
This post has been republished via RSS; it originally appeared at: Microsoft Mobile Engineering - Medium.
This is the third part of our multi-part series. You can find the previous part below. In this article, we will cover how we leverage various Azure Pipeline features to enforce our release processes.
We use several Azure DevOps features across all our pipelines. In this article, we will discuss how we leverage some of these features to reliably enforce our release processes. But first, let us start with a quick overview of SwiftKey’s release process.
SwiftKey’s release process
There are 3 variants of our SwiftKey Android app that go through our release process at a 2-week cadence. The variants are:
- Cesar: Our dogfood variant for Microsoft employees only
- Beta: Public beta which has its own Google Play Store listing
- Market: The main variant of the app with over 500 million downloads
Every two weeks, we release a sprint’s worth of work to Cesar* and this rolls out the app to all Microsoft employees who have opted-in. Once we are confident that everything is functioning as expected, we update our Beta variant on the Play Store. After monitoring the stability of Beta, we roll out to 1% of our Market users — incremental rollouts are important for Market variant because we noticed that users who opted to install the Beta variant tend be on the latest hardware so they are not very representative of the Market user base. If we are happy with the state of the release from the 1% rollout, we increase the rollout to 99% and eventually 100% of our user base. Rolling out to 99% first gives us the opportunity to abort the release before going to most of our users should we detect any anomalies that did not show up in earlier stages.
*We also do mid-sprint releases for Cesar. However mid-sprint releases do not go through the full release cycle to public users.
Release process in code — Multi-stage pipeline
The whole release process we described in the previous section is coded into a single multi-stage pipeline. Within each stage we have one or more jobs with their own dependency graph. This pipeline gives us a clear overview of the state of release for any given version of our app. Having an overview across multiple app versions is important to us because at any given time we have between 2 to 3 versions of the app in different stages of our release pipeline.
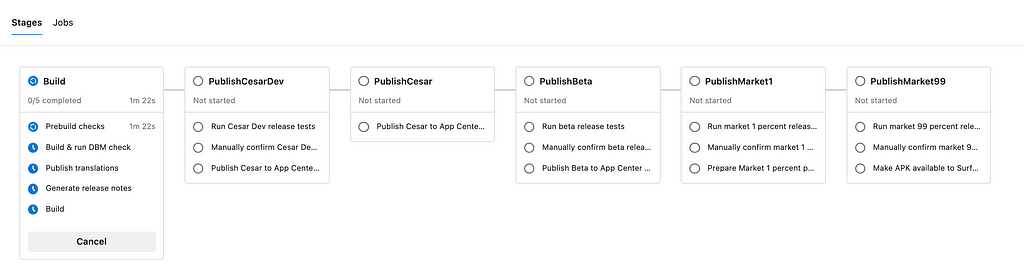
Parallel vs Sequential jobs
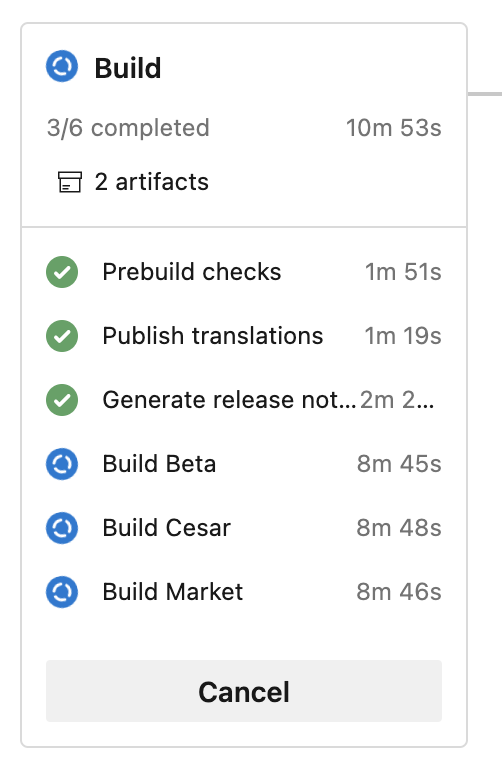
Our release pipeline starts with the build stage. First, we perform some prebuild checks that make sure we are building the correct branch and version number etc. We setup our job dependencies so that Build jobs run after Prebuild checks and only if it passes. Once that has passed, all variants are built in parallel.
ADO’s built-in checkout task makes sure that each job in a pipeline checks out the same commit. This eliminates the risk of working on different commits in each job.
Manual Approvals
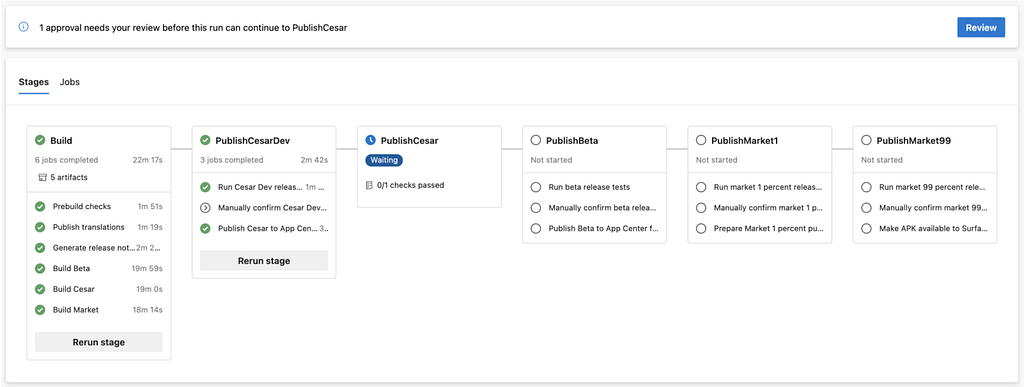
After executing a stage, the release pipeline will pause and wait for manual approval before proceeding with the next stage. This is important because we always wait multiple days for users to update the app and receive the latest data to decide if it is safe to proceed to the next stage. If we notice any issues with the latest roll-out, we can reject it at the manual gating and the pipeline would halt the release from proceeding to any of the next stages.
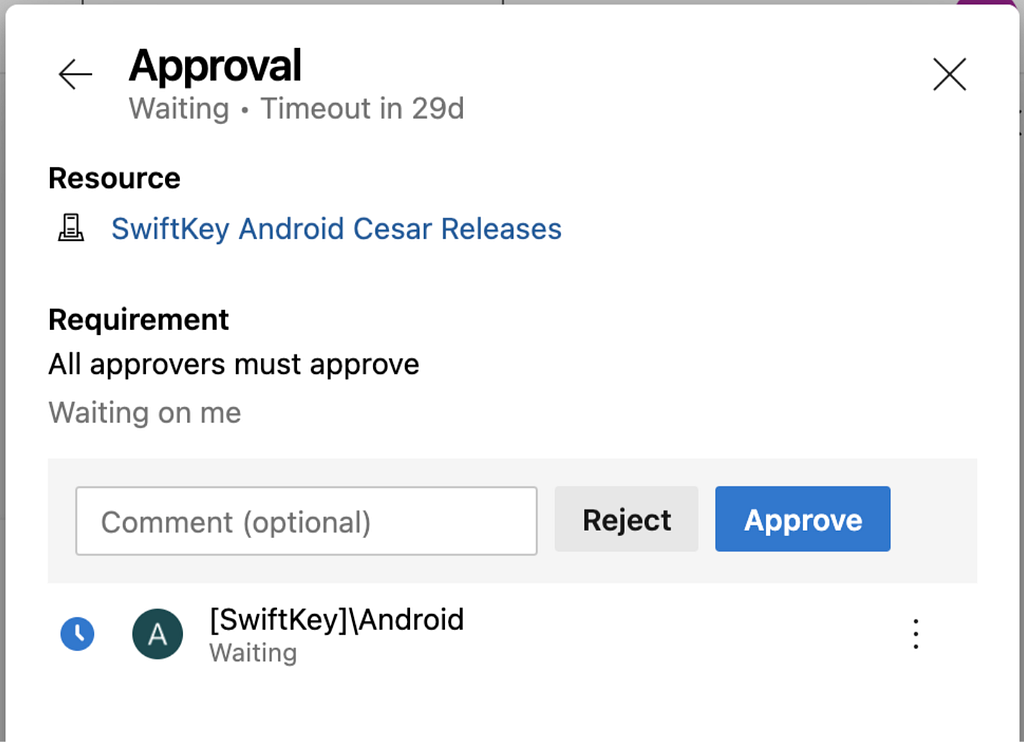
Manual Validations
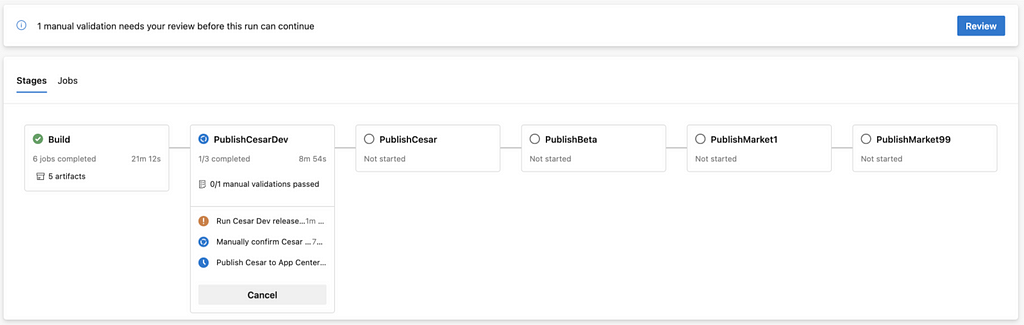
Within each rollout stage, we have 3 jobs. The first of which, named Run release tests, runs tests that verify critical metrics such as crash rates, telemetry events health, number of users, etc. for the rollout from the previous stage. If any of the health metrics deviate from the expected range, the second job, titled Manually confirm release, in the stage pauses the current stage for a manual review. At this point, we can either approve to proceed with the release or abort the whole release. If all metrics are healthy, the pipeline automatically proceeds to the publish job in that stage.
YAML based config
On Azure Pipelines we can configure a pipeline entirely using Classic UI (GUI editor view) or define a pipeline config using YAML files. We use YAML based config for almost all our pipelines. This has several advantages:
- Version control: Each commit has its own version of config so we don’t have to keep a single config that works for all versions of the app (as we may have to when using UI based configuration).
- Code reviews: The pipeline config lives in the repository alongside the rest of the code so all changes go through the same review process as the rest of the codebase.
- Reusable: We can define the pieces of config once and reuse it multiple times.
Templates for config re-use
We use the templates feature on ADO extensively and maintain templates for commonly performed tasks, jobs or stages. Templates also support parameters. One commonly reused logic for Android teams can be spinning an emulator.
Dashboards
We use dashboard to monitor the state of different pipelines at a glance. Azure dashboard comes with support for a plethora of widgets. The widgets are highly configurable and we use them to monitor the state of pipelines on specific branches. There are many other scenarios that can be tracked using dashboards. Checkout the dashboards documentation for a more comprehensive overview.
In the next article in this series, we will discuss about our infrastructure improvements using self-hosted agents to address stability and scalability of agents and emulators, our learnings and future plans.
CI / CD at SwiftKey (Part 3) was originally published in Microsoft Mobile Engineering on Medium, where people are continuing the conversation by highlighting and responding to this story.