
This post has been republished via RSS; it originally appeared at: Microsoft Research.
Understanding video is one of the most challenging problems in AI, and an important underlying requirement is learning multimodal representations that capture information about objects, actions, sounds, and their long-range statistical dependencies from audio-visual signals. Recently, transformers have been successful in vision-and-language tasks such as image captioning and visual question answering due to their ability to learn multimodal contextual representations. However, training multimodal transformers end-to-end is difficult because of the excessive memory requirement. In fact, most existing vision and language transformers rely on pretrained language transformers to train them successfully.
Today, in collaboration with NVIDIA Research, we are excited to announce our work: “Parameter Efficient Multimodal Transformers for Video Representation Learning.” In this paper, which was accepted at the International Conference on Learning Representations (ICLR 2021), we propose an approach to reduce the size of multimodal transformers up to 97 percent by weight sharing mechanisms. This allows us to train our model end-to-end on video sequences of 30 seconds (480 frames sampled at 16 frames per second), which is a significant departure from most existing video inference models that process clips shorter than 10 seconds, and achieve competitive performance on a variety of video understanding tasks.
Aggressive parameter sharing within transformers
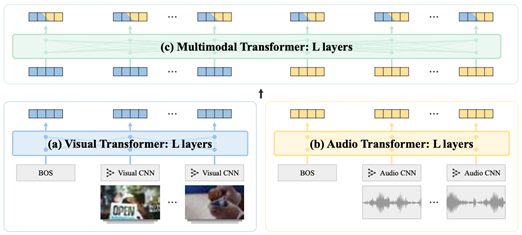
Our model consists of five components: audio and visual convolutional neural networks (CNNs), audio and visual transformers, and a multimodal transformer. The two CNNs encode audio and visual signals from one-second clips, respectively, while the three transformers encode audio, visual, and audio-visual signals from the entire input sequence (30 seconds). The whole model contains 155 million weight parameters and the three transformers consume 128 million parameters, or 82.6 percent of the total. Training on 30 seconds of video is GPU memory intensive, requiring small batch sizes and long training time.
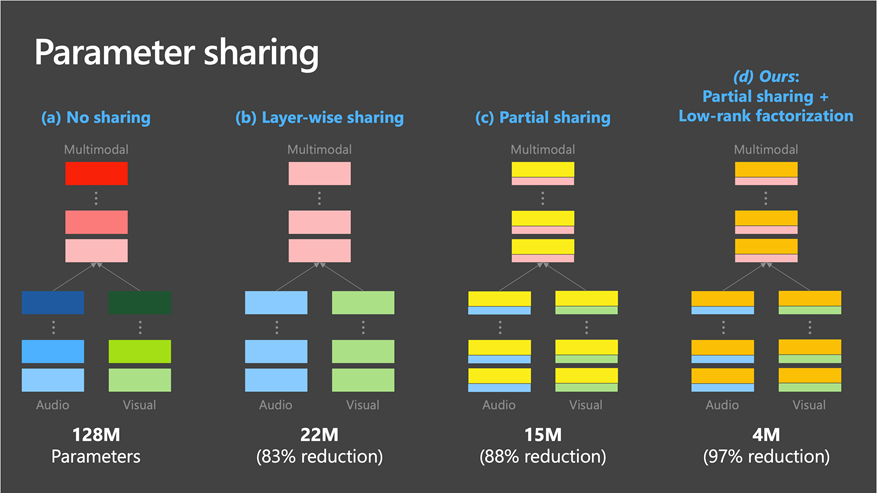
To address this, we reduce the model size by sharing the weight parameters using two strategies. The first strategy shares weights across layers within each transformer, treating a transformer as an unrolled recurrent network. As shown in Figure 2(b), this reduces the parameters by 83 percent (from 128 million to 22 million). The second strategy involves partial weight sharing with low-rank factorization, where we factorize each weight matrix of the transformer into a form \(W\)=\(U\)\(Σ\)\(V\) and shared \(U\) across transformers while keeping \(Σ\)\(V\) private to each transformer. This strategy, depicted in Figure 2(c), helps our model capture the underlying dynamics between modalities efficiently: \(U\) models modality-shared dynamics, while \(Σ\) and \(V\) model modality-specific dynamics. The factorization and partial sharing achieve 88 percent parameter reduction. We further reduce the parameters by imposing a low-rank constraint on parameter \(Σ\), achieving a 97 percent reduction rate, from 128 million parameters to just 4 million parameters.
Spotlight: Academic programs

Working with the academic community
WebDataset: An efficient PyTorch I/O library for large-scale datasets
With this optimized training procedure, we can now train on peta-byte scale datasets at high speed. To meet the high I/O rates required by the algorithm, we have developed in parallel WebDataset, a new high performance I/O framework for PyTorch. It provides efficient access to datasets stored in POSIX tar archives and uses only sequential/streaming data access. This brings substantial performance advantages in many compute environments, and it is essential for large-scale training such as video datasets.
Content-aware negative sampling
We train our model using contrastive learning objectives. In contrastive learning, finding informative negative samples is essential for the model’s convergence. We develop a novel content-aware negative sampling strategy that favors negatives sufficiently, similar to the positive instance. Specifically, we calculate the normalized pairwise similarity in the CNN embedding space and treat them as sampling probabilities, so that the more similar a sample is to the positive, the higher the chance there is to be selected as negative.
Downstream performance
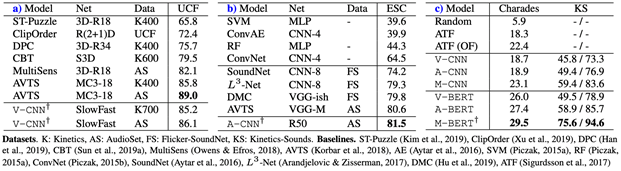
Our model achieves competitive performance across several benchmarks that involve audio and/or visual modalities from short or long clips. Table 1 shows different components of our model generalizing well across tasks, for instance visual CNN for short action recognition (UCF-101), audio-CNN for short environmental sound classification (ESC-50), and the transformers for long audio-visual video classification (charades and kinetics-sounds). Our results demonstrate the versatility of this model—once pretrained, we can take different components appropriate for downstream scenarios.
Looking forward
Large-parameter transformer models are producing impressive results on numerous challenging tasks, but there is a growing concern that conducting research in this direction is limited to institutions with large compute resources. In this work, we presented an approach to reduce the size of multimodal transformers by up to 97 percent and still achieve competitive results on standard video benchmarks, making them more accessible to institutions with limited compute resources. To accelerate research in this direction, we have open sourced the code and will be releasing the pretrained model checkpoints on GitHub in the coming weeks. We hope that our research will open up research opportunities in large-scale pretraining to institutions with limited compute resources
Acknowledgement
This research was conducted by an amazing team of researchers from Seoul National University (Sangho Lee, Youngjae Yu, and Gunhee Kim), NVIDIA Research (Thomas Breuel and Jan Kautz) and Microsoft Research (Yale Song).
The post Microsoft and NVIDIA introduce parameter-efficient multimodal transformers for video representation learning appeared first on Microsoft Research.