
This post has been republished via RSS; it originally appeared at: Microsoft Research.

Humans subconsciously use perception-action loops to do just about everything, from walking down a crowded sidewalk to scoring a goal in a community soccer league. Perception-action loops—using sensory input to decide on appropriate action in a continuous real time loop —are at the heart of autonomous systems. Although this tech has advanced dramatically in the ability to use sensors and cameras to reason about control actions, the current generation of autonomous systems are still nowhere near human skill in making those decisions directly from visual data. Here, we share how we have built Machine Learning systems that reason out correct actions to take directly from camera images. The system is trained via simulations and learns to independently navigate challenging environments and conditions in real world, including unseen situations.
Read the Paper Download the Code Watch the Video
We wanted to push current technology to get closer to a human’s ability to interpret environmental cues, adapt to difficult conditions and operate autonomously. For example, in First Person View (FPV) drone racing, expert pilots can plan and control a quadrotor with high agility using a noisy monocular camera feed, without compromising safety. We were interested in exploring the question of what it would take to build autonomous systems that achieve similar performance levels. We trained deep neural nets on simulated data and deployed the learned models in real-world environments. Our framework explicitly separates the perception components (making sense of what you see) from the control policy (deciding what to do based on what you see). This two-stage approach helps researchers interpret and debug the deep neural models, which is hard to do with full end-to-end learning.
The ability to efficiently solve such perception-action loops with deep neural networks can have significant impact on real-world systems. Examples include our collaboration with researchers at Carnegie Mellon University and Oregon State University, collectively named Team Explorer, on the DARPA Subterranean (SubT) Challenge. The DARPA challenge centers on assisting first responders and those who lead search and rescue missions, especially in hazardous physical environments, to more quickly identify people in need of help.
The video above shows the DARPA Subterranean Challenge, one of the ways Microsoft is advancing state of art in the area of autonomous systems by supporting research focused on solving real-world challenges. Learn more about Microsoft Autonomous systems.
Team Explorer has participated in the first two circuits of the challenge, taking second place in the February, 2020 Urban Circuit and first place in the September, 2019 Tunnel Circuit. In the Tunnel Circuit, the robots navigated underground tunnels for an hour at a time to successfully locate hidden items. In the Urban Circuit, they navigated two courses designed to represent complex urban underground infrastructure, including stairs and elevation changes. Reasoning correct control actions based on perception sensors is a critical component to success of the mission. The current methods used by Team Explorer include carefully engineered modules, such as localization, mapping and planning, which were then carefully orchestrated to carry out the mission. Here, we share how an approach of learning to map perception data to correct control actions can simplify the system further.
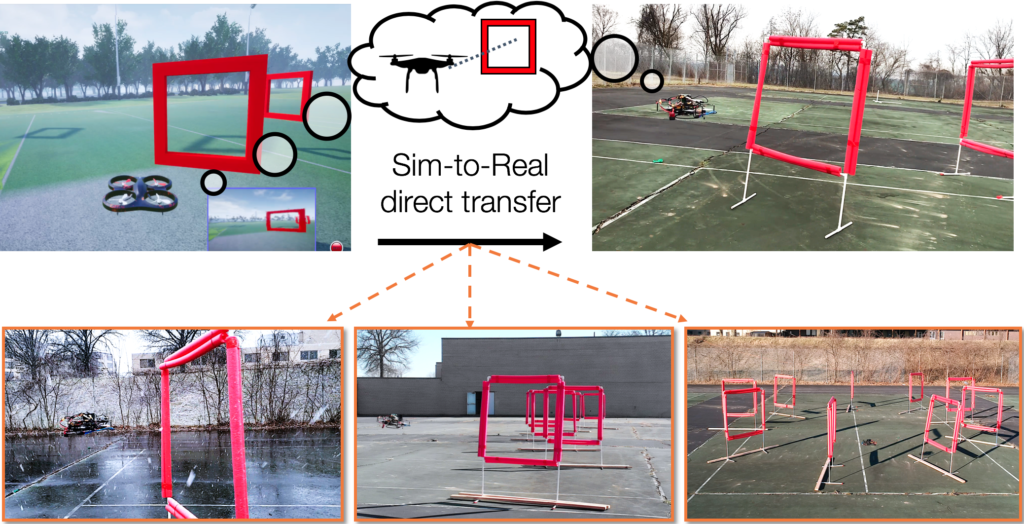
Figure 1. Our framework uses simulation to learn a low-dimensional state representation using multiple data modalities. This latent vector is used to learn a control policy which directly transfers to real-world environments. We successfully deploy the system under various track shapes and weather conditions, ranging from sunny days to strong snow and wind.
The Task
In first person view (FPV) drone racing, expert pilots can plan and control a quadrotor with high agility using a noisy monocular camera feed, without compromising safety. We attempted to mimic this ability with our framework, and tested it with an autonomous drone on a racing task.
We used a small agile quadrotor with a front facing camera, and our goal was to train a neural network policy to navigate through a previously unknown racing course. The network policy used only images from the RGB camera.
While autonomous drone racing is an active research area, most of the previous work so far has focused on engineering a system augmented with extra sensors and software with the sole aim of speed. Instead, we aimed to create a computational fabric, inspired by the function of a human brain, to map visual information directly to correct control actions. We achieved this by first converting the high-dimensional sequence of video frames to a low-dimensional representation that summarizes the state of the world.

Figure 2: Quadrotor used for the experiments. Images from the front-facing camera are processed on the onboard computer.
Our Approach
Our approach was to learn a visuomotor policy by decomposing the problem into the tasks of (1) building useful representations of the world and (2) taking a control action based on those representations. We used AirSim, a high-fidelity simulator, in the training phase and then deployed the learned policy in the real world without any modification. Figure 1 depicts the overall concept, showing a single perception module shared for simulated and real autonomous navigation.
A key challenge here is the models have to be robust to the differences (e.g., illumination, texture) between simulation and the real world. To this end, we used the Cross-Modal Variational Auto Encoder (CM-VAE) framework for generating representations that closely bridge the simulation-reality gap, avoiding overfitting to the eccentricities of synthetic data.
The first data modality considered the raw unlabeled sensor input (FPV images), while the second characterized state information directly relevant for the task at hand. In the case of drone racing, the second modality corresponds to the relative pose of the next gate defined in the drone’s coordinate frame. We learned a low-dimensional latent environment representation by extending the CM-VAE framework. The framework uses an encoder-decoder pair for each data modality, while constricting all inputs and outputs to and from a single latent space (see Fig. 3b).
The system naturally incorporated both labeled and unlabeled data modalities into the training process of the latent variable. Imitation learning was then used to train a deep control policy that mapped latent variables into velocity commands for the quadrotor (Fig. 3a).

Figure 3. (a) Control system architecture. The input image from the drone’s video is encoded into a latent representation of the environment. A control policy acts on the lower-dimensional embedding to output the desired robot control commands. (b) Cross-modal VAE architecture. Each data sample is encoded into a single latent space that can be decoded back into images, or transformed into another data modality such as the poses of gates relative to the unmanned aerial vehicle (UAV).
Learning to understand the world
The role of our perception module was to compress the incoming input images into a low-dimensional representation. For example, the encoder compressed images of size 128 X 72 in pixels (width X height) from 27,648 original parameters (considering three color channels for RGB) down to the most essential 10 variables that can describe it.
We interpreted the robot’s understanding of the world by visualizing the latent space of our cross-modal representations (see Figure 4). Despite only using 10 variables to encode images, the decoded images provided a rich description of what the drone can see ahead, including all possible gates sizes and locations, and different background information.

Figure 4. Visualization of imaginary images generated from our cross-modal representation. The decoded image directly captures the relative gate pose background information.
We also showed that this dimensionality compression technique is smooth and continuous. Figure 5 displays a smooth imaginary path between two images taken in real life. Given the cross-modal nature of the representation, we can see both decoded images and gate poses for the intermediate values.
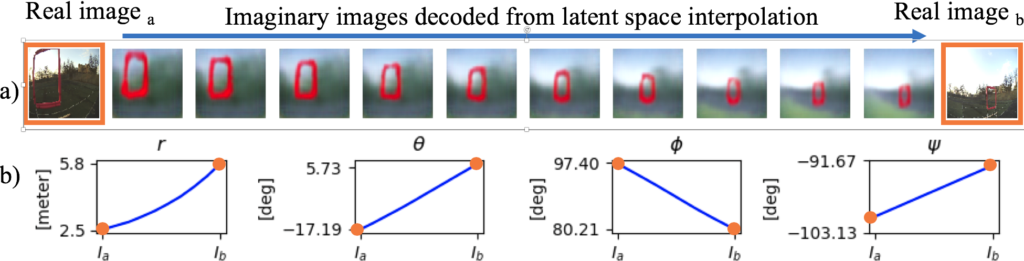
Figure 5: Visualization of smooth latent space interpolation between two real-world images. The ground-truth and predicted distances between camera and gate for images A and B were (2.0, 6.0) and (2.5, 5.8) meters respectively.
Results
To show the capabilities of our approach on a physical platform, we tested the system on a 45-meter-long S-shaped track with 8 gates, and on a 40-meter-long circular track with 8 gates, as shown in Figure 6. Our policy using a cross-modal representation significantly outperformed end-to-end control policies and networks that directly encoded the position of the next gates, without reasoning over multiple data modalities. To show the capabilities of our approach on a physical platform, we test the system on an S-shaped track with eight gates and 45 meters of length, and on a circular track with eight gates and 40 meters of length, as shown in Figure 6. Our policy that uses a cross-modal representation significantly outperforms end-to-end policies, and networks that directly encode the position of the next gates, without reasoning over multiple data modalities.

Figure 6: Side and top view of the test tracks: a) Circuit track, and b) S-shape track.
The performance of standard architectures dropped significantly when deployed in the real-world after training in simulation. Our cross-modal VAE, on the other hand, can still decode reasonable values for the gate distances despite being trained purely on simulation. For example, Fig. 7 displays the accumulated gate poses decoded from direct image to pose regression and from our framework, during three seconds of a real flight test. Direct regression results in noisy estimated gate positions, which are farther from the gate’s true location.
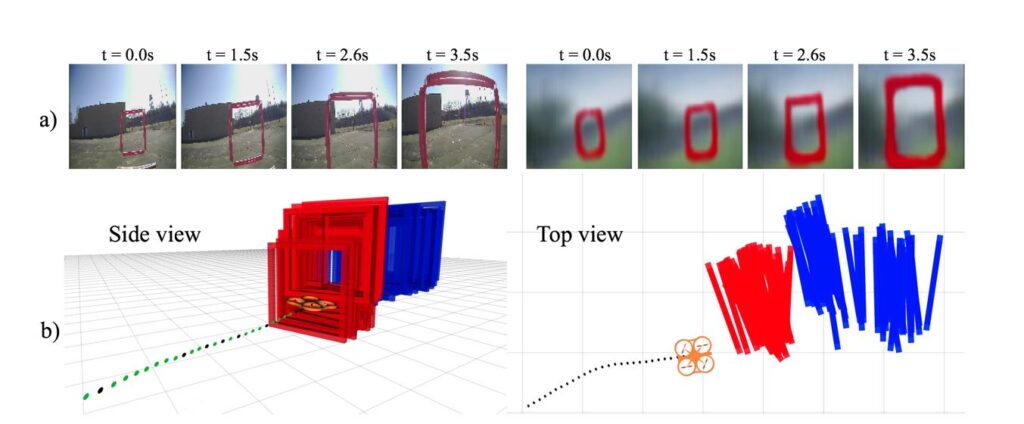
Fig 7. Analysis of a three-second flight segment. a) Input images and their corresponding images decoded by the CM-VAE; b) Time history of gate center poses decoded from the CM-VAE (red) and regression (blue). The regression representation has significantly higher offset and noise from the true gate pose, which explains its poor flight performance.
We take our perception-control framework to its limits by testing it in visual conditions never seen before during the training phase in simulation. Fig. 8 shows examples of successful test cases under extreme visually-challenging conditions: a) indoors, with a blue floor containing red stripes with the same red tone as the gates, and Fig. 8 b-c) during heavy snows. Despite the intense visual distractions from background conditions, the drone was still able to complete the courses by employing our cross-modal perception module.
Challenges and Future
By separating the perception-action loop into two modules and incorporating multiple data modalities into the perception training phase, we can avoid overfitting our networks to non-relevant characteristics of the incoming data. For example, even though the sizes of the square gates were the same in simulation and physical experiments, their width, color, and even intrinsic camera parameters are not an exact match. The multiple streams of information that are fed into the cross-modal VAE aid in implicit regularization of the learned model, which leads to better generalization over appearance changes.
We believe our results show great potential for helping in real-world applications. For example, if an autonomous search and rescue robot is better able to recognize humans in spite of differences in age, size, gender, ethnicity and other factors, that robot has a better chance of identifying and retrieving people in need of help.
An unexpected result we came across during our experiments is that combining unlabeled real-world data with the labeled simulated data for training the representation models did not increase overall performance. Using simulation-only data worked better. We suspect that this drop in performance occurs because only simulated data was used in the control learning phase with imitation learning. One interesting direction for future work we are investigating is the use of adversarial techniques for lowering the distance in latent space between similar scenes encoded from simulated and real images. This would lower the difference between data distributions during training and testing phases.
We envision extending the approach of using unlabeled data for policy learning. For example, besides images, can we combine distinct data modalities such as laser measurements and even sound for learning representations of the environment? Our success with aerial vehicles also suggests the potential to apply this approach to other real-world robotics tasks. For instance, we plan to extend our approach to robotic manipulation which also requires a similar ability to interpret inputs in real time and make decisions while ensuring safe operations.
The post Training deep control policies for the real world appeared first on Microsoft Research.