
This post has been republished via RSS; it originally appeared at: Microsoft Research.
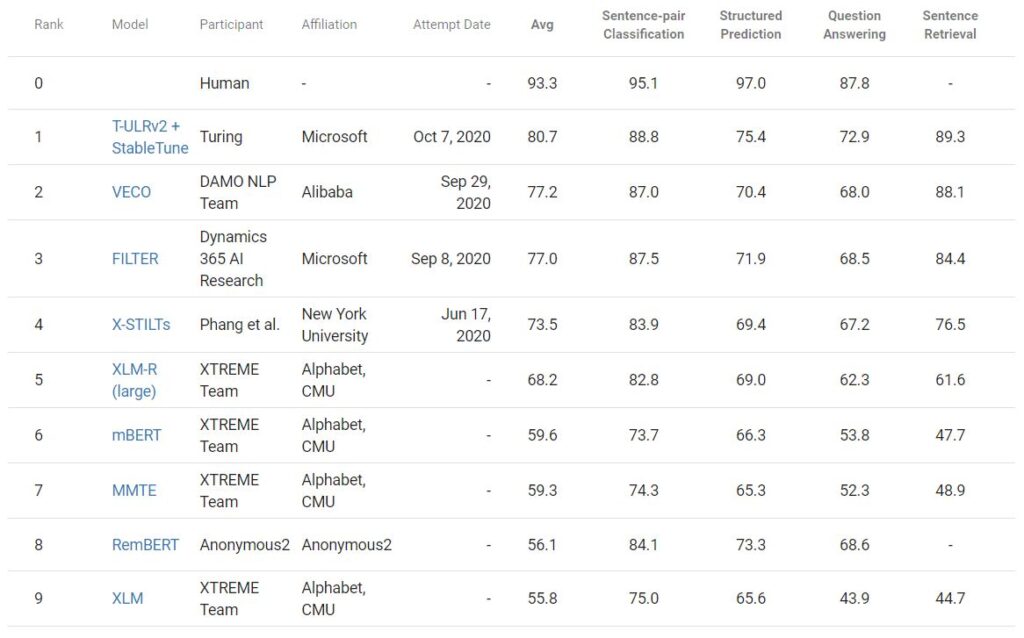
Today, we are happy to announce that Turing multilingual language model (T-ULRv2) is the state of the art at the top of the Google XTREME public leaderboard. Created by the Microsoft Turing team in collaboration with Microsoft Research, the model beat the previous best from Alibaba (VECO) by 3.5 points in average score. To achieve this, in addition to the pretrained model, we leveraged “StableTune,” a novel multilingual fine-tuning technique based on stability training. Other models on the leaderboard include XLM-R, mBERT, XLM and more. One of the previous best submissions is also from Microsoft using FILTER.
Universal Language Representation
The Microsoft Turing team has long believed that language representation should be universal. In this paper, published in 2018, we presented a method to train language-agnostic representation in an unsupervised fashion. This kind of approach would allow for the trained model to be fine-tuned in one language and applied to a different one in a zero-shot fashion. This would overcome the challenge of requiring labeled data to train the model in every language. Since the publication of that paper, unsupervised pretrained language modeling has become the backbone of all NLP models, with transformer-based models at the heart of all such innovation.

As part of Microsoft AI at Scale, the Turing family of NLP models have been powering the next generation of AI experiences in Microsoft products. The Turing Universal Language Representation (T-ULRv2) model is our latest cross-lingual innovation, which incorporates our recent innovation of InfoXLM, to create a universal model that represents 94 languages in the same vector space. In a recent blog post, we discussed how we used T-ULR to scale Microsoft Bing intelligent answers to all supported languages and regions. The same model is being used to extend Microsoft Word Semantic Search functionality beyond the English language and to power Suggested Replies for Microsoft Outlook and Microsoft Teams universally. We will have these universal experiences coming to our users soon.

These real products scenarios require extremely high quality and therefore provide the perfect test bed for our AI models. As a result, most of our models are near state of the art in accuracy and performance on NLP tasks.
Spotlight: Webinar series

Microsoft research webinars
XTREME Benchmark
The Cross-lingual TRansfer Evaluation of Multilingual Encoders (XTREME) benchmark covers 40 typologically diverse languages that span 12 language families, and it includes 9 tasks that require reasoning about different levels of syntax or semantics. The languages in XTREME are selected to maximize language diversity, coverage in existing tasks, and availability of training data.
The tasks included in XTREME cover a range of paradigms, including sentence text classification, structured prediction, sentence retrieval and cross-lingual question answering. Consequently, for models to be successful on the XTREME benchmarks, they must learn representations that generalize to many standard cross-lingual transfer settings.
For a full description of the benchmark, languages, and tasks, please see XTREME: A Massively Multilingual Multi-task Benchmark for Evaluating Cross-lingual Generalization.
T-ULRv2: Data, Architecture, and Pretraining
Turing Universal Language Representation (T-ULRv2) is a transformer architecture with 24 layers and 1,024 hidden states, with a total of 550 million parameters. T-ULRv2 pretraining has three different tasks: multilingual masked language modeling (MMLM), translation language modeling (TLM) and cross-lingual contrast (XLCo). The objective of the MMLM task, also known as Cloze task, is to predict masked tokens from inputs in different languages. T-ULRv2 uses a multilingual data corpus from web that consists of 94 languages for MMLM task training. Like MMLM, TLM task is also to predict masked tokens, but the prediction is conditioned on concatenated translation pairs. For example, given a pair of sentences in English and French, the model can predict the masked English token by either attending to surrounding English tokens or to its French translation. This helps the model align representations in different languages.
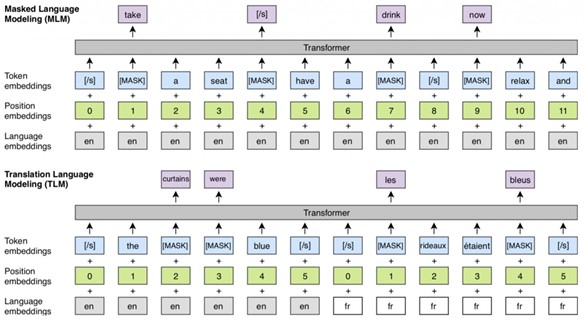
XLCo also uses parallel training data. The objective of the task is to maximize the mutual information between the representations of parallel sentences. Unlike maximizing token-sequence mutual information as in MMLM and TLM, XLCo targets cross-lingual sequence-level mutual information. T-ULRv2 uses translation parallel data with 14 language pairs for both TLM and XLCo tasks.
The loss function for XLCo is as follows:
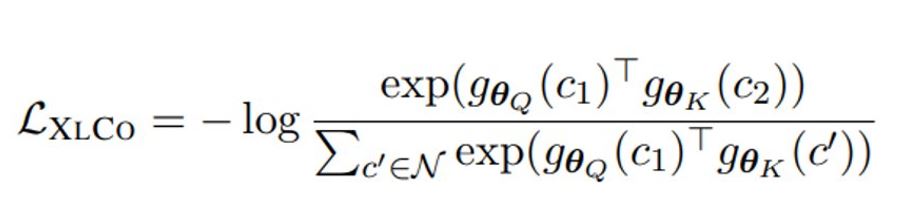
This is subsequently added to the MMLM and TLM loss to get the overall loss for the cross-lingual pretraining:
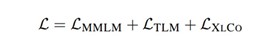
T-ULRv2: Release Information
At Microsoft Ignite 2020, we announced that Turing models will be made available for building custom applications as part of a private preview. T-ULRv2 will also be part of this program. If you are interested in learning more about this and other Turing models, you can submit a request here. We are closely collaborating with Azure Cognitive Services to power current and future language services with Turing models. Existing Azure Cognitive Services customers will automatically benefit from these improvements through the APIs.
Democratizing Our AI Experiences
At Microsoft, globalization is not just a research problem. It is a product challenge that we must face head on. Windows ships everywhere in the world. Microsoft Office and Microsoft Bing are available in over 100 languages across 200 regions. We have customers in every corner of the planet, and they use our products in their native languages. To truly democratize our product experience to empower all users and efficiently scale globally, we are pushing the boundaries of multilingual models. The result is language-agnostic representations like T-ULRv2 that improve product experiences across all languages.
The Microsoft Turing team welcomes your feedback and comments and looks forward to sharing more developments in the future.
The post Microsoft Turing Universal Language Representation model, T-ULRv2, tops XTREME leaderboard appeared first on Microsoft Research.