
This post has been republished via RSS; it originally appeared at: Microsoft Research.

What we can teach a model to do with natural language is dictated by the availability of data. Currently, we have a lot of labeled data for very few languages, making it difficult to train models to accomplish question answering, text summarization, and other tasks in every language and ultimately limiting the amount of people who can benefit from advanced AI systems. In natural language processing (NLP), low-resource learning—scenarios in which a model is trained using very little training data or data without examples of the type of data it will encounter in testing—is an active challenge. Cross-lingual transfer learning is a type of low-resource learning that trains a model with data in one language, such as English, and tests the model on the same task in different languages. With cross-lingual transfer capability, we could leverage the rich resources of a few languages to build NLP services for all the languages in the world.
Recently, pre-trained models such as Unicoder, M-BERT, and XLM have been developed to learn multilingual representations for cross-lingual and multilingual tasks. By performing masked language model, translation language model, and other bilingual pre-training tasks on multilingual and bilingual corpora with shared vocabulary and weights for multiple languages, these models obtain surprisingly good cross-lingual capability. However, the community still lacks benchmark datasets to evaluate such capability. The Cross-Lingual Natural Language Inference (XNLI) corpus is the most used cross-lingual benchmark for these models, but its evaluation scenario—natural language inference—is too simple to cover various real-world cross-lingual tasks.
To help the research community further advance language-agnostic models and make AI systems more inclusive, we introduce “XGLUE: A New Benchmark Dataset for Cross-lingual Pre-training, Understanding and Generation.” With its training data available only in English, XGLUE’s 11 downstream tasks test a model’s zero-shot cross-lingual transfer capability—that is, its ability to transfer what it learned in English to the same task in other languages. In all, XGLUE covers 19 languages, including Italian, Portuguese, Russian, Swahili, and Urdu. XGLUE comprises both cross-lingual natural language understanding (NLU) tasks and cross-lingual natural language generation (NLG) tasks and offers six new tasks used in creating and evaluating search engine and news site scenarios, unique features that set XGLUE apart from existing NLP datasets. We also extended the universal language encoder Unicoder for a baseline, introducing two different generation pre-training tasks to accommodate NLG.
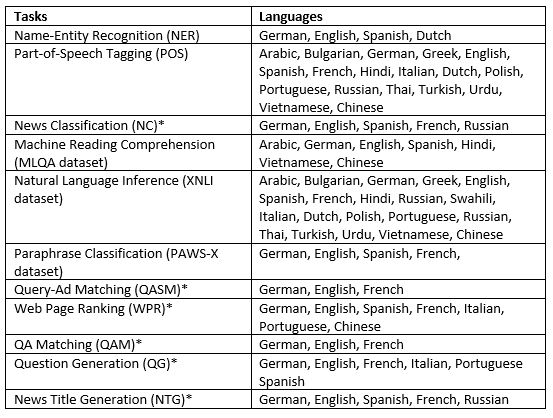
Languages covered by XGLUE tasks
The 19 languages covered by XGLUE’s 11 tasks, broken down by task. Asterisks denote the new understanding and generation tasks offered by the dataset.
We see XGLUE as an important tool in helping researchers and developers ensure that access to advanced AI systems isn’t limited by the language an individual speaks. That includes those AI systems being created through AI at Scale, the Microsoft initiative driving next-generation AI capabilities.

Figure 1: The new XGLUE benchmark dataset has 11 tasks, including four new NLU tasks and two new NLG tasks, denoted in the above table with an asterisk. For each task, the training set is available only in English. The third column in the table is the number of labeled instances in the training set. The fourth and fifth columns are the average numbers of labeled instances in the development sets and test sets, respectively.
New tasks—including NLG tasks—from real-world scenarios
XGLUE includes five existing NLU tasks—name-entity recognition (NER), part-of-speech tagging (POS), machine reading comprehension (MLQA dataset), paraphrase classification (PAWS-X dataset), and XNLI—but it’s the dataset’s newest tasks that give researchers an opportunity to evaluate a model’s real-world potential:
-
- News Classification (NC): A model is tasked with identifying an article’s news category, such as whether it’s sports, entertainment, or world news; languages: English, French, German, Spanish, and Russian
- Query-Ad Matching (QADSM): A model determines whether an ad recommendation is “good” or “bad” given a query; languages: English, French, and German
- Web Page Ranking (WPR): Based on a scale of 0 (bad) to 4 (perfect), a model ranks the relevance of results given a query; languages: English, French, German, Spanish, Italian, Portuguese, and Chinese
- QA Matching (QAM): A model is tasked with determining if a passage is relevant to a given query; languages: English, French, and German
- Question Generation (QG): Given a passage a model provides a query; languages: English, French, German, Spanish, Italian, and Portuguese
- News Title Generation (NTG): A model creates a headline based on a news article; languages: English, French, German, Spanish, and Russian
Data for XGLUE’s news classification and news title generation tasks originated from the Microsoft news website Microsoft News, while data for the remaining tasks came from the Microsoft search engine Bing. Privacy-preserving steps were taken in the collection of the data, including the removal of any data that could potentially contain personally identifiable information.
Collectively, these six new tasks represent much of what today’s commercial search engines do and capture the user experience, providing a true test of how well a model generalizes across NLU and NLG tasks and demonstrating more concretely how a model can impact people down the line. That could mean improved direct answers to search queries, saving people the time of having to sift through pages of search results, or news organized in a way that lets people find what they want to read about more easily.
The XGLUE dataset and example code for running the XGLUE baseline are available on GitHub. Those interested in sharing their results can do so via the XGLUE leaderboard.
![A figure shows the training procedure of four tasks used in pre-training Unicoder for cross-lingual understanding tasks; Unicoder is labeled as having 12 layers and a shared vocabulary size of 250,000 across 100 languages. For the masked language model task, the sentence “this is an example” becomes “this is [MASK] [MASK],” and Unicoder predicts the masked words are “an” and “example.” The translation language model task combines a bilingual sentence pair—“this is an example” in English and Chinese—and then masks words, which Unicoder then predicts. Contrastive learning combines the sentence pair “This is an example” and its Chinese equivalent, and the model determines whether they have the same meaning. In the cross-lingual word recovery task, the sentence pair is represented by a new generated word representation sequence, from which Unicoder recovers all the words.](https://www.microsoft.com/en-us/research/uploads/prod/2020/06/Unicoder-Updated-Fig-1-1024x508.jpg)
Figure 2: Researchers used a simplified version of the universal language encoder Unicoder for an XGLUE baseline. The original Unicoder is pre-trained for cross-lingual understanding tasks using masked language model, translation language model, contrastive learning, and cross-lingual word recovery (above). Each column shows an example for each NLU task, respectively. For XGLUE, Unicoder is pre-trained by masked language model and translation language model only.
Cross-lingual pre-training in Unicoder
For our baseline, we chose Unicoder, which we introduced at the 2019 Conference on Empirical Methods in Natural Language Processing. For cross-lingual NLU tasks, Unicoder is pre-trained using both multilingual and bilingual corpora by the following tasks (Figure 2 above): masked language model and translation language model, which predict each masked token or phrase based on monolingual context and bilingual context respectively; contrastive learning, which predicts whether a bilingual word/phrase/sentence pair is a translation pair; and cross-lingual word recovery, which predicts the original source sequence by its vector representations generated based on the token representations of its target translation sequence. For XGLUE, we used a simplified version of Unicoder, pre-training it by masked language model and translation language model only.
![A flowchart depicts the process of extending Unicoder for cross-lingual generation tasks; Unicoder is labeled as having 12 layers and a shared vocabulary size of 250,000 across 100 languages. The sentence “This could be a sentence in any language” is corrupted via one of four text noising methods: sentence permutation (“could this be sentence a in . any language”); token deletion (“this be a in any language”); token masking (“[MASK] could be a [MASK] in any [MASK] .”); or text infilling (“this could be [MASK] in [MASK] .”). The corrupted sentence is input into the Unicoder encoder. The sentence moves through the decoder, which uses one of the two text denoising methods—xDAE or xFNP—to generate the original sentence. A figure representing xDAE shows the decoder generating a single token at each time step. A figure representing xFNP shows the decoder generating multiple tokens each step.](https://www.microsoft.com/en-us/research/uploads/prod/2020/06/Unicoder-Updated-Fig-2-1024x445.jpg)
Figure 3: Researchers extended Unicoder for cross-lingual generation tasks using two generation tasks during pre-training: multilingual Denoising Auto-Encoding (xDAE) and multilingual Future N-gram Prediction (xFNP). In pre-training Unicoder, a text noising approach is used to corrupt a sentence, which is then used as the input of the Unicoder encoder. Then, the decoder attempts to generate the original input sequence based on its corrupted form. Researchers tried four different text noising methods and the two different text denoising methods.
Evaluation results on XGLUE
We evaluate Unicoder and two other recent cross-lingual pre-trained models, M-BERT and XLM-RoBERTa (XLM-R), on XGLUE. For each task, the models are fine-tuned on its task-specific English data and then applied to all test sets, which are in a variety of languages, including English, aiming to evaluate each model’s zero-shot cross-lingual transfer capability. For the cross-lingual NLU tasks, Unicoder performs slightly better than M-BERT and XLM-R because it’s pre-trained using both multilingual and bilingual corpora; the other two models are pre-trained using a multilingual corpus only. For the cross-lingual NLG tasks, Unicoder performs significantly better than M-BERT and XLM-R because it introduces generation tasks into the pre-training stage; the other two models are fine-tuned on these two downstream tasks directly without pre-training.
We also investigated the impacts of different fine-tuning strategies:
- Pivot-language fine-tuning, which fine-tunes a pre-trained model on its labeled data in one language, referred to here as a pivot language, and evaluates the model on test sets in different languages. Interestingly, Spanish, Greek, and Turkish, rather than English, proved to be the most effective pivot languages on XNLI. This phenomenon shows a possibility to further improve the average performance of a cross-lingual pre-trained model by using different pivot languages depending on the downstream task.
- Multi-language fine-tuning, which fine-tunes a pre-trained model on a combination of available labeled data in different languages. By doing this, significant gains can be obtained on different downstream tasks such as XNLI and NTG.
- Multi-task fine-tuning, which fine-tunes a pre-trained model for multiple downstream tasks on the tasks’ combined English labeled data. The success of joint fine-tuning varied by task. Further investigation is needed to better understand the relationships between different tasks and how they can improve fine-tuning.
Looking forward
With XGLUE, we seek to leverage the abundance of rich training data in English to support the development of models that can be applied to all languages—models that have a truly universal language representation. Moving forward, we’ll extend XGLUE to more languages and downstream tasks while continuing to push forward cross-lingual pre-trained models by exploring new model structures, introducing new pre-training tasks, using different types of data, and expanding cross-lingual pre-training to other modalities such as images and videos.
Acknowledgment: This research was conducted by Yaobo Liang, Nan Duan, Yeyun Gong, Ning Wu, Fenfei Guo, Weizhen Qi, Ming Gong, Linjun Shou, Daxin Jiang, Guihong Cao, Xiaodong Fan, Ruofei Zhang, Rahul Agrawal, Edward Cui, Sining Wei, Taroon Bharti, Ying Qiao, Jiun-Hung Chen, Winnie Wu, Shuguang Liu, Fan Yang, Daniel Campos, Rangan Majumder, and Ming Zhou. We thank the Search Technology Center Asia NLP team, the Bing Answer team, the Bing Relevance team, the Bing Ads team, and the Microsoft News team for providing the real-world datasets.
The post XGLUE: Expanding cross-lingual understanding and generation with tasks from real-world scenarios appeared first on Microsoft Research.