
This post has been republished via RSS; it originally appeared at: Microsoft Research.
Over the years at Microsoft Research, we’ve studied how to build AI systems that perceive, understand, and act in a human-filled world in real time. Our motivation has been to create computing systems that can support interactive experiences akin to what we expect when we talk to or collaborate with people. This research line has involved the development of several physically situated interactive applications, including embodied conversational agents that serve as personal assistants, robots that give directions in our building, and smart elevators that recognize people’s intentions to board versus walk by. Building such systems has required composing and coordinating different AI technologies to achieve multimodal capabilities—that is, the joint use of multiple channels, such as speech and vision. Our efforts in this space have highlighted challenges with creating integrative AI systems—that is, systems that weave together multiple AI technologies such as machine learning, computer vision, speech recognition, natural language processing, and dialogue management.

Whether you’re a researcher like us building prototype systems for experimentation or an industry developer building and deploying end-to-end solutions for customers, anyone who has experience developing applications that use multimodal streaming data and operate in real time can attest that the engineering hurdles are steep. These applications often need to seamlessly coordinate computation over a heterogeneous array of component technologies under latency constraints. Key constructs and primitives, such as the ability to represent and reason about time, synchronization, and data fusion, are missing from existing programming fabrics and infrastructures. Tools for temporal data visualization and analytics are not available or not closely integrated with the development cycle for these applications. It seems that much of the effort (and code) is spent debugging and creating custom infrastructure and tools for logging, monitoring, and understanding low-level issues and application performance rather than creating the applications themselves.
To address these challenges and create a solid foundation for development, experimentation, and research in this space, we’ve built Platform for Situated Intelligence, an open-source framework for multimodal, integrative AI systems. The framework provides a modern infrastructure tailored for working with multimodal streams of data, a rich set of tools that supports the development cycle, and an open ecosystem of components that promotes fast prototyping and reuse. And while Platform for Situated Intelligence was motivated by our team’s experiences in physically situated interactive systems and robotics, its scope and reach are significantly broader: Any application that processes streaming, sensory data, combines multiple AI technologies, and operates under latency constraints can benefit from the affordances the framework provides.
A closer look
Platform for Situated Intelligence is a cross-platform framework built on .NET Standard. Overall, the framework retains the affordances and software engineering benefits of a managed programming language, such as type safety and memory management, while addressing the very specific needs of multimodal, integrative AI applications.
At the high level, an application built with Platform for Situated Intelligence consists of a graph of components that communicate with each other over streams of data. Components can encapsulate sensors, such as microphones and cameras; specific AI technologies, such as speech recognizers and object detectors; or any other custom unit of computation. This component graph, also known as the application pipeline, is constructed by the application developer programmatically.
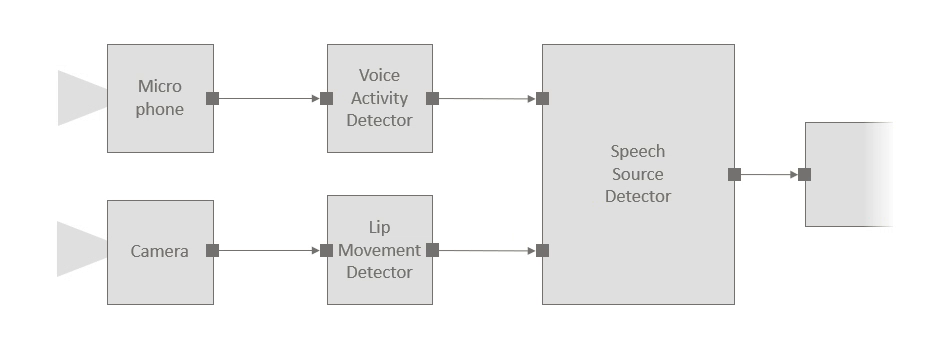
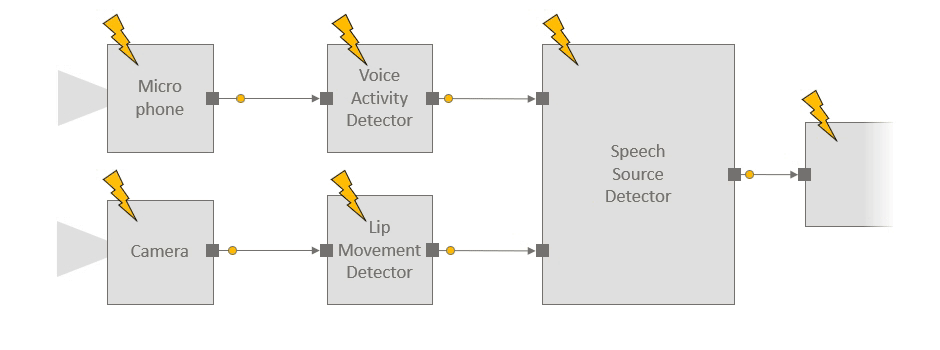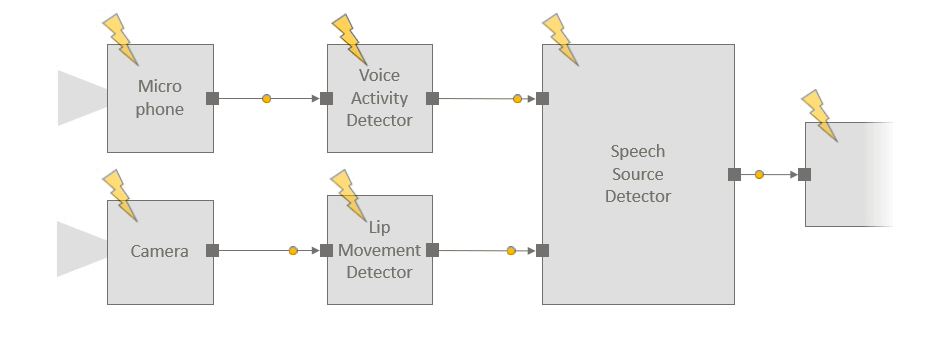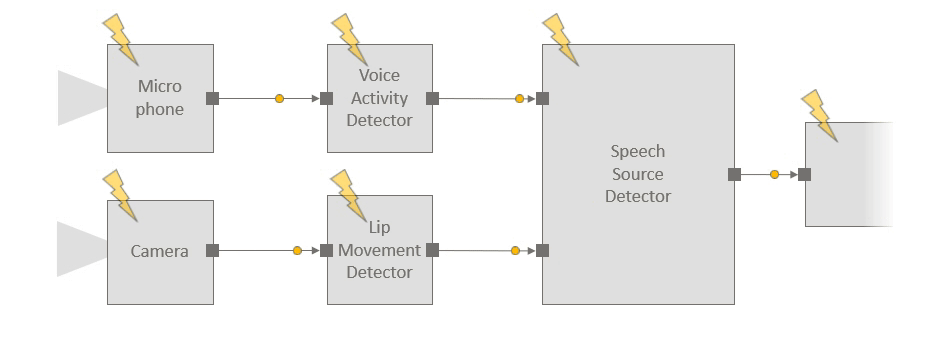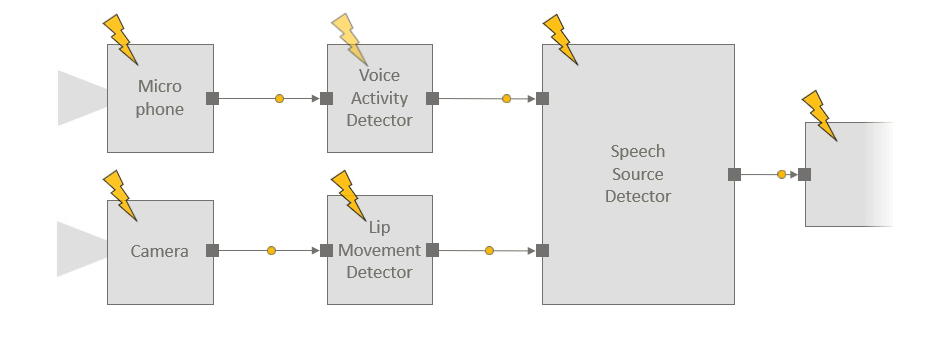
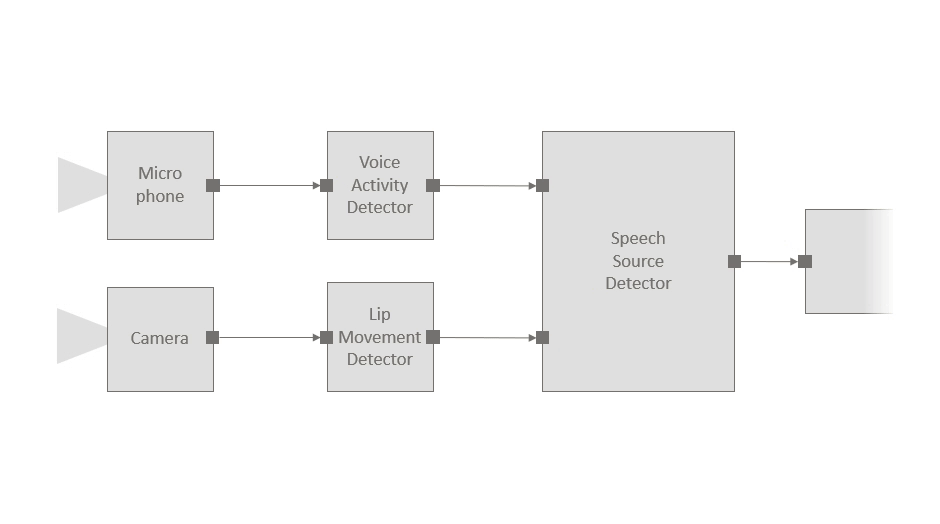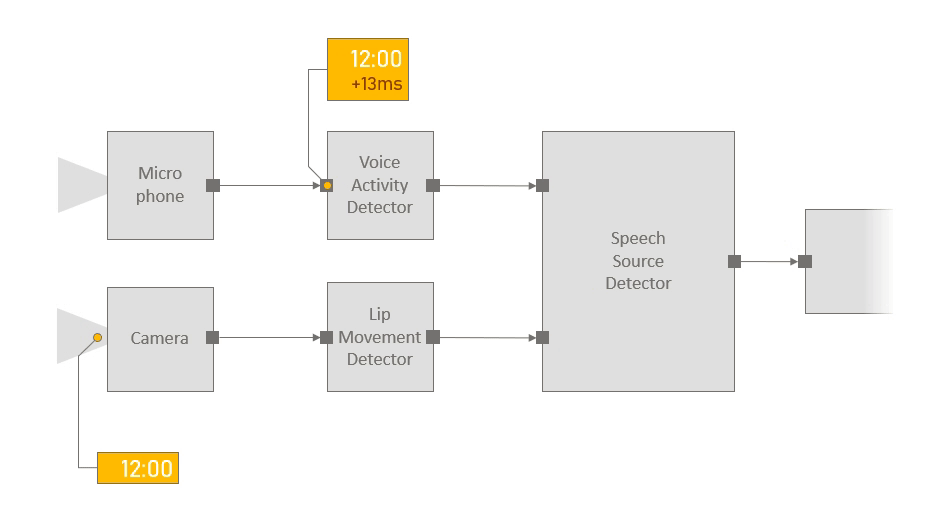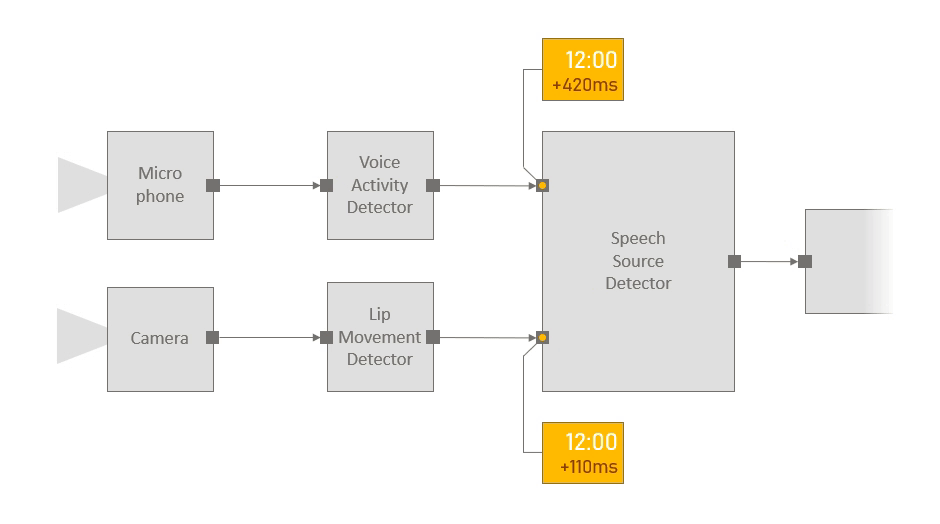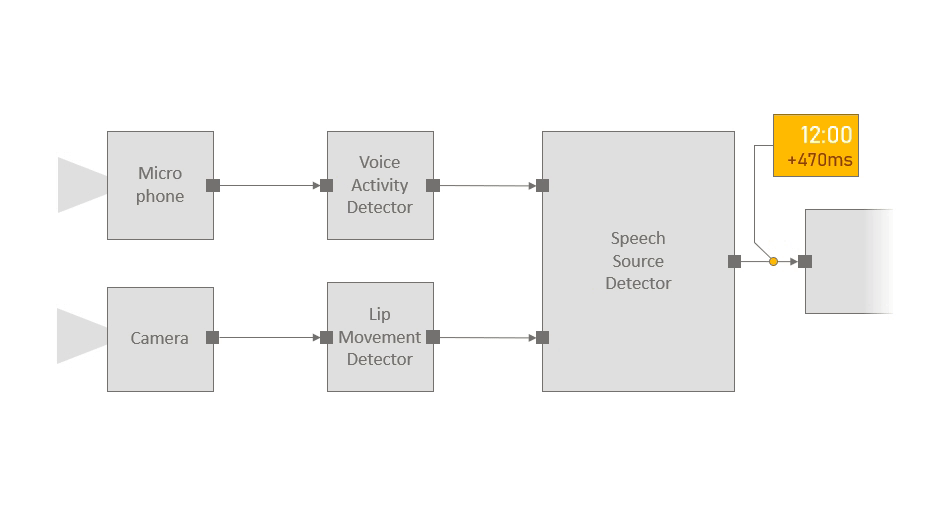
Consider for instance an example scenario in which we use a microphone and a camera to identify who is speaking (this might be a small part of a larger audio-visual application). The audio stream is processed by a voice activity detector, camera images are passed through a lip movement detector, and a speech source detector component fuses these signals to identify the current speaker, if any. The figure below shows the structure of the pipeline, and the code snippet illustrates the ease with which components can be instantiated and connected to each other:
// create pipeline
var p = Pipeline.Create();
// instantiate components
var microphone = new AudioSource(p);
var camera = new MediaSource(p);
…
// connect components
microphone.PipeTo(voiceActivityDetector);
camera.PipeTo(lipMovementDetector);
…
// run the pipeline
p.Run();
With Platform for Situated Intelligence, developers can easily instantiate and connect components to construct processing pipelines for multimodal, integrative AI systems. The above illustrates the structure of an example pipeline with corresponding code.
The GitHub repository for Platform for Situated Intelligence contains a growing ecosystem of components that wrap various sensors, including cameras, microphones, and depth sensors; processing technologies, including for imaging, audio, vision, speech, and language; components for running machine learning models and accessing cloud services such as Azure Cognitive Services; and more. Coupled with the simplicity of authoring application pipelines as illustrated above, this set of off-the-shelf components promotes reuse and enables fast prototyping. Of course, the framework also enables developers to easily write and use new components.
Infrastructure for working with multimodal streams
While component-based development is an important software engineering technique, the benefits and affordances provided by Platform for Situated Intelligence extend well beyond that: The framework provides a runtime and a modern streaming infrastructure that are specifically tailored and optimized for the needs of multimodal, integrative AI applications.
Once an application pipeline is created and the Run() method is invoked, the Platform for Situated Intelligence runtime takes charge of running the pipeline. The runtime carries messages on the streams and orchestrates component execution by scheduling message delivery. In the process, the runtime leverages pipeline parallelism and aims to make efficient use of CPU resources in a multi-core execution environment while providing graceful performance degradation under high load.
Apart from stringent performance requirements, multimodal applications also have a specific set of needs when it comes to reasoning about time and support for data synchronization and fusion. Oftentimes, a component may need to synchronize or fuse streams of data arriving on different pathways. In the example above, the speech source detector fuses results from the voice activity detector with results from the lip movement detector. The naive approach would be to pair the messages as they arrive at the fusion component. However, this may lead to incorrect results if the voice activity detector and lip movement detector components introduce different latencies. Proper coordination requires reasoning about latency, and in the absence of appropriate primitives and support for these operations, significant development effort is invested into resolving low-level synchronization and coordination problems.
Platform for Situated Intelligence addresses these challenges by making time a primary construct in the underlying streaming infrastructure. Each message created by a component carries with it an envelope that contains its creation time. In addition, the envelope contains an originating time, which is assigned by the initial sensor component and corresponds to the time when the initial signal associated with that message first entered the pipeline from the real world. As messages flow downstream through the application pipeline, this originating time is automatically propagated with each message, enabling all components to be aware of latency—that is, the exact amount of time that has elapsed between the message’s originating time and when it actually arrives at a given component in the application pipeline.
The originating time provides the basis for enabling proper synchronization and data fusion. In fact, the framework provides a comprehensive set of powerful operators for fusion, synchronization, interpolation, sampling, and windowing that together abstract lower-level details such as concurrency, buffering, and waiting for messages to arrive, allowing developers to focus on higher-level tasks.
In addition to reasoning about time, another core need in multimodal, integrative AI applications is support for data logging and experimentation. Multimodal applications are often characterized by a data-driven development cycle in which data is collected and used to tune and iteratively improve the application. The streaming infrastructure in Platform for Situated Intelligence supports high throughput data logging from the ground up. The runtime autogenerates efficient serialization code on the fly for persisting any data type to disk, minimizing developer efforts. The persistence system was designed to enable logging as much as possible, as fast as possible.
The persistence system also logs the timing information of each individual message, enabling pipeline replay scenarios. While developing complex integrative applications, it’s often time consuming and expensive to have to tune or debug the application by running it “live” over and over again. Using Platform for Situated Intelligence, developers can experiment with and execute pipelines in which some streams are “replayed” from a previously captured session on disk. The stream operators for data fusion and synchronization ensure reproducibility of results, and the pipeline can execute in replay mode in the same way it would when running from live sensor data.
We’ve introduced above only a few of the core concepts and affordances in the Platform for Situated Intelligence streaming infrastructure. The framework provides many additional features for working with streaming data, such as a rich language of stream operators for manipulating generic streams of data, various controls and throttling mechanisms for regulating flow on these streams, automated data cloning to ensure component isolation in a concurrent execution environment, support for constructing dynamic pipelines with structures that depend on the data flowing through them, and shared memory mechanisms and optimizations for minimizing garbage collection when the pipeline is at steady state. For a more comprehensive, technical look, see the documentation.
Tools for debugging and visualization
While multimodal, integrative AI applications that work with streaming data require specific infrastructure for running efficiently, their broader development cycle also has a specific set of needs that aren’t sufficiently addressed by the generic software tools available today. Debugging and maintenance, as well as development, are often data driven and involve multiple iterations of running the application, inspecting results, diagnosing, and fine-tuning. The ability to visualize the data generated by various components over time and inspect how components process particular data points is paramount. The ability to formulate analyses and queries over the data collected, annotate and interact directly with the data, and run batch processing tasks can further speed up development.
Our framework addresses several of these needs via Platform for Situated Intelligence Studio, a tool that enables multimodal, temporal data visualization, annotation, and processing. The video below shows the tool in action. A developer is visualizing data collected with a sample application in which an Azure Kinect device is used to detect and identify the objects a person is pointing to. This sample application determines the direction in which the person is pointing, intersects that ray with the point cloud from the depth map, projects the intersection point back into the RGB camera, crops an image around it, and runs a cloud service for object detection. The video shows various visualizers for the different data streams produced by this application.
A video of various visualizers in Platform for Situated Intelligence Studio.
With Platform for Situated Intelligence Studio, developers have at their disposal a wide array of visualizers—from simple numerical streams to audio, video, 3D objects, and histograms—to construct complex visualizations over data streams persisted by an application. Developers can easily navigate through the data, inspect values, and select and play back segments at varying speeds. The visualizers can be configured in a variety of ways, and developers can create and add custom visualizers for their own data types. The tool allows for easily compositing multiple visualizers in layouts that can be saved and shared. Furthermore, data visualizations can be done not only offline, based on the data persisted to disk, but also live, while the application is running. The visualization infrastructure also allows developers to utilize these visualizers in their own applications.
Other features include:
- Pipeline visualization: Developers can visualize and inspect the structure of the application pipeline and its behavior over time. This visualization can be configured to color the application pipeline based on various statistics of interest. For instance, applying a heatmap coloring to streams according to average message latency reveals which components in a pipeline are slow and at which point in time they slow down.
- Data annotation: Developers can construct temporal annotations based on custom annotation schemas. The annotated data is itself persisted as a stream, enabling a variety of semiautomatic data labeling and training scenarios.
- Data processing: Multiple sessions logged by an application over time can be grouped together into larger datasets. The tool supports loading developer-defined batch processing tasks and executing them over the data and makes it possible to visualize the results in conjunction with the original streams. For non-UI automation, these data processing functionalities are also available via a command line tool.
An invitation to use and contribute
There’s huge potential for interesting research and novel, useful applications in the space of multimodal, integrative AI systems. Significant advances have been made in recent years by utilizing dataset-driven approaches to develop ever more accurate perceptual technologies. However, given the challenges involved and the lack of adequate foundations and tools, it’s no surprise progress has been slow in bringing these technologies together in end-to-end intelligent systems that are able to perceive, reason about, and act in the world. Platform for Situated Intelligence was built to accelerate this progress and foster more innovation and research in this space.
We’ve made the framework open source, as we believe success in this space comes with bringing together different expertise and experiences and establishing an open, thriving ecosystem of components through which we can more easily reuse each other’s work. The framework is not just open source, but also designed to be open and extensible. It has built-in capabilities to easily connect with other frameworks and ecosystems like Robot Operating System (ROS), Python, Unity, and JavaScript and to enable and leverage the use of custom, third-party data formats, importers, and visualizers.
Several early adopters have already successfully used the framework in a variety of different settings and have provided useful feedback; we’ve included some of their testimonials below. We’re looking forward to continuing to engage with the growing community around this project on the GitHub repository and to working together to further improve its capabilities.
Testimonials
“Platform for Situated Intelligence is a valuable asset for researchers in human-machine interaction, allowing us to focus on research rather than worrying about the processing pipeline. It has enabled us to rapidly develop OmniSense, a multimodal acquisition and human behavior sensing toolkit, providing a solid base for multimodal synchronization and processing.”
Mohammad Soleymani, Research Assistant Professor, University of Southern California
“Platform for Situated Intelligence has solved one of our biggest challenges: multimodal data collection. We have several robot platforms, each of which has various sensors that we needed to record with timing information, and the framework really helped make that possible. It was easy to set up, and even though most of our work is done in Python, the interop functionality really makes Platform for Situated Intelligence flexible to work with multiple programming languages.”
Casey Kennington, Assistant Professor, Boise State
“Platform for Situated Intelligence enabled us to extend our Companion cognitive architecture with speech and video inputs, providing a software substrate that let us focus on higher-level issues. This has enabled us to, for example, deploy a kiosk in the computer science department that combines Companion analogical Q/A capabilities with Platform for Situated Intelligence to answer visitors’ questions.”
Kenneth D. Forbus, Walter P. Murphy Professor of Computer Science, Northwestern University
“My research on multimodal behavior understanding requires the development of complex systems that can synchronously utilize data streams from multiple sensors. Platform for Situated Intelligence provides great support for this challenging engineering task through efficient mechanisms for data stream merging and remoting. In turn, I can focus my effort on research and development of system components that model the behaviors captured in these data streams.”
Kalin Stefanov, Research Associate, University of Southern California
If you’d like to learn more and get started with Platform for Situated Intelligence, the GitHub repository contains a variety of detailed tutorials, code samples with walk-throughs, and more documentation. For ease of use, the framework, including all of its components, is available as both source code and via NuGet packages. We invite anyone who’s interested to join the open-source project and help us evolve it. No contribution is too small, from simply using the framework and filing issues and bugs, to writing and releasing your own new components, to developing new features. We hope you give Platform for Situated Intelligence a try and find that it accelerates your own research or development work!
Acknowledgments
Platform for Situated Intelligence is the work of a broader team of engineers and researchers whose contributions range from the design and development of the framework to providing guidance, support, and feedback. We’d like to thank the current development team—Stuart Dent, Ashley Feniello, and Nick Saw—as well as Mike Barnett, Debadeepta Dey, John Elliott, Don Gillett, Eric Horvitz, Mihai Jalobeanu, Sean Kuno, Anne Loomis Thompson, Daniel McDuff, Lev Nachmanson, Kael Rowan, Patrick Sweeney, and Andy Wilson. We also thank our internal and external early adopters for their feedback and contributions.
Join Senior Principal Researcher Dan Bohus for an even deeper dive into the capabilities of Platform for Situated Intelligence, including a demo on writing an application using the framework. Register now for his September 10 webinar/live Q&A.
The post Platform for Situated Intelligence: An open-source framework for multimodal, integrative AI appeared first on Microsoft Research.