
This post has been republished via RSS; it originally appeared at: Microsoft Research.

The ability to perceive communication signals and make sense of them played an essential role in the evolution of human intelligence. Computing technology is following the same trajectory. Now, computer vision and automatic speech recognition (ASR) technologies have enabled the advent of many artificial intelligence (AI) applications and virtual assistants by allowing machines to see and hear in the physical world. However, we have a long path ahead of us before machines are able to comprehend complex human interactions like the intricacies of interpersonal communication.
Most voice assistants only accept a command spoken by a single speaker at a time. They cannot distinguish “who is saying what” from recordings of human-to-human conversations, which many people can do with little difficulty, and so we sometimes take this ability for granted. This task is particularly simple when we are participating in conversations—we can use multiple senses to gain understanding.
While there are many seemingly related technologies, ranging from ASR and speaker diarization to face detection, tracking, and recognition, the best way to orchestrate such a diverse set of technologies and modalities remains to be seen. The fundamental challenges that cannot be solved by simply extending existing research directions also need to be identified and explored further, as well as whether one can build an accurate “rich transcription” system that allows for high-level AI capabilities to be built on top of it (capabilities such as text summarization and action item extraction).
In “Advances in Online Audio-Visual Meeting Transcription,” researchers and engineers at Microsoft joined forces to find answers to these questions by building a real-time audio-visual meeting transcription system while tackling some fundamental research challenges. We built a prototype audio-visual recording device and collected real meeting recordings in the Microsoft Speech and Language Group (multiple internal Microsoft teams) with the consent of all of the meeting attendees. In addition to getting consent, we also built the system with Microsoft’s AI principles at the center of our development efforts. Our device combines both audio and video signals to more accurately detect who is speaking (and when) in a meeting to improve transcription. The paper will be presented at the IEEE Automatic Speech Recognition and Understanding Workshop (ASRU 2019) in Singapore.
Continuous Speech Separation distills audio into non-overlapping channels
The hallmark of our transcription system is its ability to handle overlapped speech. If someone has previously seen public demos that separate two or three voices overlapping each other, they may think this is an easy undertaking. In fact, numerous speech separation methods were proposed in the past. However, most methods were tested only in laboratory settings where there was little reverberation and noise or where overlapped speech was artificially created by mixing voices on computers. In audio-visual speech separation, it was often assumed that frontal views of speakers’ faces were clearly captured. In practical meeting transcription setups, these ideal conditions are never met, making the existing speech separation technology of little use.
We address this long-standing problem with a continuous speech separation (CSS) approach, which we recently developed. CSS takes advantage of the fact that the maximum number of simultaneously talking speakers is usually limited, even in large meetings. According to prior reports, more than 98% of the speech frames in meetings consist of voices of two or fewer speakers. Therefore, given a stream of microphone signals, the CSS module generates two audio signals. Each utterance is separated from the overlapping voices and background noise. Then, the separated utterance is spawned from one of the two output channels. When only one person is speaking, the extra channel generates zeros. The CSS module is built based on a speech separation neural network. The neural network is enhanced with multi-channel acoustic signal processing. The CSS approach is shown to improve the word error rate (WER) by 16.1% compared with a highly optimized acoustic beamformer.

Figure 1: Continuous speech separation. CSS generates two audio signals from a stream of microphone signals. Although there can be many more than two microphones collecting audio, CSS works based on the fact that, for the vast majority of the duration of a meeting, only two people are talking at the same time.
Putting audio and video together to identify who is speaking
Speaker diarization is another area where we made substantial progress. A word transcription of a conversation generated by ASR is not enough for humans and machines to fully comprehend the conversational content. In human-to-human communication, the speaker identity of each utterance can play a critical role in determining how the utterances should be interpreted. This is where speaker diarization comes in. It partitions the recording into speaker-homogeneous regions and assigns a speaker label to each of them.
Much of the prior work was devoted to audio-based speaker diarization although several notable papers exist proposing audio-visual approaches. Despite the progress that has been made for decades, the state-of-the-art audio-based speaker diarization methods still suffer from poor performance when the conversation to be processed involves many attendees. While this task can be challenging even for humans (imagine that you are conversing with ten strangers with your eyes closed), we humans can usually sidestep this difficulty thanks to our excellent ability of distinguishing different people by sight.
In our work, we propose an audio-visual speaker diarization model that combines face tracking, face recognition, speaker recognition, and sound source localization. Our holistic approach addresses several problems that were left unsolved by previous audio-visual diarization research, including overlapping utterances and the presence of multiple co-located speakers. (Note that in our experiment, all participants in a meeting had provided their consent to use the system and the transcription features.)
The following diagram shows the vision processing flow. Our vision processing uses Face API, an Azure Cognitive Service, along with several custom enhancements made for improving face recognition robustness to image variations caused by face occlusions, extreme head pose, lighting conditions, and so on, which need to be handled in real-world settings. Face tracking also plays an important role, allowing the system to maintain the identity of a person, even when he or she is partially occluded or looks away from the camera. Experimental results show that, with the proposed approach, the gap between speaker-agnostic and speaker-attributed WERs is within the range of two percentage points, indicating very accurate word-level diarization. The benefit of utilizing the speaker recognition model, in addition to the vision-based speaker diarization, is also shown in the results.

Figure 2: Vision processing flow diagram. Azure Cognitive Services Face API is combined with additional algorithms to visually identify faces in video under highly variable conditions.
Orchestrating every system component
The diagram shown below depicts the end-to-end processing pipeline of our developed meeting transcription system, which integrates CSS and audio-visual speaker diarization along with other processing modules. Based on microphone and camera signals, the system continuously generates speaker-annotated transcripts of a meeting conversation in real time. After the meeting, the attendees are provided with an access-controlled transcript available only to them. Attendees can also choose to not be attributed by name in the transcripts even where they attend meetings that use the system. The experiments reported in the paper were conducted with the consent of all participants.
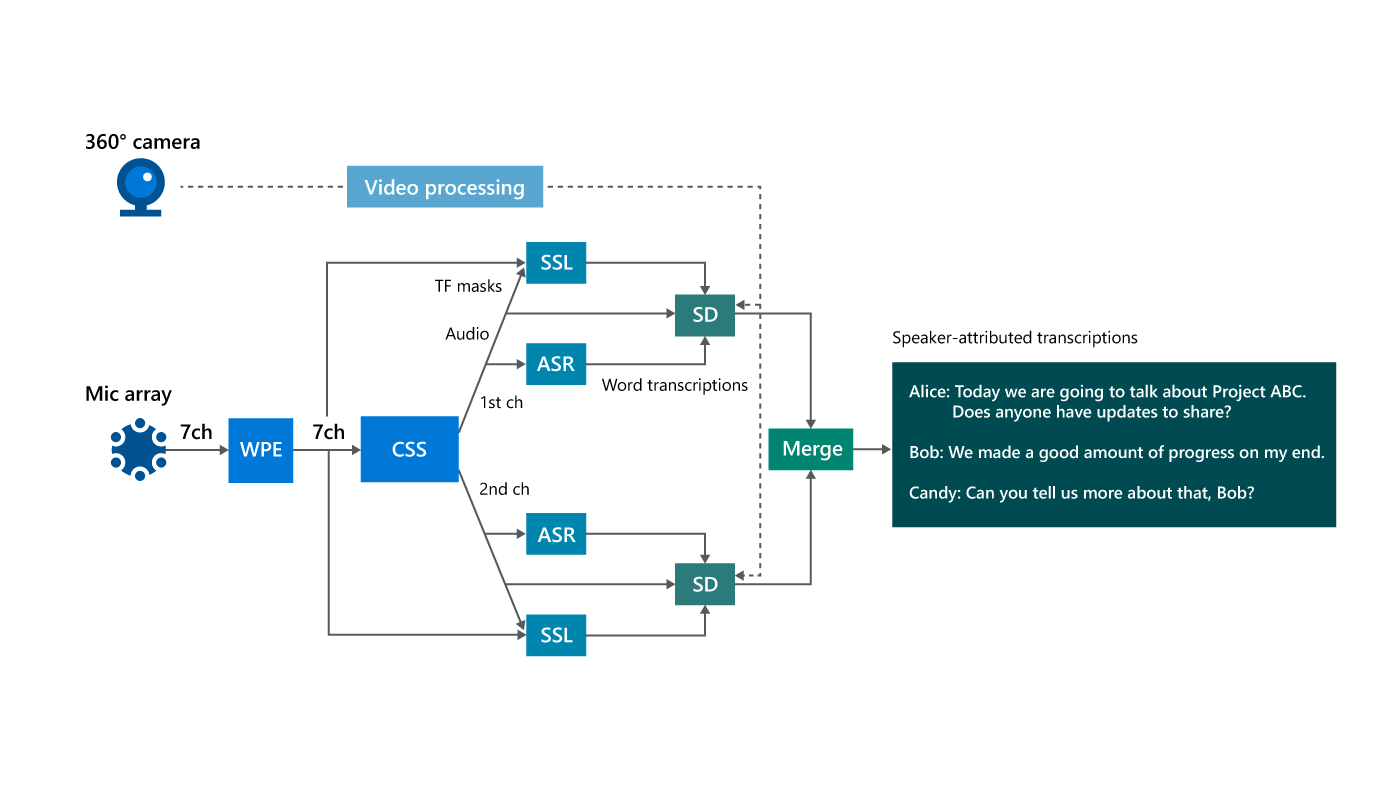
Figure 3: Processing flow diagram of our proposed system. To run the whole system in real time, the video processing and speech recognition (SR) modules are assigned their own dedicated resources. weighted prediction error minimization (WPE) is used for dereverberation. continuous speech separation (CSS) splits the audio into two channels, which moves through automatic speech recognition (ASR) and sound source localization (SSL) modules. These are output to speaker diarization (SD) and then merged.
To our knowledge, this work is the first of its kind that brings both speech separation and audio-visual technologies into a practical conversation transcription scenario. Many interesting research topics still exist. Humans are gaining more information from sight and hearing than our current system, which helps them not only recognize spoken contents in conversations but also comprehend what is happening around them holistically. We will continue to push the envelope along with the researchers in the community.
We will be presenting this research at 4:00 PM on Sunday, December 15, during the “ASR in Adverse Environments” session. For those attending ASRU 2019, we are looking forward to discussions with our colleagues in the research community and sharing our own research.
A number of our colleagues at Microsoft will also present their research at the conference as follows:
- ASR-1.16: IMPROVING RNN TRANSDUCER MODELING FOR END-TO-END SPEECH RECOGNITION: Jinyu Li, Rui Zhao, Hu Hu, Yifan Gong, Microsoft, United States
- TTS.4: KNOWLEDGE DISTILLATION FROM BERT IN PRE-TRAINING AND FINE-TUNING FOR POLYPHONE DISAMBIGUATION: Hao Sun, Peking University, China; Xu Tan, Microsoft Research, China; Jun-Wei Gan, Sheng Zhao, Dongxu Han, Microsoft STC Asia, China; Hongzhi Liu, Peking University, China; Tao Qin, Tie-Yan Liu, Microsoft Research, China
- ADV.2: SPEECH SEPARATION USING SPEAKER INVENTORY: Peidong Wang, Ohio State University, United States; Zhuo Chen, Xiong Xiao, Zhong Meng, Takuya Yoshioka, Tianyan Zhou, Liang Lu, Jinyu Li, Microsoft, United States
- ADV.7: DOMAIN ADAPTATION VIA TEACHER-STUDENT LEARNING FOR END-TO-END SPEECH RECOGNITION: Zhong Meng, Jinyu Li, Yashesh Gaur, Yifan Gong, Microsoft Corporation, United States
- ADV.8: ADVANCES IN ONLINE AUDIO-VISUAL MEETING TRANSCRIPTION: Takuya Yoshioka, Igor Abramovski, Cem Aksoylar, Zhuo Chen, Moshe David, Dimitrios Dimitriadis, Yifan Gong, Ilya Gurvich, Xuedong Huang, Yan Huang, Aviv Hurvitz, Li Jiang, Sharon Koubi, Eyal Krupka, Ido Leichter, Changliang Liu, Partha Parthasarathy, Alon Vinnikov, Lingfeng Wu, Xiong Xiao, Wayne Xiong, Huaming Wang, Zhenghao Wang, Jun Zhang, Yong Zhao, Tianyan Zhou, Microsoft, United States
- SLR-2.4: CNN WITH PHONETIC ATTENTION FOR TEXT-INDEPENDENT SPEAKER VERIFICATION: Tianyan Zhou, Yong Zhao, Jinyu Li, Yifan Gong, Jian Wu, Microsoft Corporation, United States
- SLR-2.9: DOVER: A METHOD FOR COMBINING DIARIZATION OUTPUTS: Andreas Stolcke, Takuya Yoshioka, Microsoft, United States
- ASR-3.12: CHARACTER-AWARE ATTENTION-BASED END-TO-END SPEECH RECOGNITION: Zhong Meng, Yashesh Gaur, Jinyu Li, Yifan Gong, Microsoft Corporation, United States
The post Making machines recognize and transcribe conversations in meetings using audio and video appeared first on Microsoft Research.