
This post has been republished via RSS; it originally appeared at: Microsoft Research.

It’s a big day for you. Back-to-back meetings are scheduled with critical customers and partners, and a parent-teacher conference is sandwiched in there as well. As you’re headed toward the last meeting, suddenly you cannot remember the key talking points. Who sent you the pre-read notes? Was it Taylor? No, possibly Drew. No luck. You are about two minutes from reaching the meeting room, and you want more than anything to pull out your phone and scream at it:
![]()
If only there existed an intelligent system that enabled you to find information this effortlessly. Now, there is: Meeting Insights provides AI capabilities that help you find information before, during, and after meetings as easily as if you had your own assistant to support you. Meeting Insights is now available for commercial Microsoft 365 and Office 365 customers in Outlook mobile (on both Android and iOS devices) and Outlook on the web. We would like to pull back the cover and talk about the science and technology that drives this scenario. Also, we’ll share why Meeting Insights is only the tip of the iceberg in how we at Microsoft are developing AI-powered capabilities to simplify and improve customer experience and productivity. We’re currently testing two new features that expand intelligent content recommendations to new scenarios in Outlook.
Providing usefulness in every context
Customers often say that finding content from meetings is a challenge. Therefore, we set out to build an intelligent personalized solution that provides customers with information from their mailboxes, OneDrive for Business accounts, and SharePoint sites to better help them accomplish the goals of their meetings.
The solution we developed powers the Meeting Insights feature that makes meetings more effective by helping customers:
- Prepare for their meetings by offering them content they haven’t had a chance to read or may want to revisit;
- Access relevant content during their meetings with ease;
- Retrieve information about completed meetings by returning content presented during the meeting, sent meeting notes, and other relevant post-meeting material

Currently, Meeting Insights can be found on more than 40% of all Outlook mobile and Outlook on the web meetings.
Large-scale, personal, privacy-preserving AI
The most useful emails and files for a meeting may change over time (for example, those most useful before may be different than the ones most useful during or after). In order to create a relevant and useful service, we needed to find a way to reason across information shared by a customer as well as the files in their organization that they have permission to access and have opted to share. Microsoft 365 upholds a strict commitment to protecting customer data—promising to only use customer data for agreed upon services and not look at data during development or deployment of a new feature. This privacy promise, rather than being a hindrance, spurred us to think creatively and to innovate. As detailed below, we use a creative combination of weak and self-supervised machine learning (ML) algorithms in Meeting Insights to train large-scale language models without looking at any customer data.
The need to efficiently reason over millions of private corpora, themselves each potentially containing millions of items, underscores the complexity of the problem we needed to solve in Meeting Insights. To accomplish this reasoning, Meeting Insights enlists the help of Microsoft Graph, where shared data is captured in a graph representation. Microsoft Graph provides convenient APIs to reason over all of the shared email, files, and meetings for customers as well as the relationship between these items. This provides a high level of personalization to accurately meet customer needs.
Building intelligent features like Meeting Insights in the enterprise setting poses additional problems to the standard ML workflow. In enterprise settings, customers have high expectations of new products—especially the ones in their critical workflows and even more so when they are paying for the service. Because there is a need for an initial model to work out of the gate, standard ML workflows, which deploy a heuristic model with moderate performance and take time to learn from interaction data, lead to a lack of product acceptance. In Meeting Insights, we use ML algorithms that require less supervision to personalize customers’ experiences more quickly.
This challenge, which we refer to as the ‘’jump-start’’ problem, is therefore critical to product success in enterprise scenarios. This goes beyond standard “cold-start” challenges where data about a particular item or new user of a system is lacking, and instead the primary challenge is to get the entire process off the ground. Common approaches to improve model performance before deployment, such as getting annotations from crowd-sourced judges, have limited to no applicability due to the privacy-sensitive and personal nature of the recommendation and learning challenges. Finally, Microsoft 365 is used all over the world, and we wanted to make this technology available as broadly as possible and not simply to a few select languages.

Figure 1: Schematic depiction of how we train the model for recommending emails in Meeting Insights.
Solving the technical challenges
In order to make Meeting Insights possible, we needed to leverage three key components: weak supervision that is language agnostic, personalization enriched by the Microsoft Graph, and an agile, privacy-preserving ML pipeline.
Weak supervision: Large-scale supervised learning provides state-of-the-art results for many applications. However, this is impractical when building new enterprise search scenarios due to the privacy-sensitive and personal nature of the problem space. Instead of having annotators labeling data, we turned to weak supervision, an approach where heuristics can be defined to programmatically label data. To apply weak supervision to this task, we used Microsoft’s compliant experimentation platform. Emails and files attached to meetings were assigned a positive label, and all emails and files which the organizer could have attached at meeting creation time but did not were assigned a negative label. The benefit of using weak supervision for this problem went beyond preserving privacy as it allowed us to quickly and cheaply scale across languages and communication styles—all of which would be extremely challenging with a strongly supervised modeling approach involving annotators.
Personalization: Identifying the most relevant and useful information for a customer requires understanding the people and phrases that are important for that person. In order to identify the candidate set of relevant items and rank them, we leverage personalized representations of the most important key phrases and key people for a person. These personalized representations are learned in a self-supervised and privacy-preserving manner from nodes and edges in the Microsoft Graph. The context meeting is then combined with these personalized key-phrase and people representations to construct a candidate set using the same. Microsoft Search endpoint uses the same Microsoft Search technology powering search in applications such as Outlook, Teams, and SharePoint. In the final ranking stage, these personalized representations as well as more general embeddings are used to compute semantic relatedness between the context and candidate items, relationship strength via graph features, and collaboration strength based on relationship between key people.
Agile privacy preserving ML pipelines: As noted above, preserving the privacy of our customers’ data is sacrosanct for Microsoft. The weak and self-supervised algorithm techniques described above allow us algorithmically to train highly accurate and language agnostic large-scale models without having to look at the customer’s data. However, in order to put the algorithms into practice, test them, and innovate, we needed a platform that makes approaches like this possible. Innovations on the modeling front went hand-in-hand with development of ML platforms and processes that allowed our scientists to remain agile. Our in-house compliant experimentation platform provides key privacy safeguards. For example, our algorithms can operate on customer content to provide recommendations directly to customers, but our engineers cannot see that content except when it’s their own. Many tools were developed to assist in monitoring and debugging our ML pipelines, firing off alerts when data quality as well correlations between signals and labels diverged from expected values.
Self-hosting to improve for our customers
As we developed Meeting Insights, we first rolled it out to internal Microsoft customers and instrumented their interactions with the experience to identify areas for improvement. Early on, we saw from the data we had instrumented that 90% of the usage of Meeting Insights on a given day was for meetings that or the following day. Armed with this datapoint, we were able to implement a significant optimization by prefetching the insights for these meetings the moment the customer opens their calendar. This data-informed strategy resulted in a 50% reduction of customer-perceived latency.
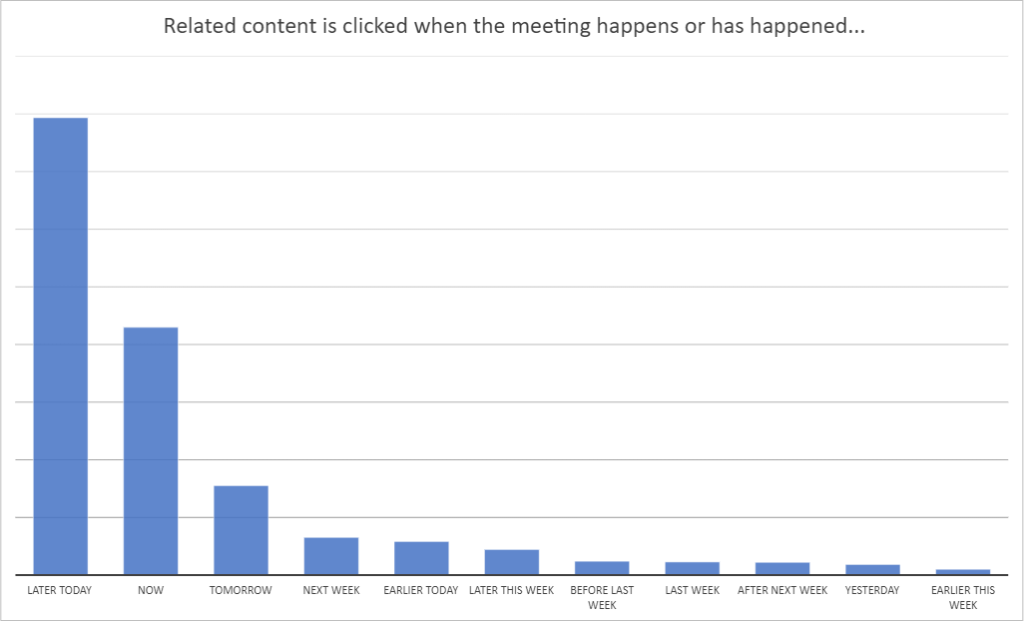
Customer engagement with the deployed product showed other strong temporal effects worth calling out for this experience:
- For meetings, freshness is important with about 5% of insights clicks happening within 15 minutes of the meeting being created.
- For email insights, 30% of clicks go to emails sent/received in the 24 hours preceding the time of the user request.
- For file insights, 35% of clicks go to files created or modified in the 24 hours preceding the time of the user request.
In less than four months after shipping our first Meeting Insights experience (for meeting invitations written in English), we were able to expand support to all enterprise customers across all languages. This was made possible by effectively leveraging the Microsoft Graph, being creative in the low-cost modeling approaches we employed, and being careful in the design of our AI solutions by using weak supervision and avoiding language specific dependencies. Over the next few months, we will be rolling Meeting Insights out to Cortana Briefing Mail recipients.
Meeting Insights is currently shown on more than 40% of opened meetings on supported Outlook clients, with customers reporting two out of three suggestions to be useful.
Providing broader contextual intelligence
Meeting Insights is not the only place where we are providing contextual intelligence that makes life easier for our customers. We are looking at how we can use Meeting Insights to accelerate our offerings in other scenarios using techniques like transfer learning, which has proven to be an effective and efficient way for us to gain reusable value from AI models learned for one scenario but reapplied to another.
For example, we are now transferring the learnings from our Meeting Insights models to power other intelligent content recommendations features such as “Suggested Attachments” and “Suggested Reply with File” on Outlook. These features take a customer and an email as input to return contextually relevant attachment suggestions that significantly reduce the time and effort required to share content via email.

“Suggested Attachments” and “Suggested Reply with File” are features currently in testing phases. We look forward to adding new offerings for Microsoft 365 users and beyond for intelligent content recommendation.
Imagine you’re heading to that last meeting again after an exceptionally busy day. You’ve suddenly forgotten the talking points, and you just can’t seem to recall who sent those pre-read notes. Was it Taylor? Drew? You feel like shouting at the sky, but then a thought flashes into your mind. You calmly pull up Outlook mobile on your phone as you approach the room, and with a simple tap on the meeting, your pre-read notes appear at the bottom of the screen thanks to Meeting Insights. Now, you’ve got this.
We look forward to continuing to improve life for our customers, and we hope the next time you walk into a meeting, you also walk in with more confidence knowing that Meeting Insights is there to assist you.
The post Meeting Insights: Contextual assistance for everyone appeared first on Microsoft Research.