
This post has been republished via RSS; it originally appeared at: Microsoft Research.
A new document in a word processor can be a magical thing, a blank page onto which thoughts and ideas are put forth as quickly as we can input text. We can select words and phrases to underline and highlight and add images, shapes, and bulleted lists, and when we need editorial help, we can run a grammar and spell checker. The experience can feel so seamless at times that perhaps we don’t give much thought to how it all works.
Behind the scenes are many modules, individual components tasked with each of those specific actions and many others, all working together to make the entire system function. A change in one can have significant impact on overall system performance, which is why a whole team of engineers can be responsible for working out the specific configurations of a single module. The spell-checker module, for example, can have multiple configurations, including a lightweight version and a heavyweight version. The lightweight spell checker, designed for small compute environments like our phones, gives up accuracy in return for speed; the heavyweight spell checker is very accurate, but slower, requiring more compute, like that offered by laptop and desktop environments.
It would make sense to always use the lightweight spell checker when running the word processor in small-compute environments and the heavyweight spell checker when there’s more available compute. For the most part, that’s how software configuration is done today—through trial and error, a configuration is determined based on a target environment and is then held constant during system execution.
But let’s say you’re on your laptop, using your word processor while also running a compute-intensive operation in the background like video encoding. You select the spell-check tool and the word processor—configured for the laptop environment—deploys the heavyweight spell checker. Without as much compute available, the heavyweight spell checker is no longer an efficient option, delivering a sluggish response. In that moment, wouldn’t it be great if the word processor could recognize the limited resources and switch to the lightweight spell checker for a better user experience?
We propose a metareasoning approach that can assess a software system pipeline and adjust the parameters of individual modules for proper tradeoff among latency, accuracy, and other factors to ensure optimal operation of the entire system in real time. Looking at software pipeline optimization as a long-range sequential decision-making problem, we turn to reinforcement learning to accomplish this. Our paper on the work—“Metareasoning in Modular Software Systems: On-the-Fly Configuration using Reinforcement Learning with Rich Contextual Representations,” by Aditya Modi, Alekh Agarwal, Adith Swaminathan, Besmira Nushi, Sean Andrist, Eric Horvitz, and myself—will be presented at the 34th AAAI Conference on Artificial Intelligence by Modi, who worked on the research during his MSR AI PhD internship.
Metareasoning vs. end-to-end differentiation
Complicated multimodal software systems are all around us. They’re in our word processors, online banking, commercial search engines, and operating systems, and they’re getting bigger by the day as more mission-critical systems, like self-driving cars, become a reality. And changes to the environments in which these systems are running are not limited to situations in which other systems are using available resources like in the word processor example; different kinds of input to the software pipeline might also require different amounts of resources to meet the overall application-level utility function, which measures how well the software pipeline as a whole is performing and often depends on both latency and accuracy.
Today, it takes teams of engineers writing thousands of lines of code per module to build and maintain these systems. The rise of deep learning, however, is challenging the notion of how we write them. Andrej Karpathy, senior director of AI at Tesla, envisions a move toward writing software in a data-driven manner, a shift he calls “Software 2.0.” In a world of “Software 2.0,” instead of writing a module in code, one would gather input-output data and then train a module to learn to produce the correct output for a given input, much like a deep neural network. Such an approach would conveniently allow for an entire pipeline to be composed of such differentiable modules, and the standard pairing of gradient descent with backpropagation, a powerful credit assignment technique in supervised learning, could be used to optimize for the overall desired utility.
Unfortunately, such an approach may not be practical for even the simplest of pipelines. Pipelines would become uninterpretable, a limitation Karpathy concedes, and hard to debug, and more importantly, backpropagation plus gradient descent learns in expectation. Indeed, most of supervised learning machinery is understood in both theory and practice in expectation over data. This makes mission-critical systems infeasible to construct following this prescription. Even if these challenges could be surmounted in the future, there would remain a vast majority of legacy software pipelines and components—“Software 1.0”—that would need to be optimized. We’re interested in the promise of Software 2.0, but see benefits in advancing an approach to optimize Software 1.0 systems, since they have many intrinsic values.
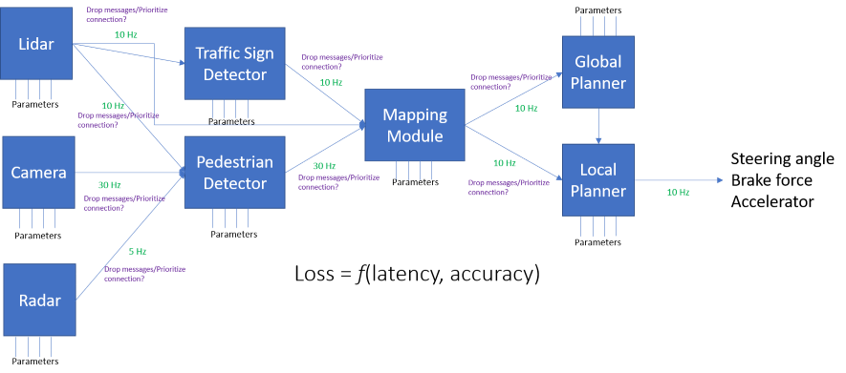
Complicated multimodal software systems are all around us, and they’re getting bigger by the day as more mission-critical systems, like self-driving cars, become a reality. Above is a simplified schematic of a nominal autonomous vehicle’s computing pipeline. The pipeline consists of numerous modules, each working at different rates and communicating information from local analyses to other modules in the pipeline. In the end, one cares about the application level loss, which is a function of both latency and accuracy of the system.
Reinforcement learning to the rescue
Software pipeline optimization, especially of complex systems, presents several challenges that a metareasoning approach has to account for:
1. Combinatorial action space: To determine the combination of module configurations that will yield optimal overall system performance requires assessing an exponentially large amount of available options—every possible parameter of a module with regard to every possible parameter of every other module. Due to the difficulty of this problem, the parameter configuration dependency behavior is often poorly understood and therefore associated with high technical debt.
2. Input- and compute-dependent configurations: Combinatorial action spaces aside, fixed configurations fall short of meeting the changing needs of real-world applications, as demonstrated by the word processor example. An approach adaptable to specific context is needed.
3. Credit assignment: Come run time, it’s difficult to ascertain to what extent each module configuration contributed to the overall success—or failure—of a system.
4. Configuration search latency: Metareasoning incurs a latency cost of its own. The process can’t take up so much time that it delays the pipeline itself and becomes self-defeating.
The above problems are rigorously studied in the field of sequential decision-making and, in particular, in reinforcement learning, which deals with principled methods for exploration and credit assignment. We were inspired to use RL in our metareasoning approach to software pipeline optimization partly by a 2010 thesis from The Robotics Institute at Carnegie Mellon University in which author David Bradley applied subgradient descent specifically to robotics modules like planners. Microsoft Senior Principal Researcher Dan Bohus—who works in the interactive systems space—helped us formulate the problem further during more recent conversations about the challenges of dynamic configuration in a robotic interactive system. The pipeline optimization challenge extends beyond robotics into general software engineering.
While RL offers many solutions, we chose an actor-critic approach that allows a system to update configurations across modules simultaneously in response to changing environmental factors. The actor-critic algorithm executes an action based on input, the outputs of intermediate modules, and potentially the available compute, adapting along the way, and then measures the reward at the end of the pipeline. In the word processor example, if the system chooses to deploy the heavy spell checker while an individual is also conducting a video conference call, it will receive a low reward, discouraging it from using the heavy spell checker when there is limited RAM or CPU available.
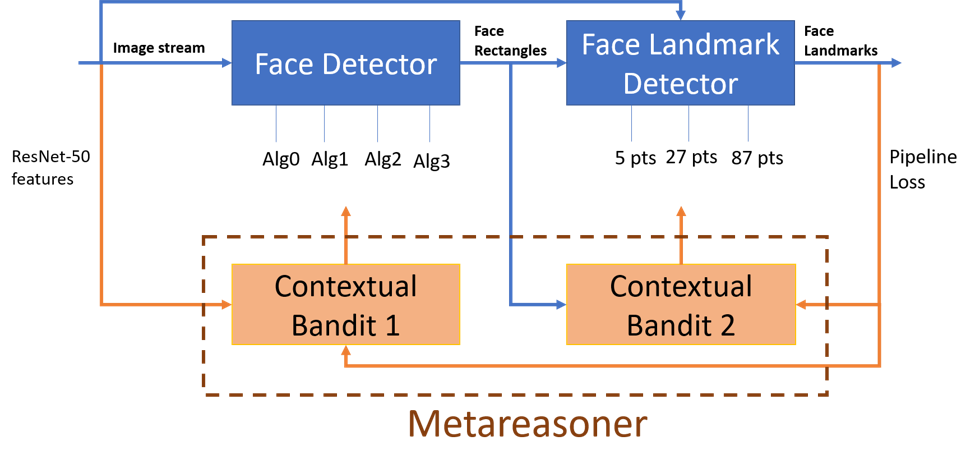
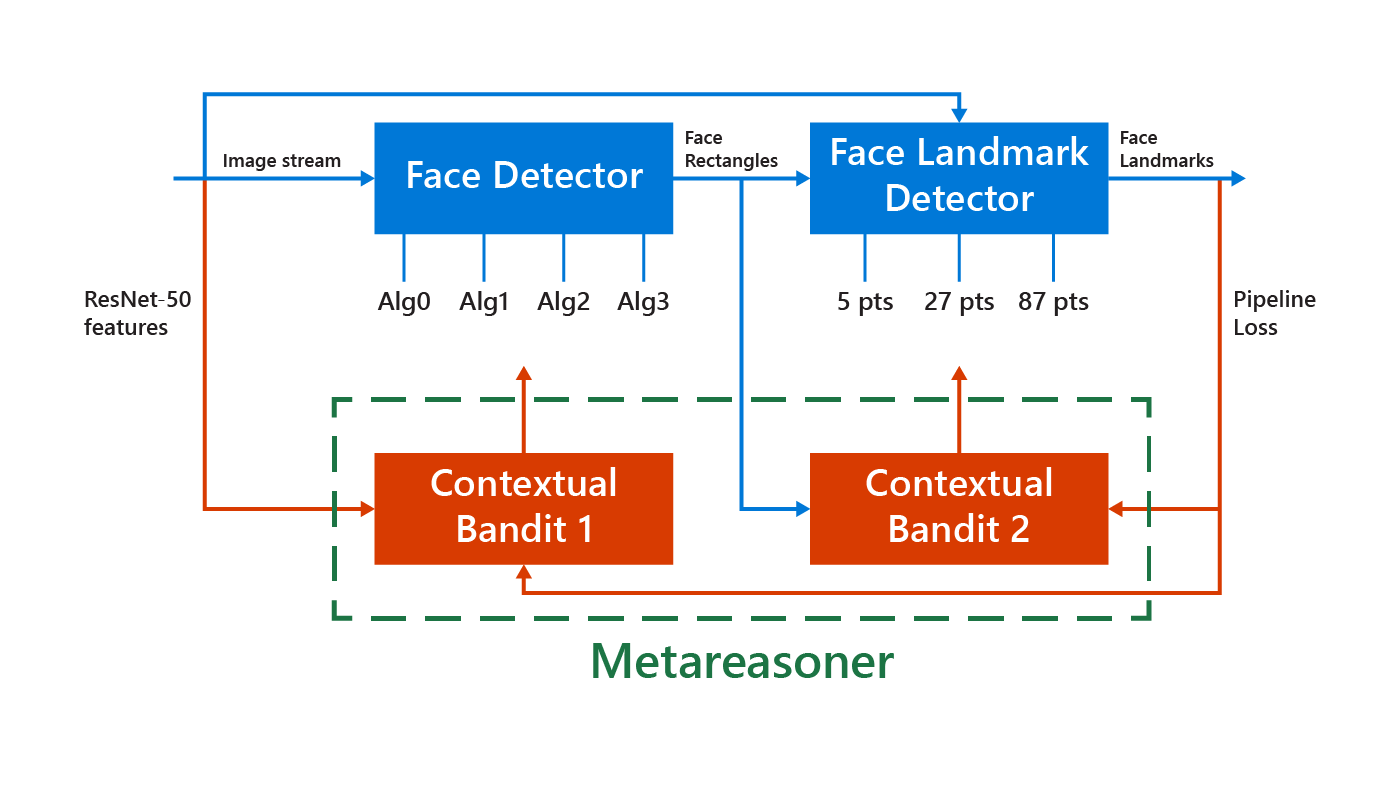
Face and landmark detection modular system. The input is a stream of images (from the open-source COCO dataset) analyzed by the face detection module, which outputs locations of faces that are then input into the face landmark detection module. The face landmark detection module outputs locations of eyes, nose, lips brows, and other features. The metareasoning module receives the input stream of images along with intermediate outputs of the face detector to dynamically adjust the configuration of the pipeline with the goal of optimizing the end system loss.
Putting the actor-critic method to the test
We tested this actor-critic approach on a real-world face and landmark detection pipeline, along with two optimization approaches. In the first optimization approach, which is similar to greedy hill climbing, every parameter of a single module is tried while holding the configurations of the other modules constant and measuring loss. The same process is executed for every module until no more improvement is seen.The result is a static configuration—that is, a configuration found offline to be good on an entire distribution of input data and deployed for the lifetime of the software deployment.The second optimization approach, global contextual bandit, incorporates a single contextual bandit unit for the entire pipeline. The contextual bandit takes an action based on available compute and the initial input data and receives a reward to learn an optimal configuration. Unlike the actor-critic method, this approach doesn’t consider intermediate module outputs, looking at the features of the input and making a configuration setting for the entire pipeline at once.
The face and landmark detection pipeline is context-dependent, as the latencies and accuracies of the algorithms employed in the first module, the face detection module, vary drastically with the number of faces present in the incoming images. Similarly, the latency of the second module, the landmark detector, is proportional to the number of detected faces from the previous module.
Leveraging advances in representation learning, we utilize a pretrained neural network’s activations as features (context) for our actor-critic method. These features are used to make decisions about the configuration of each module before the module operates on its inputs. Our actor-critic method, which looks at the intermediate results of the algorithm, improves about 9 percent across different utility functions over the best static configuration of the system. Not surprisingly, these improvements are higher—up to 24 percent—for images with a higher number of faces (three or more). This shows the importance of metareasoning on-the-fly in the pipeline.
In dynamic environments, such metareasoning methods can respect the accuracy-latency tradeoffs, learning a nice policy for adapting configuration parameters under changing conditions and supporting greater system utility and performance. We invite the community to provide us with feedback and case studies of software pipelines where the overall utility function is context-dependent.
The post AI for AI: Metareasoning for modular computing systems appeared first on Microsoft Research.