
This post has been republished via RSS; it originally appeared at: Microsoft Research.
Editor’s note: This post and its research are the result of the collaborative efforts of our team—MIT PhD students Andrew Ilyas and Logan Engstrom, Senior Researcher Sai Vemprala, MIT professor Aleksander Madry, and Partner Research Manager Ashish Kapoor.
Many of the items and objects we use in our daily lives were designed with people in mind. In October, the Reserve Bank of Australia put out into the world its redesigned $100 banknote. Some design elements remained the same—such as color and size, characteristics people use to tell the difference between notes—while others changed. New security features to help protect against fraud were added as were raised bumps for people who are blind or have low vision. Good design enables intended audiences to easily acquire information and act on it.
Modern computer vision systems take similar cues—floor markings direct a robot’s course, boxes in a warehouse signal a forklift to move them, and stop signs alert a self-driving car to, well, stop. The neural networks underlying these systems might understand the features that we as humans find helpful, but they might also understand different features even better. In scenarios in which system operators and designers have a level of control over the target objects, what if we designed the objects in a way that makes them more detectable, even under conditions that normally break such systems, such as bad weather or variations in lighting?
We introduce a framework that exploits computer vision systems’ well-known sensitivity to perturbations of their inputs to create robust, or unadversarial, objects—that is, objects that are optimized specifically for better performance and robustness of vision models. Instead of using perturbations to get neural networks to wrongly classify objects, as is the case with adversarial examples, we use them to encourage the neural network to correctly classify the objects we care about with high confidence.
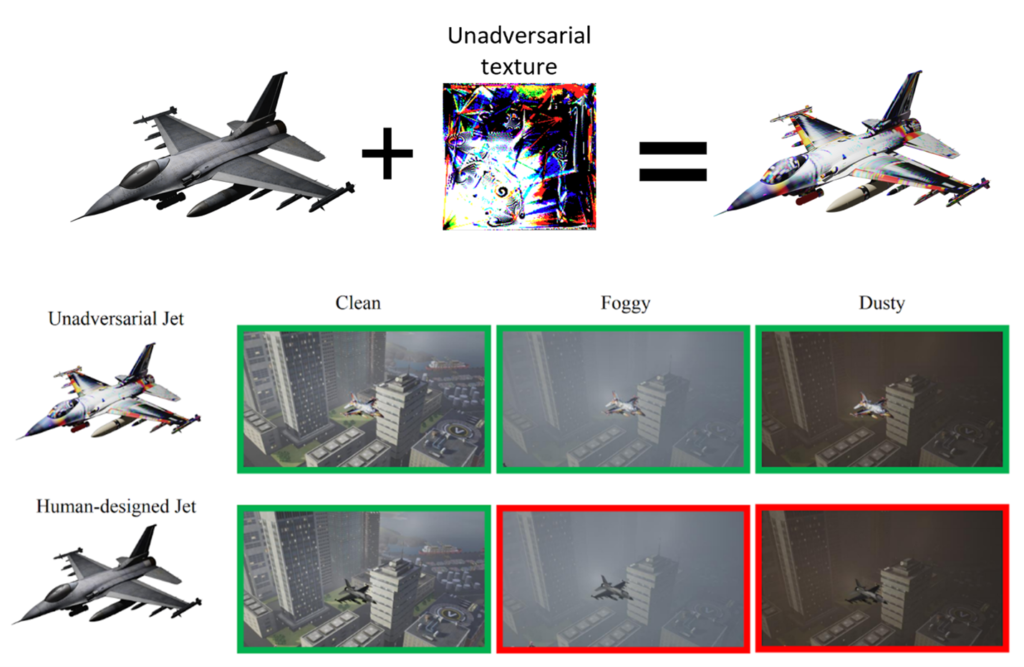
We show that such optimization of objects for vision systems significantly improves the performance and robustness of these systems, even to unforeseen data shifts and corruptions. An example of this is demonstrated above in Figure 1, where we modify a jet with a pattern optimized to enable image classifiers to more robustly recognize the jet under various weather conditions: while both the original jet and its unadversarial counterpart are correctly classified in normal conditions, only the unadversarial jet is recognized when corruptions like fog or dust are added. We present the details of this research in our paper “Unadversarial Examples: Designing Objects for Robust Vision.”
Why design objects for neural networks?
The fragility of computer vision systems makes reliability and safety a real concern when deploying these systems in the real world. For example, a self-driving car’s stop-sign detection system might be severely affected in the presence of intense weather conditions such as snow or fog. While techniques such as data augmentation, domain randomization, and robust training might seem to improve the performance of such systems, they don’t typically generalize well to corrupted or otherwise unfamiliar data that these systems face when deployed.

Microsoft research webinars
We were motivated to find another approach by scenarios in which system designers and operators not only have control of the neural network itself, but also have some degree of control over the objects they want their model to recognize or detect—for example, a company that operates drones for delivery or transportation. These drones fly from place to place, and an important task for the system is landing safely at the target locations. Human operators may manage the landing pads at these locations, as well as the design of the system, presenting an opportunity to improve the system’s ability to detect the landing pad by modifying the pad itself.
Designing robust objects for vision
Our starting point in designing robust objects for vision is the observation that modern vision models suffer from a severe input sensitivity that can, in particular, be exploited to generate so-called adversarial examples: imperceptible perturbations of the input of a vision model that break it. Adversarial examples can potentially be used to intentionally cause system failures; researchers and practitioners use these examples to train systems that are more robust to such attacks. These perturbations are typically constructed by solving the following optimization problem, which maximizes the loss of a machine learning model with respect to the input:
\(\delta_{adv} = \arg\max_{\delta \in \Delta} L(\theta; x + \delta, y),\)
where \(\theta\) is the set of model parameters; \(x\) is a natural image; \(y\) is the corresponding correct label; \(L\) is the loss function used to train \(\theta\) (for example, cross-entropy loss in classification contexts); and \(\Delta\) is a class of permissible perturbations. In our work, we aim to convert this unusually large input sensitivity from a weakness into a strength. That is, instead of creating misleading inputs, as shown in the above equation, we demonstrate how to optimize inputs that bolster performance, resulting in these unadversarial examples, or robust objects. This is done by simply solving the following optimization problem:
\(\delta_{unadv} = \arg\min_{\delta \in \Delta} L(\theta; x + \delta, y).\)
In our research, we explore two ways of designing robust objects: via an unadversarial patch applied to the object or by unadversarially altering the texture of the object (Figure 2). Both ways require the above optimization algorithm to iteratively optimize the patch or texture with \(\Delta\) being the set of perturbations spanning the patch or texture. Note that we start with a randomly initialized patch or texture.

- Unadversarial patch: To train an unadversarial patch, at each iteration, we sample natural image-label pairs (\(x\), \(y\)) from the training set of the task at hand and place the patch onto the image with random orientation and position.
- Unadversarial texture: To train an unadversarial texture, on the other hand, requires a 3D mesh of the object we’d like to design, as well as a set of background images. At each iteration, we use a renderer such as Mitsuba to map the object’s corresponding texture and overlay the rendering onto a random background image.
In both cases, the resulting image is passed through a computer vision model, and we run projected gradient descent (PGD) on the end-to-end system to solve the above equation and optimize the texture or patch to be unadversarial. The resulting texture or patch has a unique pattern, as shown in Figure 1, that is then associated with that class of object. You can think of these patterns as fingerprints generated from the model that help the model detect that specific class of object better.
It turns out that this simple technique is general enough to create robust inputs for various vision tasks. In our work, we evaluate our method on the standard benchmarks CIFAR-10 and ImageNet and the robustness-based benchmarks CIFAR-10-C and ImageNet-C and show improved efficacy. We also compare them to baselines such as QR codes.
Does this work in practice?
To further study the practicality of our framework, we go beyond benchmark tasks and perform tests in a high-fidelity 3D simulator, deploy unadversarial examples in a simulated drone setting, and ensure that the performance improvements we observe in the synthetic setting actually transfer to the physical world.
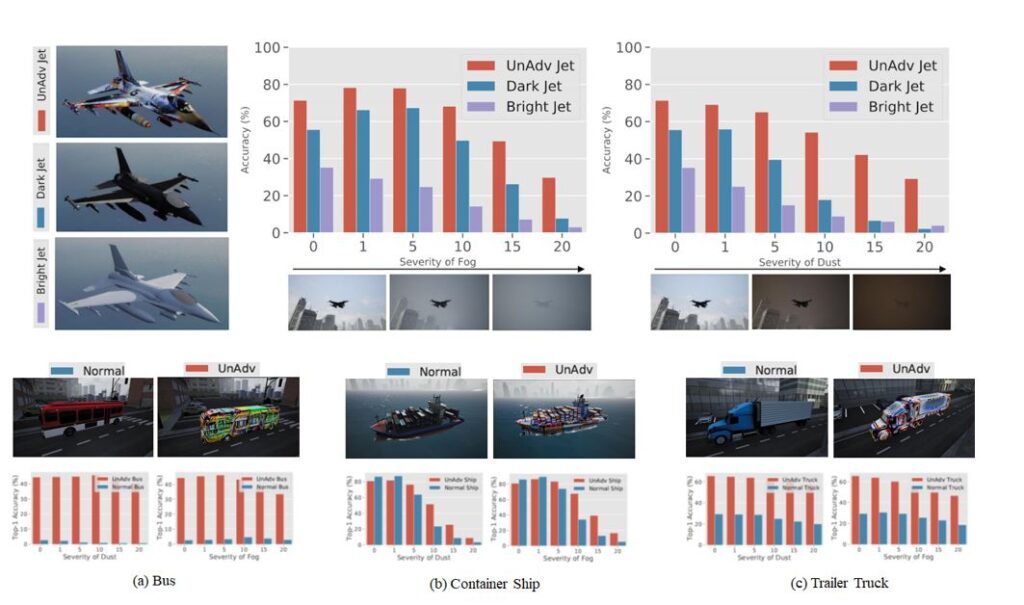
- Recognizing objects in a high-fidelity simulator: In this experiment, we demonstrate that our method works well in the more practical scenario of recognizing 3D objects in a high-fidelity simulator. We import 3D objects into Microsoft AirSim and generate unadversarial textures for each. Then, we evaluate the performance of a pre-trained ImageNet model on recognizing each of these objects under various weather conditions. Overall, we observe that the unadversarial objects, including a jet and trailer truck, are more easily recognized than their human-designed counterparts in foggy and dusty conditions, as shown in Figure 3.
- Localization for (simulated) drone landing: We take the realism of our simulations a step further by training patches for use in a simulated drone landing task. Here, the drone has a pre-trained regression model that localizes the landing pad. Our goal is to optimize an unadversarial drone pad to help this drone’s regression model in localizing that pad. Figure 4 depicts an example landing pad localization task and the resulting performance on that task. Usage of an unadversarial landing pad makes the drone landing consistently more reliable.

- Physical-world unadversarial examples: Finally, we study unadversarial examples in the physical world. To this end, we print out unadversarial patches and place them on top of real-world objects. We then classify these object-patch pairs and the corresponding object-only baselines. We find that the unadversarial patches consistently improve performance, even when the object orientations are unusual (Figure 5).

Overall, we’ve seen that it’s possible to design objects that boost the performance of computer vision models, even under strong and unforeseen corruptions and distribution shifts. We view our results as a promising route toward increasing reliability and out-of-distribution robustness of computer vision models.
The post Unadversarial examples: Designing objects for robust vision appeared first on Microsoft Research.