
This post has been republished via RSS; it originally appeared at: Microsoft Developer Blogs - Feed.
Versions 16.3 and 16.4 of Visual Studio 2019 brought many new improvements in code generation quality, build throughput, and security. If you still haven’t downloaded your copy, here is a brief overview of what you’ve been missing out on.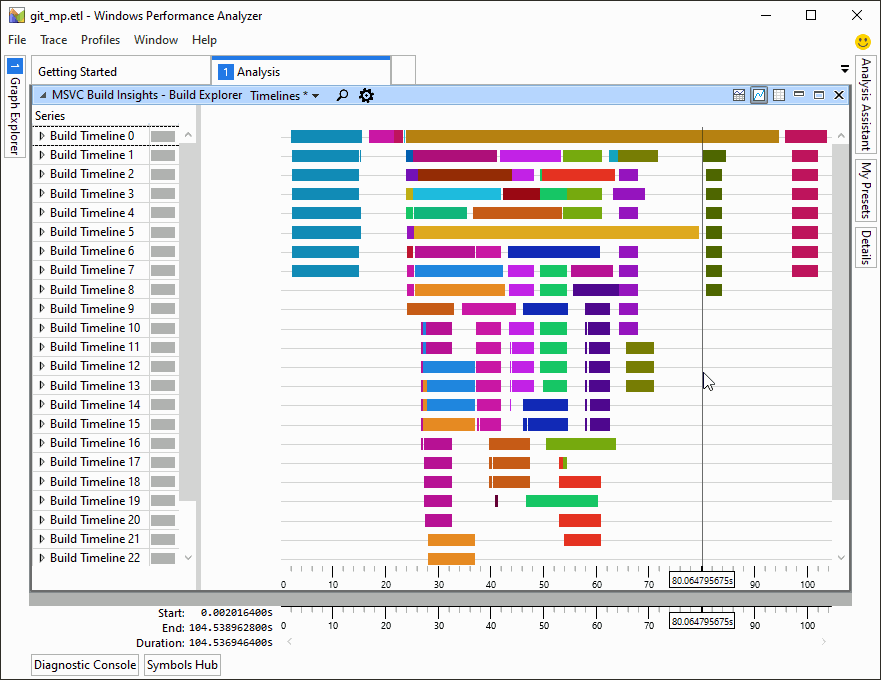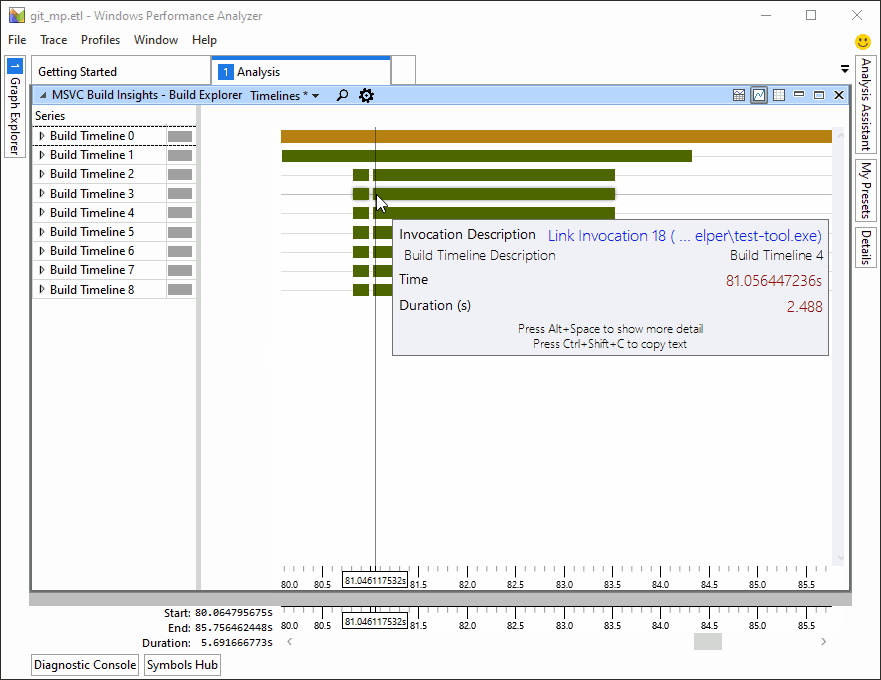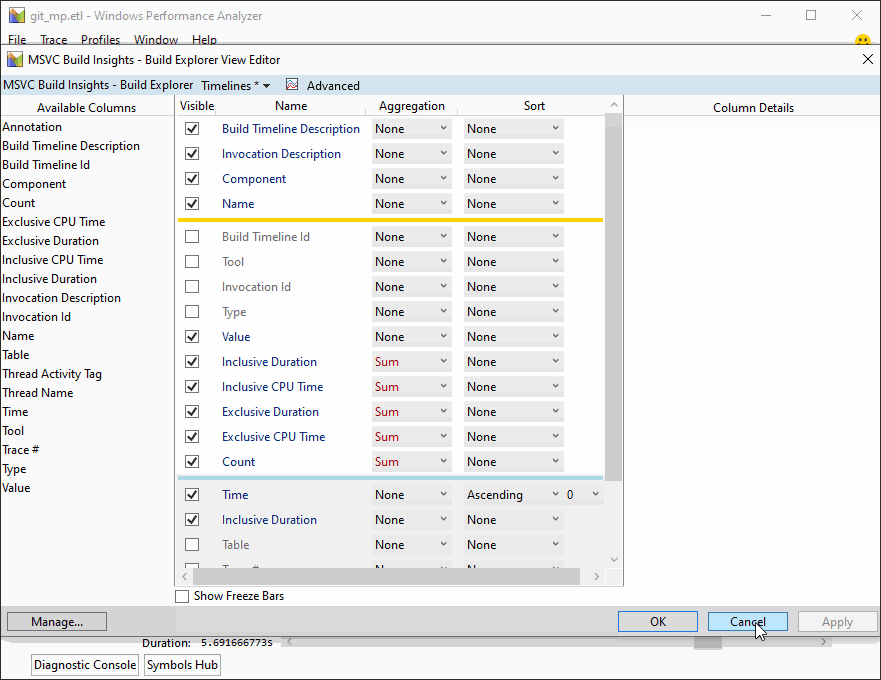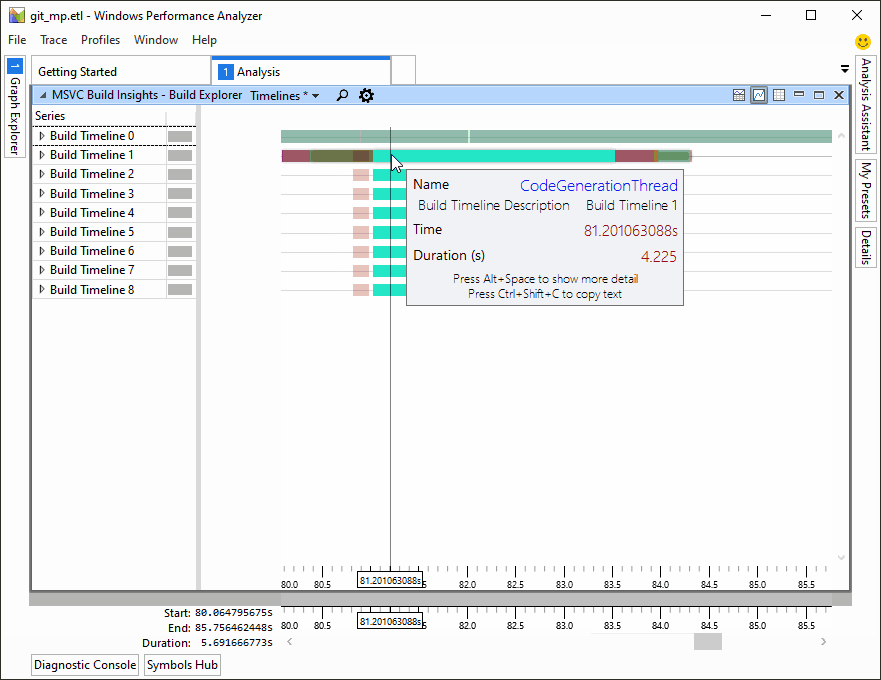 Demonstration of C++ Build Insights, a new set of build analysis tools in Visual Studio 2019 version 16.4.
Demonstration of C++ Build Insights, a new set of build analysis tools in Visual Studio 2019 version 16.4.
Visual Studio 2019 version 16.3
- AVX-512 auto vectorizer support under the /arch:AVX512 switch, enabling logical, arithmetic, memory, and reduction vector operations targeting the AVX-512 instruction set.
- Enhancements to the general inliner by estimating the values of both variables and memory. Enabled under /Ob3.
- Improvements to inlining of small functions for faster build times and smarter inlining.
- Partial ability to inline through indirect function calls
- Dataflow-driven alias package added to the SSA Optimizer, enabling more powerful SSA-based optimizations
- Improvements to the common sub-expression (CSE) optimization focused on eliminating more memory loads.
- Compile-time computation of spaceship operator comparisons on string literals.
- Automatic conversion of fma, fmal, fmaf, and std::fma to the intrinsic FMA implementation, when supported.
- Optimized code generation when returning register-sized structs by using bit manipulations on registers instead of memory operations.
- __iso_volatile_loadxx and __iso_volatile_storexx functions, which allow direct atomic read and write of aligned integer values.
- Intrinsic versions of most AVX-512 functions that were previously implemented as macros.
- Improvements to instruction selection for mm_shuffle and _mm_setps intrinsics under /arch:AVX2.
- Enabling of FrameHandler4 (FH4) by default for the AMD64 platform.
Visual Studio 2019 version 16.4
- Support for AddressSanitizer (ASAN), allowing the detection of memory safety issues at runtime.
- C++ Build Insights, a new collection of tools for understanding and improving build times.
- Significant improvements to code generation time by using up to 24 threads instead of 4, depending on available CPU cores.
- Further improvements to code generation time through better algorithms and data structures used by the compiler.
- Introduction of a new /d2ReducedOptimizeHugeFunctions compiler option to improve the code generation time by omitting expensive optimizations for functions with more than 20,000 instructions. This threshold can be customized by using the /d2ReducedOptimizeThreshold:# switch.
- Improvements to the AVX-512 auto vectorizer, supporting more instruction forms: variable width compares, int32 multiplication, int-to-fp floating point conversion. Available under /arch:AVX512.
- Improved analysis of control flow to better determine when values are provably positive or negative.
- Enabling of the enhanced inliner introduced in 16.3 by default, without the use of /Ob3.
- Intrinsic support for the ENQCMD and ENQCMDS instructions, which write commands to enqueue registers.
- Intrinsic support for the RDPKRU and WRPKRU instructions, which read and write the PKRU register available in some Intel processors.
- Intrinsic support for the VP2INTERSECTD and VP2INTERSECTQ instructions, which generate a pair of masks indicating which elements of one vector match elements of another vector.