
This post has been republished via RSS; it originally appeared at: Microsoft Research.
Pretrained vision models accelerate deep learning research and bring down the cost of performing computer vision tasks in production. By pretraining one large vision model to learn general visual representation of images, then transferring the learning across multiple downstream tasks, a team achieves competitive performance at a fraction of the cost when compared to collecting new data and training a new model for each task. Further fine-tuning of the pretrained model with task-specific training data often yields even higher performance than training specialized models.
Microsoft Vision Model ResNet-50 is a large pretrained vision model created by the Multimedia Group at Microsoft Bing. The model is built using the search engine’s web-scale image data in order to power its Image Search and Visual Search. We are excited to announce that we are making Microsoft Vision Model ResNet-50 publicly available today.
| Microsoft Vision Model | Google Big Transfer | OpenAI CLIP | PyTorch ResNet-50 | |
| CIFAR-10 | 92.64 | 92.51 | 87.85 | 82.23 |
| CIFAR-100 | 76.05 | 79.84 | 67.02 | 61.36 |
| STL-10 | 98.10 | 98.71 | 97.20 | 96.32 |
| SVHN | 72.64 | 64.22 | 64.33 | 52.05 |
| CUB | 82.20 | 82.75 | 68.38 | 38.79 |
| Flowers-102 | 99.28 | 99.38 | 95.23 | 77.62 |
| ImageNet | 73.85 | 72.83 | 57.00 | 75.63 |
| Average | 84.97 | 84.32 | 76.72 | 69.14 |
We evaluate Microsoft Vision Model ResNet-50 against the state-of-the-art pretrained ResNet-50 models and the baseline PyTorch implementation of ResNet-50, following the experiment setup of OpenAI CLIP. Linear probe is a standard evaluation protocol for representation learning in which a linear classifier is trained on frozen embeddings of the pretrained vision model for each benchmark.
To achieve the state-of-the-art performance in a cost-sensitive production setting, Microsoft Vision Model ResNet-50 leverages multi-task learning and optimizes separately for four datasets, including ImageNet-22k, Microsoft COCO, and two web-supervised datasets containing 40 million image-label pairs collected from image search engines.
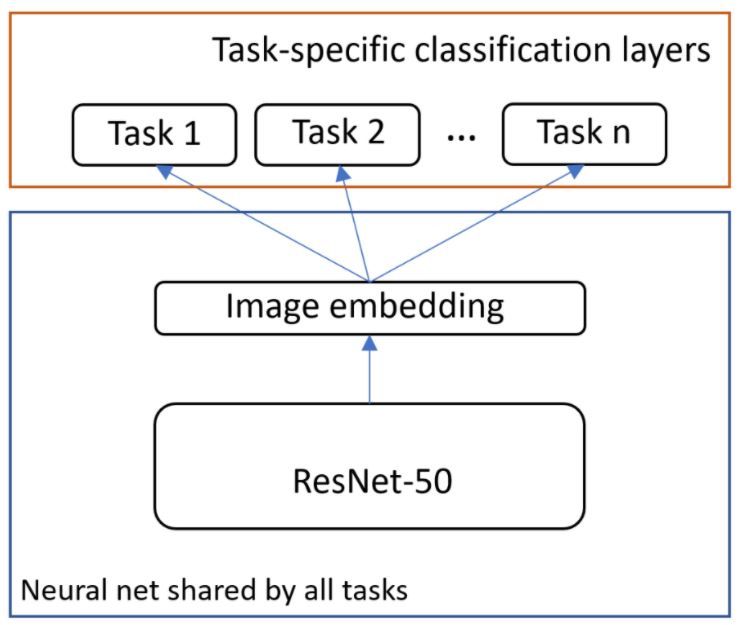
We chose to use multi-task learning with hard parameter sharing (see figure above). Single neural networks will optimize each classification problem at the same time. By using tasks of varied sizes—up to 40 million images with 100,000 different labels from web-supervised sources—Microsoft Vision Model ResNet-50 can achieve high robustness and good transferability to different domains.
Spotlight: Microsoft research newsletter

Microsoft Research Newsletter
During training, images from each dataset are sampled proportionally to the size of the datasets. This approach promotes larger datasets at first, but once optimization flattens, the optimizer needs to look for improvements to smaller datasets without downgrading the performance of the larger ones. As a result, final accuracy scores for each of the datasets are competitive with specialized models trained on each specific dataset.
Dive deeper into Microsoft Vision Model ResNet-50

You can get your hands on Microsoft Vision Model ResNet-50 by visiting https://aka.ms/microsoftvision. On this webpage, you will find a description of how to install and use the model to encode images into embedding vectors. We are also hosting a public webinar about our model on February 25 at 10 AM PT. Part of the webinar will be a demo of applying the model to example computer vision tasks, and there will be a live Q&A session at the end. You can learn more and register for the webinar at its registration page.
Acknowledgments
Microsoft Vision Model ResNet-50 is one in a family of world-class computer vision models we’ve built at Microsoft Bing Multimedia Group. We thank Mark Bolin, Ravi Yada, Kun Wu, Meenaz Merchant, Arun Sacheti, and Jordi Ribas for enabling this work. If the opportunity to build pioneering computer vision models excites you, visit our career page to learn about our openings.
The post Microsoft Vision Model ResNet-50 combines web-scale data and multi-task learning to achieve state of the art appeared first on Microsoft Research.