
This post has been republished via RSS; it originally appeared at: Microsoft Research.
One key aspiration of AI is to develop natural and effective task-oriented conversational systems. Task-oriented conversational systems use a natural language interface to collaborate with and support people in accomplishing specific goals and activities. They go beyond chitchat conversation. For example, as personal digital assistants, they ease the stress of trip planning or reduce the expertise required to generate a sales report from a database. While natural language understanding (NLU) technology and research have achieved remarkable recent progress, task-oriented assistance requires tackling additional challenges in practical NLU.
Consider a prime application of task-oriented conversations: language-driven data exploration. Data scientists, analysts, and information workers routinely spend more than half of their time exploring, visualizing, and reformatting datasets, according to Anaconda’s “The State of Data Science 2020.” Not only time-consuming, this process is also error prone and typically requires data science programming skills, such as knowledge in Python, R, or SQL. Augmenting interactive data science environments like Microsoft Excel or Jupyter with language-driven assistance would not only save time but also democratize data exploration. For instance, an analyst could ask a system in natural language to plot last month’s sales metrics from her database rather than program a filtered visualization in SQL+R. Importantly, such a system should still allow analysts to inspect and edit program snippets after assisting with the most laborious parts of exploratory data science. This transparency and ability to edit will empower analysts and allow them to have confidence in the outcome of the work.
Data exploration highlights a core NLU challenge that plagues all task-oriented conversational systems. Understanding people’s language—and thus, their task intent—must be grounded. That is, what has been said must be interpreted relative to its context. Task-oriented systems deal with two kinds of relevant context. First, every task acts upon a structured ontology such as a database, a spreadsheet, or an API. The ontology provides data context, which influences language understanding. For example, the analyst question “Which departments have unfinished projects?” refers to “departments” and “projects” in her database and “unfinished” likely refers to a project’s status column in that database, all of which the system must emit as column references in the desired SQL program. Second, conversational systems must consider multi-turn dynamics of an interaction, which create conversation context. For example, the analyst might follow up her exploration with “What is their total budget,” implicitly referring to “unfinished projects” from the previous turn.
Recently, we’ve made several fundamental contributions to these challenges. In the 2021 International Conference on Learning Representations (ICLR) publication “SCoRe: Pre-Training for Context Representation in Conversational Semantic Parsing,” we introduce SCoRe, a task-oriented conversational system with multiple applications. SCoRe achieves new state-of-the-art performance in interactive data exploration (on SParC and CoSQL benchmarks) and task-oriented dialogue (MultiWOZ), improving upon previous best techniques by up to 12 percent. SCoRe addresses the conversation context challenge through its task-oriented pretraining methodology, which learns language representations that link multiple conversation turns. To address the data context challenge, SCoRe builds upon our previous work in RAT-SQL and StruG. These two publications introduce a unified framework for language understanding in the context of a structured database. It has since been leveraged in numerous applications in addition to SCoRe. We’re presenting SCoRe at ICLR on Monday, May 3, from 5 PM to 7 PM Pacific Time and 7 PM to 9 PM Pacific Time. The SCoRe code will be published on GitHub; please follow the repository for updates.
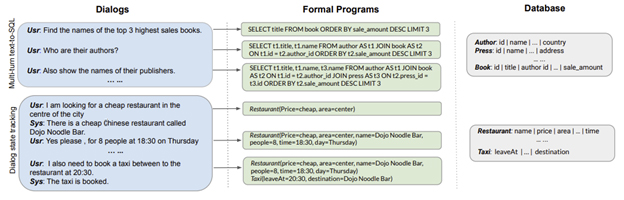
Data context representation
The grounding challenges associated with data context and conversation context are distinct yet interconnected, and progress on both is critical to build effective task-oriented conversational systems. Here, we first address data context grounding by focusing on a single-turn version of the data exploration problem known as database question answering (DBQA). As you’ll see, techniques developed for DBQA facilitate data context grounding in broader applications of task-oriented conversational systems.
RAT-SQL: Joint representation of question and data context
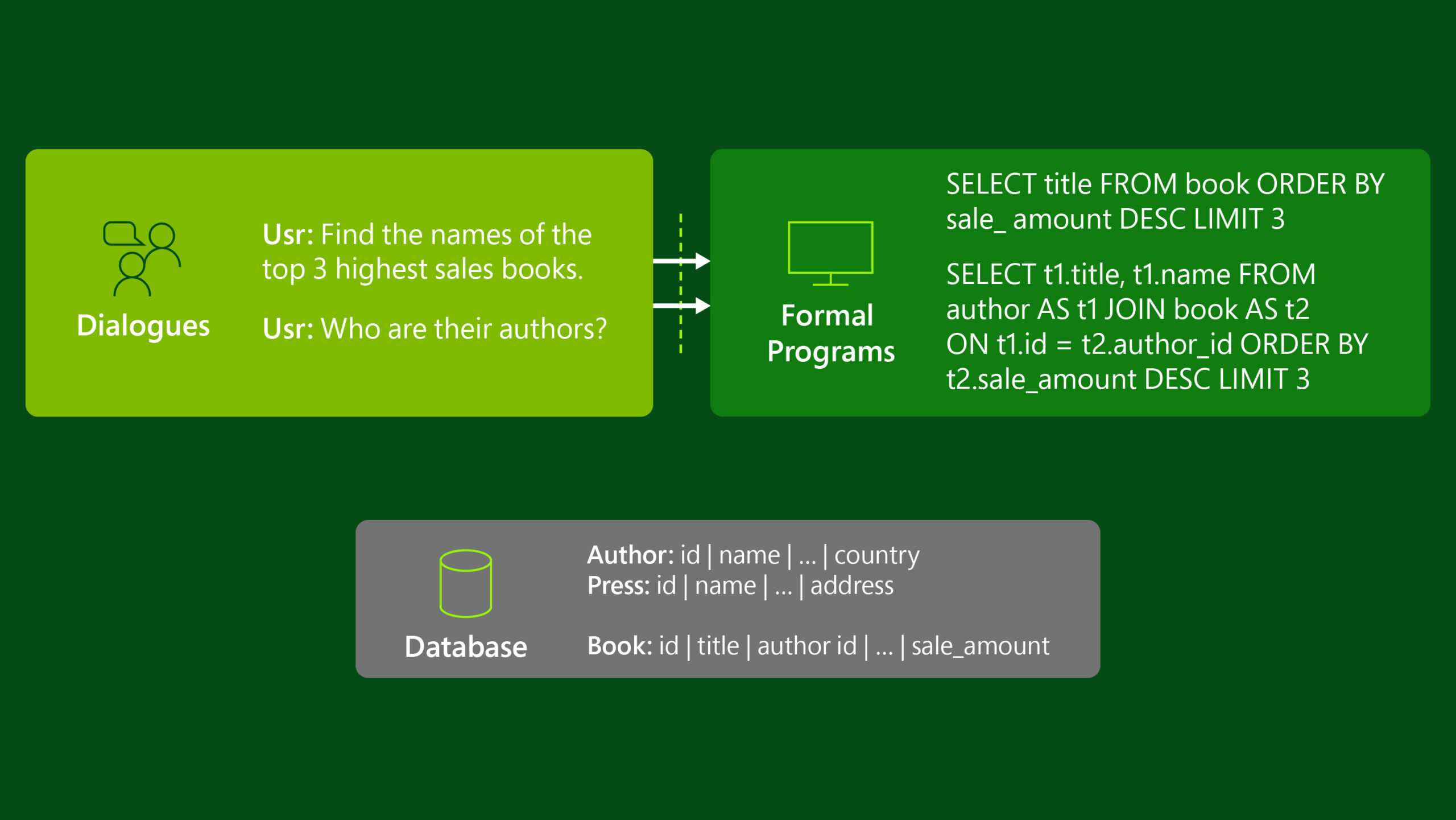
When an analyst asks a question over her database, that question and its associated data context—the database schema—are both embedded into distributed intent representations by a neural encoder network. The key to addressing the data context challenge is jointly contextualizing intent representations—the question and the schema provide important context to each other. For example, in Figure 1, “Find the names of the top 3 highest sales books” refers to the title column even though the question doesn’t mention “titles.” From question language alone, author.name could superficially seem a better match.
Transformers are the most effective approach for contextualized representation learning in modern NLU. They’re based on self-attention, which, in one interpretation, learns latent relations between the inputs—in this case, question words and column/table names in the schema. While effective in multiple fields, self-attention requires large training corpora, and human-authored DBQA datasets reach only up to 10,000 training instances. With limited data, even simple natural language relations, easily discovered in machine translation and other NLU systems, can be challenging. For instance, in our DBQA experiments, standard Transformers struggled to reliably link “sales” to the column sale_amount. In the 2020 Meeting of the Association for Computational Linguistics (ACL) publication “RAT-SQL: Relation-Aware Schema Encoding and Linking for Text-to-SQL Parsers,” we introduced relation-aware Transformers (RAT), which reduce training data requirements by incorporating known relational information about the database into self-attention. They allow the encoder to consider, for instance, database foreign keys without either rediscovering them (as in standard Transformers) or hard-coding the network’s relational structure to follow them (as in graph neural networks). As such, RAT augments the learning efficacy of Transformers with rich background knowledge about relational structure.
We combine a RAT encoder with a grammar-driven program decoder into an end-to-end DBQA model called RAT-SQL. On Spider, currently the most challenging text-to-SQL dataset, RAT-SQL achieved a new state of the art of 65.6 percent exact-match accuracy at the time of its publication. Relation-aware data contextualization added a more than 5 percent margin over previous best techniques. Since then, numerous researchers from other institutions have built upon RAT-SQL in their DBQA models, achieving even more impressive performance.
StruG: Structure-grounded pretraining for robust language understanding
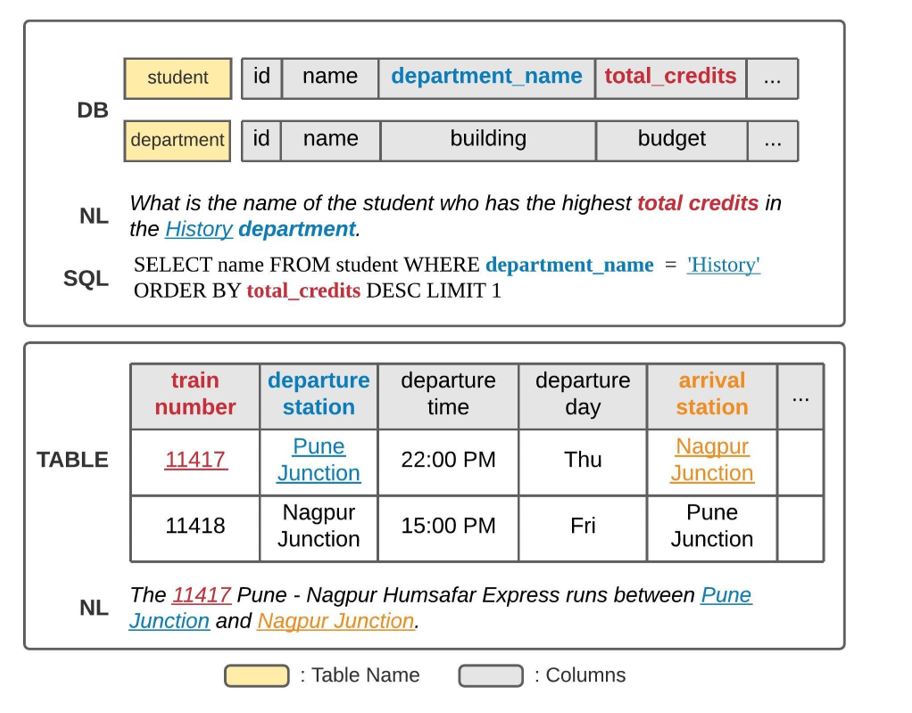
Joint representation of the question and its data context fundamentally requires solving an alignment problem—that is, linking words in the question to the data columns they reference. Relation-aware Transformers effectively incorporate known relations between the question and the data, but alignment often requires additional background knowledge either from the database content or from NLU at large. For example, in Figure 2, linking “History” to department_name is challenging without looking at the database content even though people’s real-world experience intuitively aligns these two phrases.
Background knowledge on question-table alignment naturally occurs in parallel text-table corpora such as ToTTo. They pair data tables with relevant utterances about them, such as table summaries and data references. While such utterances are not typically in question form, they exhibit the same alignment patterns as questions in DBQA. In an upcoming 2021 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL) publication “Structure-Grounded Pretraining for Text-to-SQL,” we propose a method to leverage this data for pretraining contextual representation models. StruG, short for “Structure-Grounded pretraining,” introduces three critical pretraining tasks that use text-table alignment annotations as weak supervision:
- Column grounding: given a column—for example,
train numberin Figure 2—predict whether it’s relevant to the utterance - Value grounding: given a word in the utterance—for example, “11417”—predict whether it refers to a cell in some column
- Column-value mapping: given a word—such as “11417”—and a column name—
train number—predict whether they align
Importantly, the StruG model can’t observe database content when predicting these tasks. It learns contextualized alignment solely from the utterance and the data schema. After pretraining, we apply StruG in DBQA to emit initial question/table representations that communicate information about the context structure to the downstream RAT-SQL model.
On the Spider dataset, StruG-augmented RAT-SQL performs competitively with all state-of-the-art models even without using database content. More importantly, its learned text-table alignment makes database question answering more robust. When development-set questions in Spider are rephrased in a more realistic, fluid natural language, execution accuracy of state-of-the-art models drops by 11 to 20 percent, but StruG-augmented RAT-SQL never suffers more than a 10 percent loss.
SCoRe: Pretraining for conversation context representation
The solutions to the data contextualization challenge are also relevant for the conversation contextualization challenge. To account for multi-turn dynamics of dialogue, a conversational system must ground an individual’s question in both its data context—that is, its ontology—and in the questions from previous turns. SCoRe introduces a task-oriented pretraining methodology to encode both.
SCoRe pretrains a task-oriented language model contextualized by the conversational flow and the underlying ontology. In pretraining, the SCoRe model is self-supervised by two novel task-oriented objectives in addition to the established masked language model (MLM) objective. These objectives facilitate the accurate representation of the conversational flow between dialogue turns and how this flow maps to the desired columns in the ontology. For example, in the first question of Figure 1, “Find the names of the top 3 highest sales books,” the model needs to apply the order by operation to the column sale_amount to find the books with the highest sales. In the follow-up question “Who are their authors,” the model needs to understand that it should maintain the context of the previous question while also selecting a new column, name, from the author table.
The first pretraining objective of SCoRe, Column Contextual Semantics (CCS), aligns the question with the ontology. For each column in the ontology, CCS trains the model to predict the operations that should be performed on this column in each conversational turn. Specifically, SCoRe uses the encoding of each column or table name to predict its corresponding operation. The second pretraining objective, Turn Contextual Switch (TCS), captures the conversational flow and how it’s grounded in the model’s expected output programs. It aims to predict the difference in programs from different dialogue turns based on the corresponding user questions. For example, the current turn may differ from the previous one by adding an additional filtering condition or changing the order of the results.

State-of-the-art results
Our empirical results show that SCoRe can be effectively used as a feature representation encoder with strong baseline models for a wide range of tasks and can significantly improve the performance of existing strong baseline models by simply replacing an existing pretrained language model with our SCoRe pretrained model.
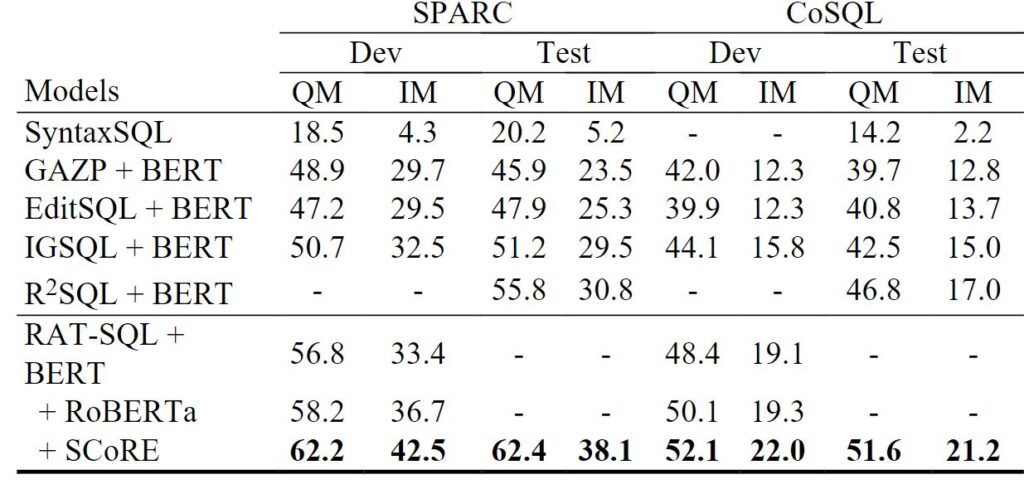
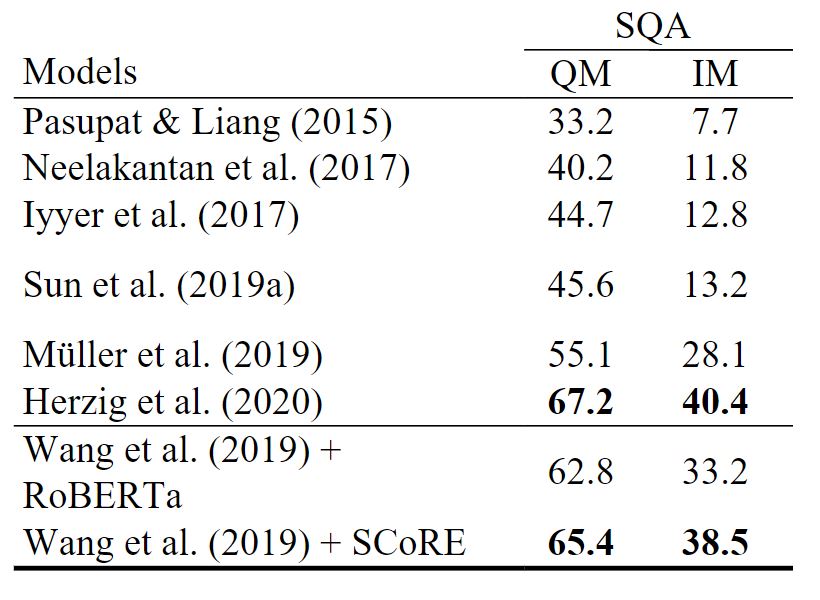
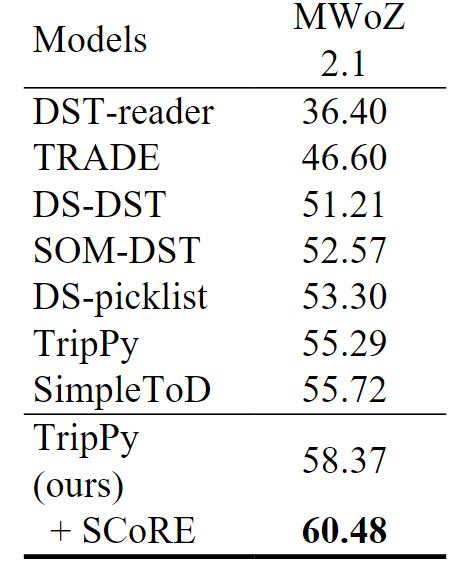
SCoRe achieves state-of-the-art results when evaluated on three popular benchmarks for task-oriented conversational systems: SParC (sequential text-to-SQL), CoSQL (conversational text-to-SQL), and MultiWOZ (dialogue state tracking). It also performs competitively with state-of-the-art techniques on SQA (sequential question answering). Moreover, SCoRe delivers even larger improvements when in-domain data is limited—for example, in a low-resource setting where only 10 percent of the training data is available. This wide range of applications demonstrates the effectiveness of addressing both context grounding challenges jointly.
Revolutionizing interaction with data
Task-oriented conversational systems can revolutionize people’s natural interaction with structured data and APIs. Using natural language as a universal interface has been a major goal of human-computer interaction and knowledge management fields for decades. Early attempts have faced challenges because of limitations in language understanding capability, extensibility, and transparency, among other areas. However, recent years have seen a major resurgence powered by interest in impactful applications such as personal digital assistants, question answering systems, automatic reporting, and AI-assisted data science.
Many challenges remain. Conversational interfaces also require us to make systems reasoning and results explainable and trustworthy to those using them. Language-driven exploration must be supported by interactive interfaces for debugging and correcting generated programs or the underlying dataset. Creating systems that interact with those using them to resolve knowledge gaps and continue to learn to reduce human intervention over time remains an open research challenge. We’ve studied additional forms of interaction to address these challenges in language-driven data exploration, including natural language feedback for correcting misinterpretations and Debug-It-Yourself (DIY) multimodal feedback for assessing a system’s responses and fixing errors in an interactive user interface. Both improve systems’ accuracy and transparency, yet more research is needed to integrate them into task-oriented conversational systems more broadly. We hope that SPLASH, a dataset of utterances, misinterpretations, and corrections we created from our feedback studies, will prove useful to facilitate that research.
Finally, many NLU challenges stem from the limitations of current benchmarks and datasets of task-oriented conversational systems. As we scale our techniques and integrate them into real-world applications, we’ll encounter more realistic scenarios and workflows, which will undoubtedly expose new research challenges. As such, language-driven data exploration will not only be one of the most impactful applications for the field, but also the catalyst to its further progress.
Acknowledgment
The development of SCoRe is a result of the collaborative efforts of Tao Yu of Yale University, Rui Zhang of The Pennsylvania State University, Microsoft researchers Alex Polozov and Chris Meek, and Microsoft Senior Principal Research Manager Ahmed H. Awadallah. RAT-SQL was led by Bailin Wang of The University of Edinburgh in collaboration with Microsoft researchers Richard Shin, Xiaodong Liu, and Polozov and former Microsoft researcher Matthew Richardson. StruG was led by Xiang Deng of The Ohio State University in collaboration with Awadallah, Meek, Polozov, Richardson, and assistant professor Huan Sun. Yu, Wang, and Deng conducted the work during their Microsoft Research internships.
The post Conversations with data: Advancing the state of the art in language-driven data exploration appeared first on Microsoft Research.