
This post has been republished via RSS; it originally appeared at: Microsoft Research.

Editor’s note: This research was conducted by Sai Vemprala, Senior Researcher, and Ashish Kapoor, Partner Researcher, of Microsoft Research along with Sami Mian, who was a PhD Researcher at the University of Pittsburgh and an intern at Microsoft at the time of the work.
Autonomous systems are composed of complex perception-action loops, where observations of the world need to be processed in real time to result in safe and effective actions. A significant amount of research has focused on creating perception and navigation algorithms for such systems, often using visual data from cameras to reason about which action to take depending on the platform and task at hand.
While there have been a lot of improvements in how this reasoning is performed, and how information can be extracted efficiently from camera imagery, there are a number of challenges when it comes to achieving autonomous systems that receive and process information both accurately and quickly enough for applications in real-world scenarios. These challenges include the speed limitations posed by commercial off-the-shelf cameras, data that is unseen during training of vision models, and the limitations of sensors in RGB camera sensors.
In our recent paper, “Representation Learning for Event-based Visuomotor Policies,” we take these challenges head on by using ideas in unsupervised representation learning combined with the power of recent camera technology called neuromorphic or event cameras. Pairing the data streams from low-level sensors like event cameras with reinforcement learning leads to fast, instinctive, and redundant perception-action loops, which could result in autonomous systems that are able to reason quickly and safely about their surroundings. We also conduct tests of our new pipeline in Microsoft AirSim using a new feature that allows for simulating the output of an event camera. A codebase to train and evaluate models based on our work can be found at our GitHub repository.
Addressing current limitations of speed and sensors with event cameras
The current pipeline suffers from one major limitation: commonly used cameras are not very fast. Commercial off-the-shelf cameras that are typically found on board small robots (such as drones) usually capture images at rates of 30–60 times a second. When a machine learning algorithm seeks to reason from this camera data and compute an action, it can only do so at a rate that’s equal to or below the speed of the camera. This poses a problem when we consider applications where fast, agile movements are important, such as drone racing and fast collision avoidance.
There is another angle to this discussion: the sensor itself. Computer vision predominantly has focused on RGB cameras, as that is the modality with which humans generally perceive the world and is assumed to be a natural observation of the world. Yet humans possess a vastly more complicated processing mechanism that turns incident light into a set of simple signals for the brain to operate on. The retina takes over a large part of this processing and only transmits a small amount of relevant information to the brain. In perception-action loops, we ask machine learning to act as both the brain and the retina to complete this task. This creates inefficiencies in terms of training time and data requirements. By requiring machine learning to only interpret simpler signals, we can train models that behave in a more generalized way.
Inspired by the retina, the event camera is a new type of sensor that has recently become of interest in autonomous systems—primarily due to how fast it captures data. In contrast to normal cameras, event cameras contain a 2D grid of pixels, with each pixel independently outputting a ‘spike’ only when it observes a change in illumination at that particular area. Combined, the camera produces a stream of events at its output. Each event is composed of four values: the pixel location, a timestamp, and the polarity for each event {x, y, p, t}.
The event camera possesses two main advantages: high dynamic range and low latency. These advantages make it an attractive sensor for applications requiring high throughput. Commercially available event cameras can comfortably output events at rates of around a billion events per second. A natural connection can be made between a sensor modality so fast and autonomous systems requiring control at fast speeds, as is the case for agile drone navigation.
Spotlight: Academic programs

Working with the academic community
However, a fast and asynchronous modality such as this poses problems to computer vision models mostly geared toward frame-based inputs with no notion of time, such as convolutional neural networks (CNNs). While it is also possible to accumulate event pixels into frames and make them amenable for CNNs, this does not fully exploit the advantages of the event camera. “Spiking neural networks” adapt directly to continuous data representations over time, yet these often require specialized hardware to fully realize their potential. Such hardware may not be available on board platforms like drones.
Combining unsupervised learning and event streams to learn visuomotor policies
In our paper, we introduce the first pipeline that can learn visuomotor policies directly from event streams using conventional (non-spiking) machine learning techniques. Representation learning is currently a focus in machine learning, with research indicating that it is advantageous to decouple the perception and action parts of the autonomous system loop and train them each separately. We apply this same line of thought to event cameras and show that it is possible to learn a model of an environment from fast, asynchronous spatiotemporal data output by an event camera—and then use the data to generate actions.
Our model is built upon the idea of unsupervised learning using a variational autoencoder (VAE), which we call an event-VAE. The core idea is to process a stream of events that contains observations of the environment and compress it into a latent vector, which encodes the full context of what has happened in that window of time. Due to the asynchronous nature of the camera, any given window of time could contain a variable number of events. This lies in stark contrast to the kind of synchronous, frame-based input expected by conventional machine learning models.
We handle this by preprocessing the event data through an initial module called the event context network. The event context network is expected to encode the data being seen into a single vector of fixed size. This enables the VAE to deal with input data of varying lengths, thus addressing the issue with the variable data rate of event cameras.
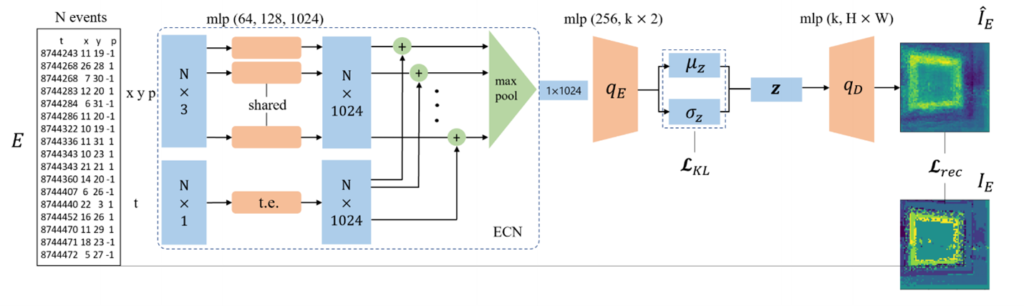
This event context network is divided into a spatial part and a temporal part (see Figure 2). The spatial part extracts the {x, y, p} part of the data and computes a feature for each event by projecting them through a multilayer perceptron. In order to mark the events in time, we encode each timestamp into a rich embedding through a sinusoidal encoding (in other words, we use sine/cosine functions) inspired by the positional encoding used in Transformers. Combining this embedding with the corresponding spatial feature allows us to describe the events completely.
Inspired by the class of methods that were originally proposed for sets like PointNet, we apply a symmetric function at the end of this block to reduce this set of features into a singular feature, which is expected to effectively encode what the sensor has seen within this window of time. Considering that event cameras are even faster than speeds most robots can be controlled at, we might benefit from computing representations at a higher rate than the control frequency of the robot. Our algorithm allows computing representations as fast or as slow as possible: for instance, all the events in a batch can be processed together or can be processed recursively, with the event-VAE outputting data on demand.
Testing navigation policy learning through event representations in Microsoft AirSim
We make use of our high-fidelity robotics simulator, Microsoft AirSim, to implement and test this technique for obstacle avoidance using drones. We recently released a new feature that allows “simulating” the output of an event camera inside AirSim, which we use to generate event data from a drone flying around in an obstacle field, and we first train the event-VAE on this data composed of event observations of obstacles.
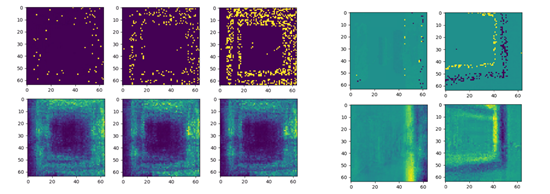
We notice several advantages that stem from this combination of event data and representation learning. First, as discussed before, event data can be streamed with variable lengths, but a trained model is able to infer context equally well from both sparse and dense streams of data. By sufficiently encoding the relative recency of the data (through the timestamps) and the direction of motion (through the encoding of polarities), the latent representation informs the robot of the location and dynamics of the objects being seen (see Figure 3). The inherent advantages of variational autoencoders can still be leveraged, such as the construction of a smooth and disentangled latent space (see Figure 4).

Finally, we apply these representations in a reinforcement learning setting and show how event camera data can be used for learning visuomotor policies. Reinforcement learning is often a complex task, requiring many samples and interactions with the environment to learn policies, particularly from high dimensional inputs such as images. By learning a representation that is both compact and is accessible at a high rate, we show that policies coupled with such representations train faster than those using RGB images—or even event frames—and can be used to control vehicles faster.
We train four types of policies using the Proximal Policy Optimization (PPO) algorithm in AirSim environments:
- BRP_full: Policy trained on event-VAE representation from full event data {x, y, p, t}
- BRP_xy: Policy trained on event-VAE representation from spatial-only event data {x, y}
- EIP: Policy trained using a CNN on accumulated event frames
- RGB: Policy trained using a CNN on RGB frames
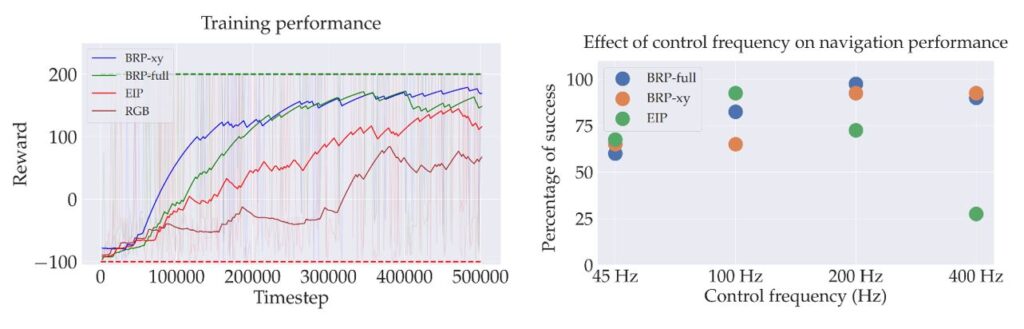

When these policies are deployed in a test setting, we notice several advantages of the BRP over the EIP:
- The fact that the BRPs are operating on a compressed representation allows them to be trained faster than the EIP/RGB policies.
- The invariance of the event-VAE to sparsity in input data benefits the BRP, and it allows for faster control of the drone. With higher control frequencies, the amount of data observed between control steps becomes smaller, which adversely affects the CNN-based EIP, whereas the BRPs still gather enough context.
- The BRPs are also more robust to differences in the appearance of the obstacles. We observe the behavior learned with a BRP generalizes to obstacles of different textures and shapes, whereas the EIP does not. This is because the event-VAE encodes the abstract notions of obstacle location and direction of motion in a way that’s agnostic to the actual appearance.
- The BRPs also exhibit a higher degree of robustness to camera noise (spurious events) compared to the EIP.
More details about our experiments and further findings can be explored in our paper.
Training autonomous systems to think both fast and slow
In his 2011 book Thinking Fast and Slow, renowned psychologist Daniel Kahneman posits that the human brain operates within two modes of thought: one reactive and fast, and another deliberative and slow. When an object is thrown at a person, the person instinctively ducks, sometimes even without full realization of things like the type or the exact geometry of the object. Thus, the brain is able to react effectively by processing only the minimum amount of information required.
In this way, we believe low-level sensors like event cameras hold great promise in building for a reactive system for robots—an instinctive perception-action loop that can reason about the world several thousand times a second and help generate safe actions. This system can potentially be coupled with another that focuses on more complex modalities and higher-level reasoning, thus paving the way toward agents with robust cognitive and motor abilities that may someday mimic our own.
The post Learning visuomotor policies for autonomous systems from event-based cameras appeared first on Microsoft Research.