with a broad policy, denoted as πpast. Since the lower bound increases to the left, the policy gradually moves in that direction, becoming πcurrent. Because the lower bound (shown in red) has a maximum at the mean of πcurrent, the policy πcurrent has a small standard deviation. This is not optimal since we need to sample actions from the far left-hand area to discover the mismatch between the critic lower bound and the critic.
Directional uninformedness is shown in Figure 1b. For efficiency reasons, most actor-critic models for continuous action spaces use Gaussian policies. This means that actions in opposite directions from the mean are sampled with equal probability. However, in a policy gradient algorithm, the current policy will have been obtained by incremental updates, which means that it won’t be very different from recent past policies.
Therefore, exploration in both directions is wasteful since the parts of the action space where past policies had high density are likely to have already been explored. This phenomenon is shown in Figure 1b. Since the policy πcurrent is Gaussian and symmetric around the mean, it is equally likely to sample actions to the left and to the right. However, while sampling to the left would be useful for learning an improved critic, sampling to the right is wasteful since the critic estimate in that part of the action space is already good enough.
Optimistic Actor Critic explores better with the upper bound
Optimistic Actor Critic (OAC) makes use of the principle of optimism in the face of uncertainty, optimizing an upper bound rather than a lower bound to obtain the exploration policy. Formally, the exploration policy is defined by the formula below. 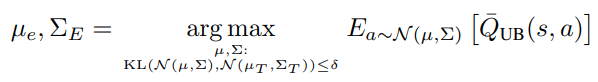 The upper bound used in the paper is obtained from two bootstraps over the Q-function. Stability is ensured by enforcing the closeness between the exploration policy and the target policy. In the formula above, this is done using the KL constraint. Despite using off-policy exploration, OAC achieves the same level of stability as other modern actor-critic methods.
The upper bound used in the paper is obtained from two bootstraps over the Q-function. Stability is ensured by enforcing the closeness between the exploration policy and the target policy. In the formula above, this is done using the KL constraint. Despite using off-policy exploration, OAC achieves the same level of stability as other modern actor-critic methods.
OAC addresses the two problems of pessimistic underexploration and directional uninformedness we have identified above. Since the policy πE is far from the spurious maximum of the lower bound (red line in Figure 2), executing actions sampled from πE leads to a quick correction to the critic estimate. This way, OAC avoids pessimistic underexploration. Since πE is not symmetric with respect to the mean of πT (dashed line), OAC also avoids directional uninformedness.

Figure 2: The OAC exploration policy πE avoids pessimistic underexploration by sampling far from the spurious maximum of the lower bound. Since πE is not symmetric with regard to the mean of the target policy (dashed line), it also addresses directional uninformedness.
Integrating optimism into deep reinforcement learning often fails due to catastrophic overestimation. While OAC is an optimistic algorithm, it does not suffer from this problem. This is because OAC uses the optimistic value estimate for exploration only. The policy πE is computed from scratch every time the algorithm takes an action and is used only for exploration. The critic and actor updates are still performed with a lower bound. This means that there is no way the upper bound can influence the critic except indirectly through the distribution of state-action pairs in the memory buffer.
We evaluated OAC on MuJoCo continuous control tasks. In the plot below, we show that OAC outperformed SAC on the Humanoid task. We stress that optimistic exploration as performed by OAC is computationally cheap – we only need to compute one extra critic gradient per sample.

Figure 3: Performance comparison of OAC versus SAC.
Ultimately, optimistic exploration is simple to implement. By using the upper bound instead of the lower bound to estimate the exploration policy, OAC increases efficiency and accuracy when compared with other methods of exploration. You can find more in-depth information about the technology in our paper, including information about ablations and other experiments. To learn more about our research in Game Intelligence at Microsoft Research Cambridge, check out our page.
If you will be attending NeurIPS 2019, our paper will be featured as a spotlight during Track 3 Session 2, which runs from 4:00 PM PST to 5:30 PM PST on Tuesday, December 10th. We will also have a poster in the East Exhibition Hall B + C, from 5:30 PM PST to 7:30 PM PST on Tuesday, December 10th. Come find out more about our work there!
The post Optimistic Actor Critic avoids the pitfalls of greedy exploration in reinforcement learning appeared first on Microsoft Research.