
This post has been republished via RSS; it originally appeared at: Microsoft Research.

In the digital era, almost everyone struggles with the mountains of information they have. Every activity in our lives seemingly generates more information: emails, files, receipts, photos—the list goes on. We have trails of digital information from each of our work projects, vacations, hobbies, and kids’ schools, including websites, files, and calendar appointments, not to mention contacts—the people we work, play, and live with in each of these spaces. We spend a significant amount of time figuring out when to share something with them, when to ask them for something, and where to find information they might have already sent us. Don’t you wish there were a way to automatically and effortlessly organize everything? To have search as simple as people’s associative memory—the minute you start looking at one item all of the related information you need is magically at your fingertips?
This is just the problem we set out to solve with University of Michigan PhD student Tara Safavi, our Microsoft product partners and research colleagues, and Safavi’s PhD adviser.
To make the challenge more amenable to algorithmic analysis, we view all the information people interact with as a personal web of entities surrounding them. Just like the information on the World Wide Web, these entities—contacts, projects, files, emails, and other digital information—can be thought of as nodes in a graph connected through how they interact by edges. For example, a project may have different project members, a file may have different authors or readers, and an email has senders and recipients. In addition to proposing a graph-based approach to personal information, we also introduce novel computationally efficient techniques for updating how information propagates through a graph as the graph evolves with new edges, nodes, and information. Safavi will be presenting the paper on this work, “Toward Activity Discovery in the Personal Web,” at the 13th ACM International Conference on Web Search and Data Mining.
The case for graph connections and how to make them
While we envision this graph-based approach as a solution for organizing all aspects of one’s life, in our study, we applied it to people’s personal web at work—the emails, documents, and contacts individuals access in their professional lives. You might be wondering why graph connections are needed at all when many digital entities have content. Looking at people, or contacts, provides one clear reason. By simply viewing personal information entities as a graph and looking at the number of connections each type has, it’s clear that contacts are the hubs of personal webs.

Looking at the distribution of a random inbox from the Avocado email dataset where the number of entities are on the vertical axis and the given number of connections, or node degrees, are on the horizontal axis, you can see there are far more emails than files, but both emails and files have relatively few connections—typically only a couple and almost all less than 10. In contrast, people are really the entities that connect our whole personal web. While this may vary across personal webs, this is expected to be a common trend.
While emails and files have content, contacts have little to no content descriptions. A graph-based approach allows us to link information through all of the connections, providing a much richer basis for identifying when two items in our personal webs with little content in common are highly related and possibly needed in conjunction for the same task.
The key challenge becomes automatically computing relatedness between any two entities in this graph. A simple approach would be to compute their similarity based on attributes of the entities. These attributes can come from metadata. They can also come from content within the entity, such as from the text of a file, the body of an email, or a person’s shared profile using a basic bag-of-words approach or sophisticated techniques like latent semantic analysis. This gives rise to an initial attribute vector representation, which we refer to as the entity’s self-representation. However, this self-representation doesn’t consider the underlying graph structure and what we know about how entities are related. We would like to estimate each entity’s full representation in a way that satisfies two competing ideals:
- An entity’s full representation should be similar to its self-representation considered independently from graph connections.
- An entity’s full representation should be similar to the full representation of entities in the graph to which the entity is connected.
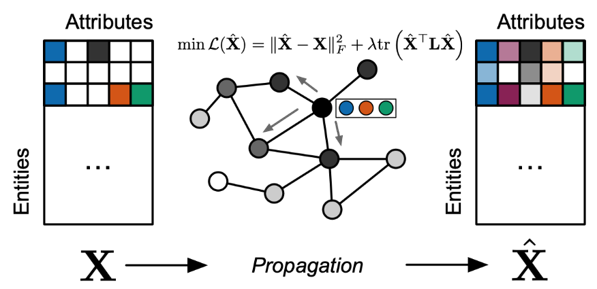
To make algorithmic analysis easier, researchers view individual’s collection of digital information—emails, files, contacts and the like—as a personal web that can be treated as a graph with nodes and edges. To obtain meaningful representations of the information across a personal web, researchers created a loss function that captures information’s representation separate of the graph and its representation in relation to the other entities in the graph.
Propagating information in a graph like this is sometimes called diffusion, or graph propagation. The competing ideals are captured in a loss function. In our study, we chose to minimize one loss that captures this tradeoff:
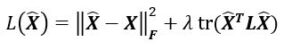
The first term, ||\(\hat{X}\)–X||F2 penalizes deviations from our first ideal, while tr(\(\hat{X}\)TL\(\hat{X}\)) penalizes deviations from the second. \(X\) contains the self-representations of all entities, \(\hat{X}\) contains the full representations we wish to estimate as the result of propagating information on the graph, and the graph Laplacian \(L\) is a simple representation of graph structure as a matrix λ is a parameter that enables one to tune the tradeoff).
Graph propagation has been studied in other settings before. While computing the optimal full representation that minimizes the loss above involves the inversion of a very large matrix, which is typically costly, relatively efficient techniques have been identified to handle this challenge for scenarios with structure like ours. For example, using Jacobi iteration with a fixed number of iterations, \(\hat{X}\) can be found in O(mp) time where m is the number of edges in the graph and p is the number of attributes. Note that if like most real-world graphs, the graph has relatively few edges on average per node—that is, it is sparse—and there are n nodes, then n < m << n 2 , so this solution is much quicker than naïve matrix inversion.
However, the efficiency of Jacobi iteration for scenarios like ours was known before. The real challenge is that the entities and connections in our personal webs are constantly evolving—new emails arrive, files are shared for the first time, people join new projects. While computing the optimal \(\hat{X}\) for a large graph is feasible, doing it for every update to one’s personal web is prohibitively computationally costly. One solution is only updating \(\hat{X}\) occasionally, but we demonstrate such occasional “batch updates” lead to poor estimates of relatedness relative to an up-to-date \(\hat{X}\) that is updated “online,” meaning every time the graph changes.
Keeping up with an ever-evolving personal web
In our paper, we found a much faster approach for the online setting by writing the optimal new estimate after a graph change as a simple addition of the optimal estimate before the graph update and the update, Δ X:
![]()
The key here is Δ X can be computed more efficiently than solving for \(\hat{X}\)NEW from scratch. By only computing what changes, we can build on our solution prior to the update and save a ton of computational work.
Consider the case in which a new edge is added between existing entities with no new attributes. After some derivation, we show that the changes can be expressed as the outer product of two vectors, u and v T. If we can compute u and v quickly, then we’re set. It turns out u can be computed in a manner that is similar to the full matrix solution using Jacobi iteration, but this time, we only need to do Jacobi iteration for a column vector instead of for every attribute in existence! Likewise v can also be computed relatively efficiently—the dominating factor is a matrix multiplication of \(\hat{X}\), which is O(np).
Adding new attributes to an existing entity would mean simply propagating each attribute over the graph, which can be done by applying Jacobi iteration to each attribute independently since the edges have not changed. Adding an entity without any edges—with or without new attributes—is trivially initialized to its self-representation since it’s disconnected. All other cases can be solved with some ordering of these three cases.
Let’s expand on the interpretation of u and v . U is a column vector with n entries, one for each entity. Each entry of u , u[i], indicates how the update to entity i’s representation will be scaled. V is a column vector with p entries, one for each attribute, and represents what information will be updated for every entity. Then for each entity i, v is scaled by -u[i] and added to the current representation of the entity.
For a single entity, \(\hat{X}\)NEW[i:] – u[i]. v can be thought of as what information will flow through the new edge, and u represents how to scale the impact once it reaches the entity through graph propagation.
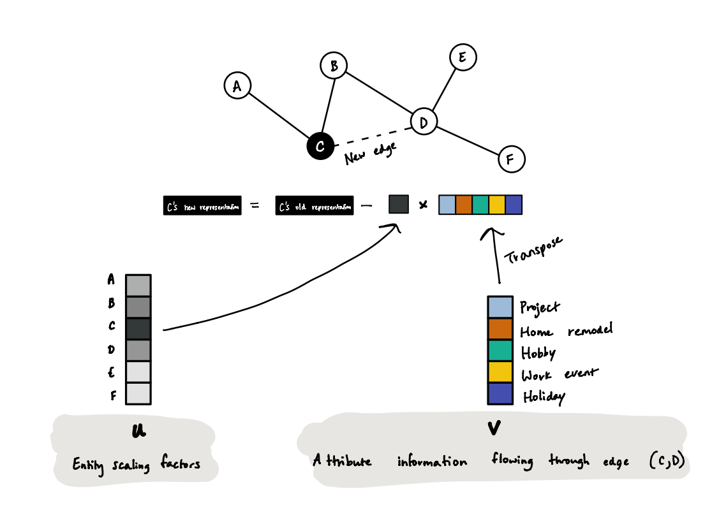
This information update shows v flowing over a new edge, linking entities C and D. The update is scaled by the corresponding factor in u.
In the above figure, we visualize the update that happens when we have five attributes—“project,” “home remodel,” “hobby,” “work event,” and “holiday”—and a new edge in our graph causes us to propagate information in the graph. The darker the color of the cell for an entity in u , which tends to correlate with how close the node is in the graph to the new edge, the more that v will contribute to the updated representation of the entity.
Intrinsic evaluation
In addition to providing a very computationally efficient way to compute representations over a personal web, we also performed a study designed to preserve the privacy of those who volunteered to participate while allowing us to gather anonymized feedback. During the process, we provided participants with an application to compute relatedness over their own personal data using our approach and several baselines, and they judged the degree to which they thought the entities were related and provided us with that feedback.
This type of measurement is called an intrinsic evaluation because the goal is to measure the quality of the representation in isolation and without considering tasks it may be used for later, like search or recommendation. Researchers have done intrinsic evaluations of language embeddings, but we believe this is the first time that anyone has reported intrinsic evaluations on representations over graphs, as well as over a personal web. We compared our graph-based approach to a variety of simple baselines, such as overlap in people, and more state-of-the-art baselines, like node2vec, and found our method produced representations in which two entities similar in representation were more likely to be related as judged by the people whose personal web the algorithm was running on.
We also did extrinsic evaluation in which the representations were used for a downstream task and found both major speedups in computation and improvement in downstream prediction quality. In the extrinsic evaluation, we vary λ, which controls the weight we give to the entity’s self-representation versus the information propagated in the graph. Interestingly, the optimal value fell in the middle and not at either extreme, justifying our assumptions that both the self-representation and graph structure can contribute to how we make sense of our personal webs.
We view this work as one significant step toward automatically capturing a notion of relatedness that will be useful to people over a variety of search and recommendation tasks, helping them to find all of the related information they need, recommending items they may have forgotten as relevant, and making connections between people who work on similar topics. Combined, this support can help people make sense of their personal webs and accomplish their goals more efficiently.
This work was spearheaded by University of Michigan PhD student Tara Safavi during a research internship at Microsoft. University of Michigan professor Danai Koutra and Microsoft researchers Adam Fourney, Robert Sim, Marcin Juraszek, Shane Williams, Ned Friend, and Paul N. Bennett served as advisers on the work.
The post The personal web: Connecting information for better search and recommendation appeared first on Microsoft Research.