
This post has been republished via RSS; it originally appeared at: Microsoft Research.

The purpose of the Association for the Advancement of Artificial Intelligence, according to its bylaws, is twofold. The first is to promote research in the area of AI, and the second is to promote the responsible use of these types of technology. The result was a 35th AAAI Conference on Artificial Intelligence (AAAI-21) schedule that broadens the possibilities of AI and is heavily reflective of a pivotal time in AI research when experts are asking bigger questions about how best to responsibly develop, deploy, and integrate the technology.
- Event Microsoft at AAAI 2021
Microsoft and its researchers have been pursuing and helping to foster responsible AI for years—developing innovative AI ethics checklists and fairness assessment tools like Fairlearn, establishing the Aether Committee to make principle-based recommendations, and laying out guidelines for human-AI interaction, to name only a few of the milestones in this area.
As a natural extension, researchers from Microsoft are presenting papers at this year’s AAAI that show the wide net they’re casting when it comes to developing responsible AI and using it for applications that do good. In “How Linguistically Fair are Multilingual Pre-Trained Language Models?,” researchers explore the fairness of current large multilingual language models across different languages. More specifically, they uncover how choices have been made about which models are fair and offer strategies for how these decision processes can be improved. Another paper demonstrates how AI can impact both specific industries and global challenges. In “Where there’s Smoke, there’s Fire: Wildfire Risk Predictive Modeling via Historical Climate Data,” researchers reexamine how AI can be used to predict wildfires by taking historical, climate, and geospatial data into account to improve modeling.
The below selection of AAAI-accepted papers showcases specific advances with the potential to have far-reaching impact. AI that empowers all people is the end goal, whether that be through better communication, better protection of their privacy, or better optimization of everyday processes in specific fields.
For more on what Microsoft, a silver sponsor of the conference, and its researchers are undertaking when it comes to moving AI forward, explore more at the Microsoft at AAAI 2021 page.
Policy optimization using reinforcement learning for universal trading
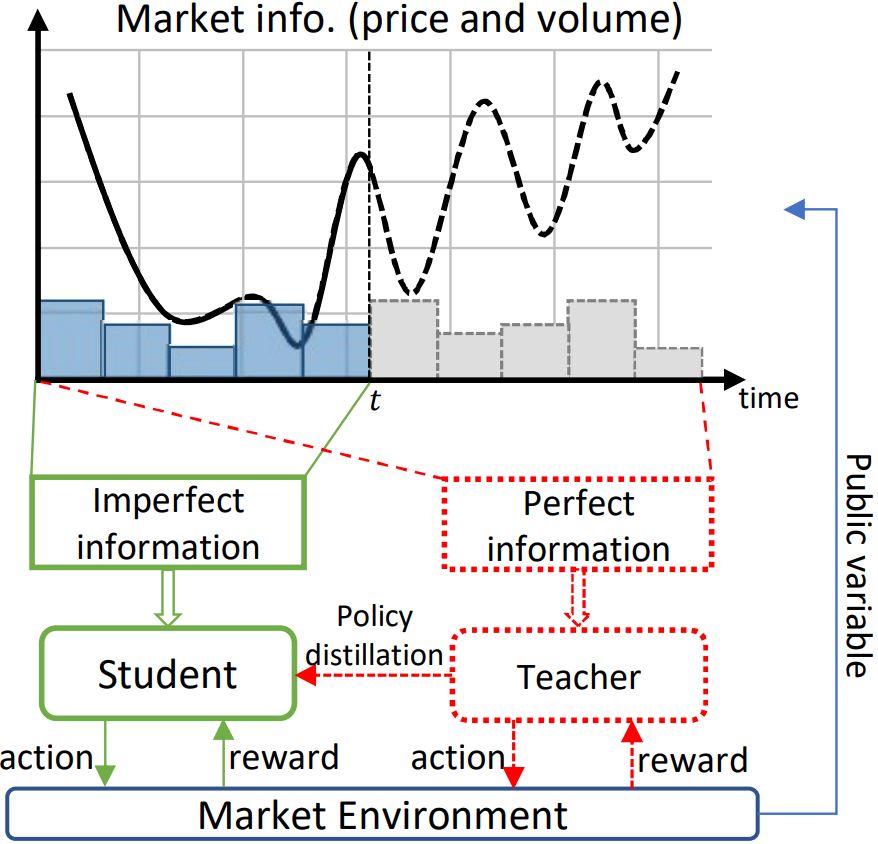
In a nutshell: Reinforcement learning for order execution in quantitative investment.
Going deeper: The paper “Universal Trading for Order Execution with Oracle Policy Distillation” proposes a novel universal trading policy optimization framework for order execution in quantitative finance. It bridges the gap between noisy yet imperfect market states and optimal action sequences for order execution. Particularly, on one side, this framework leverages a policy distillation method that can better guide the learning of the common policy toward practically optimal execution by an oracle teacher with perfect information to approximate the optimal trading strategy. On the other side, a universal trading policy has been derived from the market data of various instruments, which is more training effective and more general to trade for different instruments.
Potential reach: This work can create an impact in the field of trading optimization in quantitative financial investment. The proposed universal learning-to-trade paradigm could substantially advance trading optimization with potentially significant profit gaining in order execution. The code is available in the Qlib project on GitHub.
First of its kind: To the best of the researchers’ knowledge, this is the first work to employ policy distillation in reinforcement learning to bridge the gap between imperfect noisy data and optimal action sequences. Moreover, the work shows that direct policy optimization has a great advantage over the traditional model-based financial methods and value-based model-free reinforcement learning methods.
The people and organizations involved: Kan Ren, Weiqing Liu, Dong Zhou, Jiang Bian, and Tie-Yan Liu from Microsoft Research Asia; Yuchen Fang, Weinan Zhang, and Yong Yu from Shanghai Jiao Tong University
Additional resources and related work:

Microsoft research webinars
UWSpeech: A speech-to-speech translation system that doesn’t rely on written text
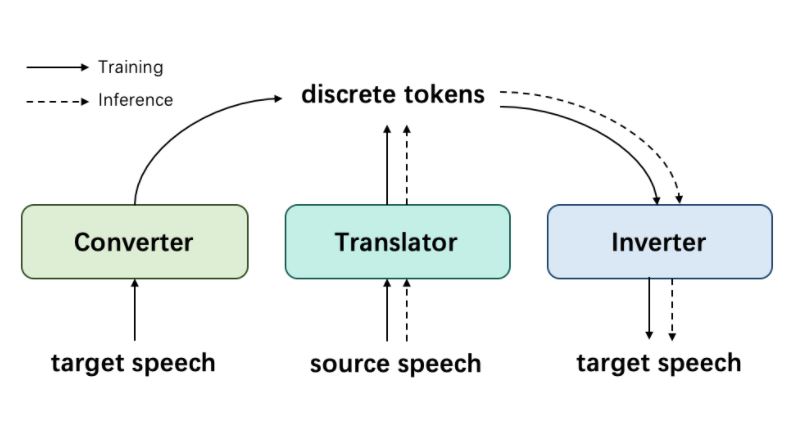
In a nutshell: Want a translation system for languages with no written text? UWSpeech is your choice.
Going deeper: Existing speech-to-speech translation systems rely on the text of target language, and these existing systems can’t be applied to unwritten target languages (languages without written text or phonemes). In the paper “UWSpeech: Speech to Speech Translation for Unwritten Languages,” researchers developed UWSpeech, a translation system for unwritten languages. UWSpeech converts target unwritten speech into discrete tokens with a converter. It then translates source-language speech into target discrete tokens with a translator and, finally, synthesizes target speech from target discrete tokens with an inverter. The researchers propose a method called XL-VAE in UWSpeech to enhance vector quantized variational autoencoder (VQ-VAE) with cross-lingual (XL) speech recognition, in order to train the converter and inverter of UWSpeech jointly.
Potential reach: This research sits broadly within cross-lingual speech translation, which can impact many scenarios where one spoken language needs to be translated into another. Conversations, lectures, international travel, and conferences are all examples where UWSpeech could be utilized. UWSpeech can also help to preserve unwritten languages spoken by a small amount of people.
Extended applications: Although this paper focuses on how UWSpeech can be applied to speech-to-speech translation, it can also be used to improve text-to-speech and speech-to-text translation, showing promising results in both areas. See the paper for more details.
The people and organizations involved: Xu Tan, Tao Qin, and Tie-Yan Liu from the Machine Learning Group at Microsoft Research Asia; Chen Zhang, Yi Ren, and Kejun Zhang from Zhejiang University
Additional resources and related work:
- More recent speech research in collaboration with Microsoft Research Asia
- Deep and Reinforcement Learning Group
- Machine Learning Group
- Microsoft Research Asia
Investigating how data augmentation affects privacy in deep learning models
In a nutshell: Watch out! Data augmentation could actually hurt privacy. Stronger membership inference attack reveals where we need to improve protection.
Going deeper: The paper “How Does Data Augmentation Affect Privacy in Machine Learning?” challenges a common belief that data augmentation can prevent overfitting and hence protect the model from leakage of individual data points. The researchers developed membership inference algorithms that employ augmented instances and achieve state-of-the-art success rates of attacking well-generalized models trained with data augmentation, showing that privacy risk in these deep learning models could be greater than previously thought. Revealing this vulnerability encourages future development of techniques to strengthen the privacy protections of data augmentation as a training method.
Potential reach: The new proposed membership inference algorithms can better evaluate the privacy risk of a model and can hence help prevent other privacy attacks.
Toward better privacy: The end goal is to make a privacy guarantee in real-world machine learning tasks practical.
The people and organizations involved: Huishuai Zhang, Wei Chen, and Tie-Yan Liu of Microsoft Research Asia; Da Yu, intern at Microsoft Research Asia at the time of the work and student at Sun Yat-Sen University; Jian Yin, Professor at Sun Yat-Sen University
Additional resources and related work:
- Paper: “Do Not Let Privacy Overbill Utility: Gradient Embedding Perturbation For Private Learning”
- Paper: “Gradient Perturbation is Underrated for Differentially Private Convex Optimization”
- Machine Learning Group
- Microsoft Research Asia
Modeling speech and noise simultaneously for state-of-the-art speech enhancement
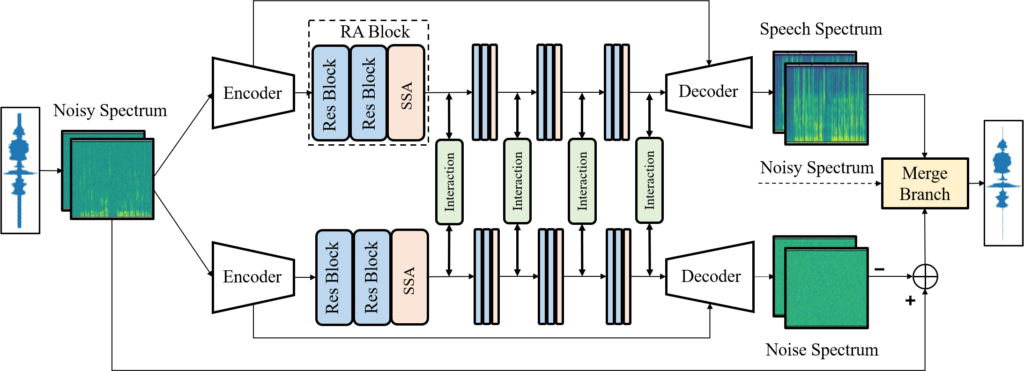
In a nutshell: A two-branch convolutional neural network approach to interactive speech and noise modeling for speech enhancement.
Going deeper: Mainstream deep learning–based speech enhancement mainly predicts speech only, ignoring the characteristics of background noises. However, traditional speech enhancement methods mostly go the opposite way, that is, they model noises with an assumption on noise distributions. The result is that their generalization capability is limited. In the paper “Interactive Speech and Noise Modeling for Speech Enhancement,” researchers propose the SN-Net, an interactive speech and noise modeling framework for speech enhancement, where speech and noise are simultaneously modeled in a two-branch deep neural network. Several interactions are introduced to help speech estimation benefit from noise prediction, and vice versa. As it’s challenging to model noises because of the diverse noise types, self-attention is employed in modeling both speech and noise. The SN-Net outperforms the state of the art by a large margin on several public datasets.
Potential reach: This technology can be widely impactful in applications where speech clarity is important, including video recordings, online meetings, and virtual lessons. The research can naturally be extended to use with the speaker separation task (see paper for more on this).
State of the art across multiple benchmarks: The researchers tested SN-Net against state-of-the-art models on Voice Bank + DEMAND and the Deep Noise Suppression (DNS) challenge dataset. Additionally, researchers conducted a two-speaker speech separation experiment on the TIMIT corpus, and SN-Net outperforms Conv-TasNet, the state-of-the-art method, for SDR (signal-to-distortion ratio) improvement and Perceptual Evaluation of Speech Quality (PESQ). See the paper for a detailed breakdown of these tests.
The people and organizations involved: Xiulian Peng and Yan Lu from the Media Computing Group at Microsoft Research Asia; Sriram Srinivasan from Microsoft; and Chengyu Zheng and Yuan Zhang from Communication University of China
Additional resources and related work:
The post AAAI 2021: Accelerating the impact of artificial intelligence appeared first on Microsoft Research.