
This post has been republished via RSS; it originally appeared at: Microsoft Research.
Reinforcement learning (RL) provides exciting opportunities for game development, as highlighted in our recently announced Project Paidia—a research collaboration between our Game Intelligence group at Microsoft Research Cambridge and game developer Ninja Theory. In Project Paidia, we push the state of the art in reinforcement learning to enable new game experiences. In particular, we focus on developing game agents that learn to genuinely collaborate in teams with human players. In this blog post we showcase three of our recent research results that are motivated by these research goals. We give an overview of key insights and explain how they could lead to AI innovations in modern video game development and other real-world applications.
Reinforcement learning can give game developers the ability to craft much more nuanced game characters than traditional approaches, by providing a reward signal that specifies high-level goals while letting the game character work out optimal strategies for achieving high rewards in a data-driven behavior that organically emerges from interactions with the game. To learn how you can use RL to develop your own agents for gaming and begin writing training scripts, check out this Game Stack Live blog post. Getting started with reinforcement learning is easier than you think—Microsoft Azure also offers tools and resources, including Azure Machine Learning, which provides RL training environments, libraries, virtual machines, and more.
The key challenges our research addresses are how to make reinforcement learning efficient and reliable for game developers (for example, by combining it with uncertainty estimation and imitation), how to construct deep learning architectures that give agents the right abilities (such as long-term memory), and how to enable agents that can rapidly adapt to new game situations. Below, we highlight our latest research progress in these three areas.
Highlight 1: More accurate uncertainty estimates in deep learning decision-making systems
From computer vision to reinforcement learning and machine translation, deep learning is everywhere and achieves state-of-the-art results on many problems. We give it a dataset, and it gives us a prediction based on a deep learning model’s best guess. The success of deep learning means that it is increasingly being applied in settings where the predictions have far-reaching consequences and mistakes can be costly.
The problem is that the best-guess approach taken by most deep learning models isn’t enough in these cases. Instead, we want a technique that provides us not just with a prediction but also the associated degree of certainty. Our ICLR 2020 paper, “Conservative Uncertainty Estimation By Fitting Prior Networks,” explores exactly that—we describe a way of knowing what we don’t know about predictions of a given deep learning model. This work was conducted by Kamil Ciosek, Vincent Fortuin, Ryota Tomioka, Katja Hofmann, and Richard Turner.
In more technical terms, we provide an analysis of Random Network Distillation (RND), a successful technique for estimating the confidence of a deep learning model.
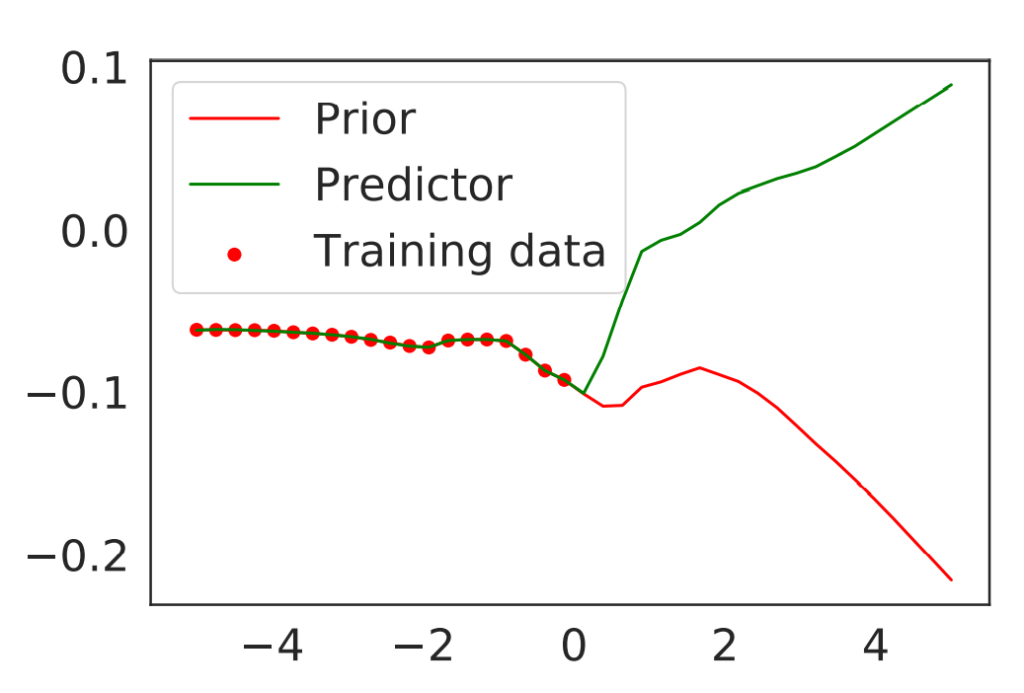
The version of RND we analyze maintains an uncertainty model separate from the model making predictions. To provide a bit more intuition about how the uncertainty model works, let’s have a look at the Figure 1 above. We have two types of neural networks: the predictor (green) and the prior (red). The prior network is fixed and does not change during training. When we see a new data point, we train the predictor to match the prior on that point. In the figure, the data points we have observed are represented with red dots. We can see that close to the points, the predictor and the prior overlap. On the other hand, we see a huge gap between the predictor and prior if we look at the values to the right, far from the observed points.
Roughly speaking, theoretical results in the paper show that the gap between prior and predictor is a good indication of how certain the model should be about its outputs. Indeed, we compare the obtained uncertainty estimates to the gold standard in uncertainty quantification—the posterior obtained by Bayesian inference—and show they have two attractive theoretical properties. First, the variance returned by RND always overestimates the Bayesian posterior variance. This means that while RND can return uncertainties larger than necessary, it won’t become overconfident. Second, we show that the uncertainties concentrate, that is they eventually become small after the model has been trained on multiple observations. In other words, the model becomes more certain about its predictions as we see more and more data.
Highlight 2: Utilizing order-invariant aggregators to enhance agent recall
In many games, players have partial observability of the world around them. To act in these games requires players to recall items, locations, and other players that are currently out of sight but have been seen earlier in the game. Typically, deep reinforcement learning agents have handled this by incorporating recurrent layers (such as LSTMs or GRUs) or the ability to read and write to external memory as in the case of differential neural computers (DNCs).
Using recurrent layers to recall earlier observations was common in natural language processing, where the sequence of words is often important to their interpretation. However, when agents interact with a gaming environment, they can influence the order in which they observe their surroundings, which may be irrelevant to how they should act. To give a human-equivalent example, if I see a fire exit when moving through a new building, I may need to later recall where it was regardless of what I have seen or done since. In our ICLR 2020 paper “AMRL: Aggregated Memory For Reinforcement Learning,” we propose the use of order-invariant aggregators (the sum or max of values seen so far) in the agent’s policy network to overcome this issue.
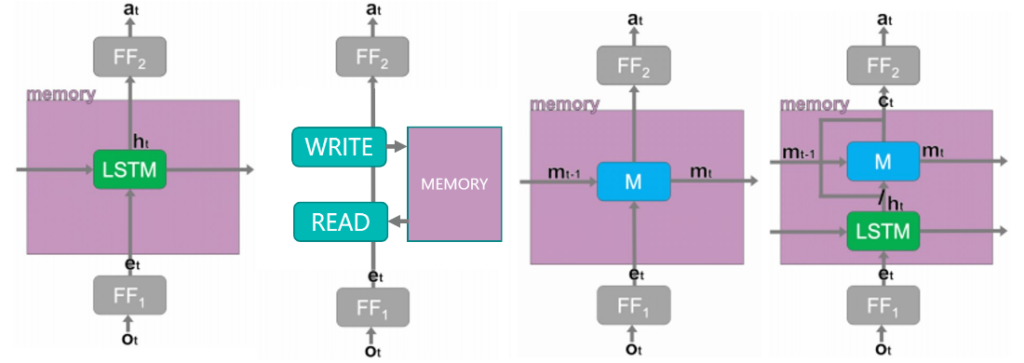
While approaches that enable the ability to read and write to external memory (such as DNCs) can also learn to directly recall earlier observations, the complexity of their architecture is shown to require significantly more samples of interactions with the environment, which can prevent them from learning a high-performing policy within a fixed compute budget.
In our experiments, our Minecraft-playing agents were shown either a red or green cube at the start of an episode that told them how they must act at the end of the episode. In the time between seeing the green or red cube, the agents could move freely through the environment, which could create variable-length sequences of irrelevant observations that could distract the agent and make them forget the color of the cube at the beginning.
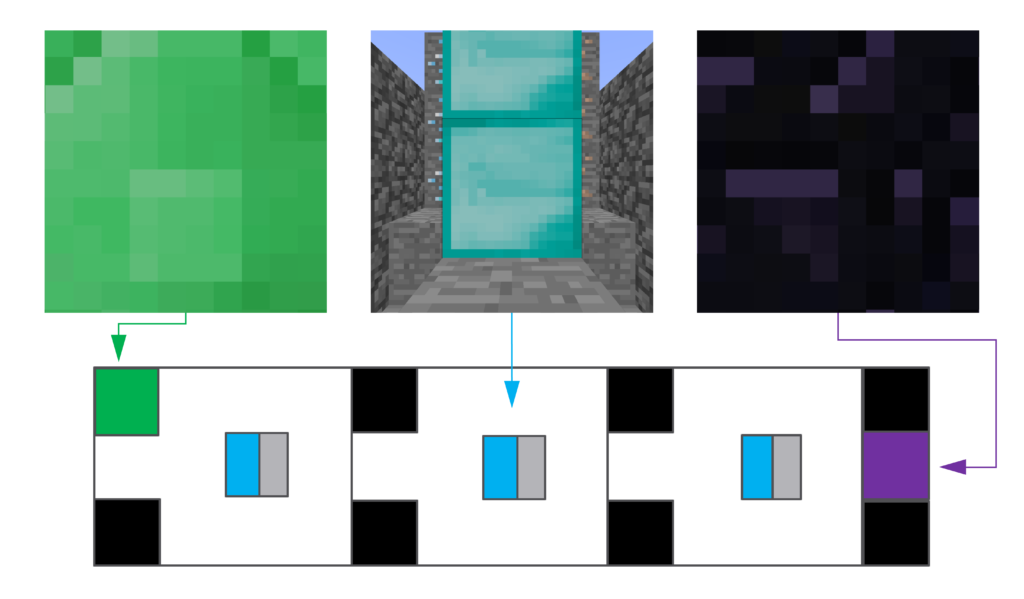
By combining recurrent layers with order-invariant aggregators, AMRL can both infer hidden features of the state from the sequence of recent observations and recall past observations regardless of when they were seen. Enabling our agents, to efficiently recall the color of the cube and make the right decision at the end of the episode. Now empowered with this new ability, our agents can play more complex games or even be deployed in non-gaming applications where agents must recall distant memories in partially observable environments.
Researchers who contributed to this work include Jacob Beck, Kamil Ciosek, Sam Devlin, Sebastian Tschiatschek, Cheng Zhang, and Katja Hofmann.
Highlight 3: VariBAD—exploring unknown environments with Bayes-Adaptive Deep RL and meta-learning
Most current reinforcement learning work, and the majority of RL agents trained for video game applications, are optimized for a single game scenario. However, a key aspect of human-like gameplay is the ability to continuously learn and adapt to new challenges. In our joint work with Luisa Zintgraf, Kyriacos Shiarlis, Maximilian Igl, Sebastian Schulze, Yarin Gal, and Shimon Whiteson from the University of Oxford, we developed a flexible new approach that enables agents to learn to explore and rapidly adapt to a given task or scenario.
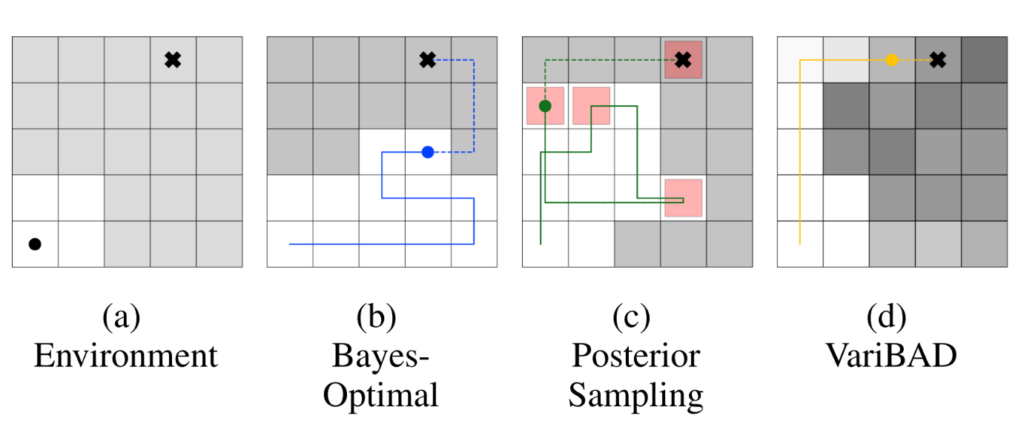
In “VariBAD: A Very Good Method for Bayes-Adaptive Deep RL via Meta-Learning,” we focus on problems that can be formalized as so-called Bayes-Adaptive Markov Decision Processes. Briefly, in this setting an agent learns to interact with a wide range of tasks and learns how to infer the current task at hand as quickly as possible. Our goal is to train Bayes-optimal agents—agents that behave optimally given their current belief over tasks. For example, imagine an agent trained to reach a variety of goal positions. At the beginning of each new episode, the agent is uncertain about the goal position it should aim to reach. A Bayes-optimal agent takes the optimal number of steps to reduce its uncertainty and reach the correct goal position, given its initial belief over possible goals.
Our new approach introduces a flexible encoder-decoder architecture to model the agent’s belief distribution and learns to act optimally by conditioning its policy on the current belief. We demonstrate that this leads to a powerful and flexible solution that achieves Bayes-optimal behavior on several research tasks. In our ongoing research we investigate how approaches like these can enable game agents that rapidly adapt to new game situations.
Continuing work in game intelligence
In this post we have shown just a few of the exciting research directions that we explore within the Game Intelligence theme at Microsoft Research Cambridge and in collaboration with our colleagues at Ninja Theory. A key direction of our research is to create artificial agents that learn to genuinely collaborate with human players, be it in team-based games like Bleeding Edge, or, eventually, in real world applications that go beyond gaming, such as virtual assistants. We view the research results discussed above as key steps towards that goal: by giving agents better ability to detect unfamiliar situations and leverage demonstrations for faster learning, by creating agents that learn to remember longer-term dependencies and consequences from less data, and by allowing agents to very rapidly adapt to new situations or human collaborators.
To learn more about our work with gaming partners, visit the AI Innovation page. To learn more about our research, and about opportunities for working with us, visit aka.ms/gameintelligence.
The post Three new reinforcement learning methods aim to improve AI in gaming and beyond appeared first on Microsoft Research.