
This post has been republished via RSS; it originally appeared at: Microsoft Research.
Today, we are proud to announce DeepSpeed MoE, a high-performance system that supports massive scale mixture of experts (MoE) models as part of the DeepSpeed optimization library. MoE models are an emerging class of sparsely activated models that have sublinear compute costs with respect to their parameters. For example, the Switch Transformer consists of 1.6 trillion parameters, while the compute required to train it is approximately equal to that of a 10 billion-parameter dense model. This increase in model size offers tremendous accuracy gains for a constant compute budget.
However, supporting these MoE models with trillions of parameters requires a complex combination of multiple forms of parallelism that is simply not available in current MoE systems. DeepSpeed MoE overcomes these challenges through a symphony of multidimensional parallelism and heterogenous memory technologies, such as Zero Redundancy Optimizer (ZeRO) and ZeRO-Offload, harmoniously coming together to support massive MoE models—even on limited GPU resources—achieving efficiency, scalability, and ease-of-use. It enables 3.5 trillion-parameter models on 512 GPUs, 8x larger than existing work, while achieving 100 teraflops (TFLOPS) per GPU and attaining near-linear scalability with respect to the number of GPUs.
Besides supporting the most ambitious scale MoE models, DeepSpeed MoE boosts the development productivity and resource efficiency of training modestly sized MoE models in production scenarios, which may be of broader interest to the deep learning (DL) community. As an example, we use it to train Z-code MoE, a production-quality, multilingual, and multitask language model with 10 billion parameters, achieving state-of-the-art results on machine translation and cross-lingual summarization tasks.
Massive MoE training: 8x larger models on the same hardware
DeepSpeed MoE supports five different forms of parallelism, and it exploits both GPU and CPU memory. Its flexible design enables users to mix different types of prevalent parallelism techniques, as shown in Table 1.
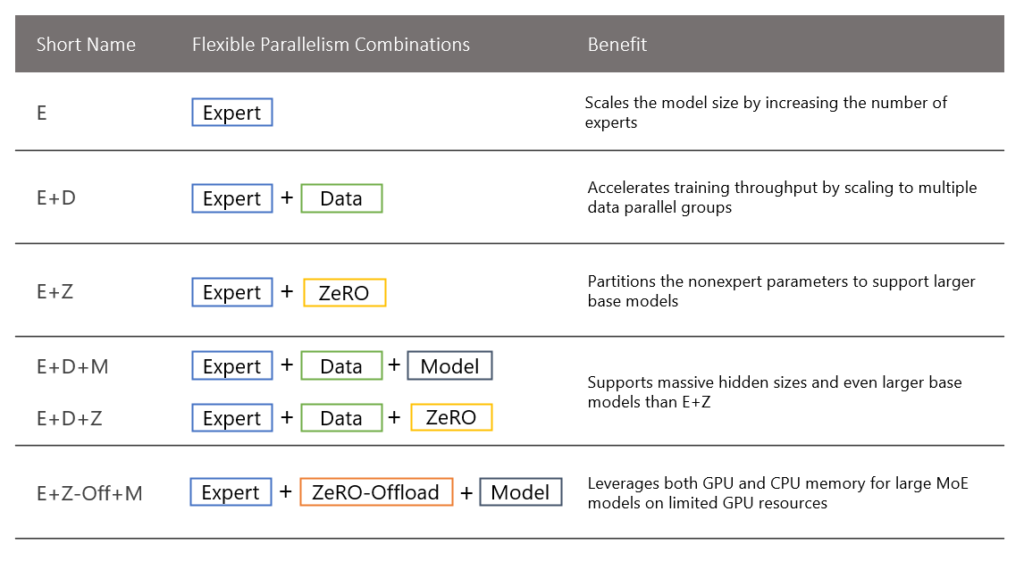
Existing MoE systems support only expert, data, and model parallelism or a subset of them. This leads to three major limitations: i) They replicate the base model (part of the model without expert parameters) across data-parallel GPUs, resulting in wasted memory, (ii) They need model parallelism to scale the base model to go beyond 1.4 billion parameters, requiring nontrivial model code refactoring, and iii) The total MoE model size is restricted by the total available GPU memory.
By systematically combining expert, model, and ZeRO parallelism, DeepSpeed MoE surpasses the first two limitations, supporting base models with up to 15 billion parameters, larger than the base model of the Switch Transformer (Switch-C 1.6 trillion parameters with a base model size of less than 5 billion parameters). This is over 10x larger compared with existing MoE systems that can support only 1.4 billion parameters without adding the complexity of model parallelism. When combined with model parallelism, the base model alone can have over 100 billion parameters, which is simply not possible with existing systems.
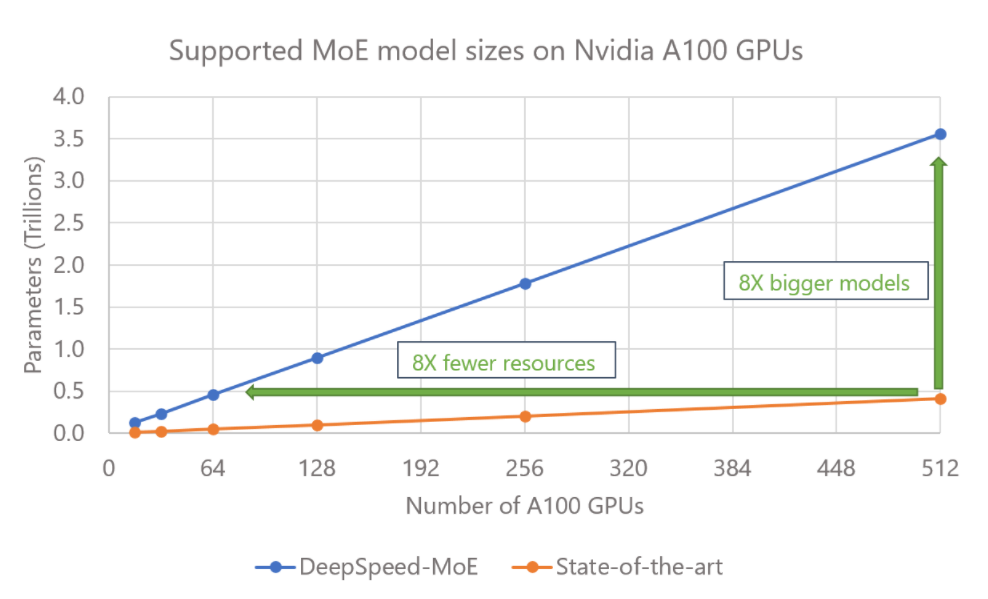
In addition, with support for ZeRO-Offload, DeepSpeed MoE transcends the GPU memory wall, supporting MoE models with 3.5 trillion parameters on 512 NVIDIA A100 GPUs by leveraging both GPU and CPU memory. This is an 8x increase in the total model size (3.5 trillion vs. 400 billion) compared with existing MoE systems that are limited by the total GPU memory. Alternatively, DeepSpeed MoE achieves the same model scale with 8x fewer resources (400 billion on 64 GPUs instead of 512 GPUs), as shown in Figure 1.
Increased throughput, near-linear scalability, and ease of use
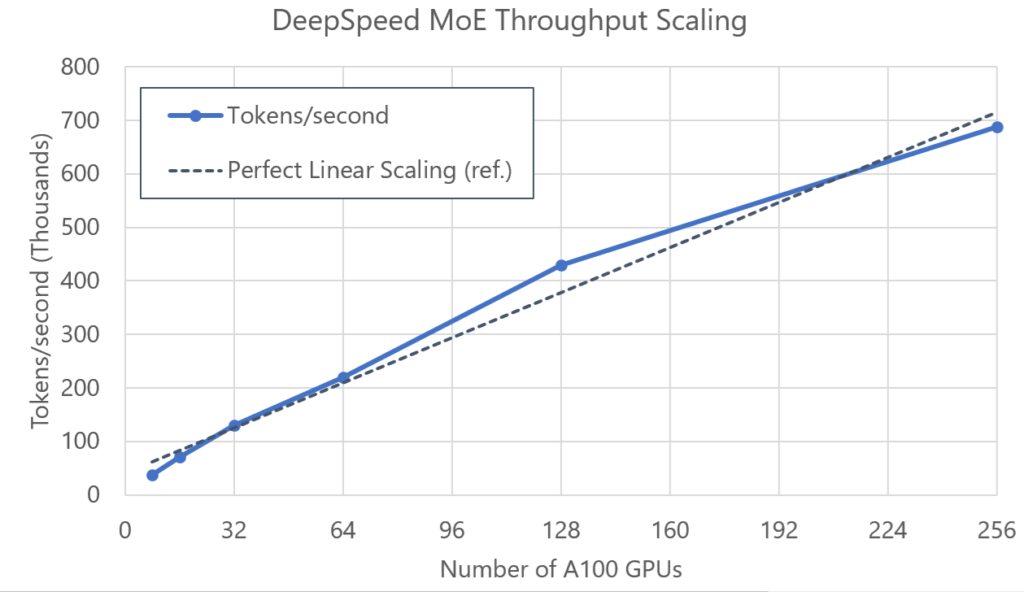
Given the sparse nature of MoE models, it is challenging to keep GPU utilization as high as dense models do. To this end, we have performed a thorough cross-analysis of system performance and model configurations for DeepSpeed MoE. For model configurations that are optimized for system performance, we achieve over 100 TFLOPS per GPU performance on NVIDIA A100 GPUs, which is on par with dense model training scenarios. Additionally, DeepSpeed MoE exhibits near-linear scalability for throughput as the number of GPUs increases, as shown in Figure 2.
While DeepSpeed MoE is a highly scalable and high-performance system, we have carefully designed its user-facing API, shown in Figure 3, to be flexible and simple to use. It enables users to enhance their models with MoE layers without complex code changes to their training pipeline. It supports various MoE-specific parameters, including number of experts, type of expert, and different gating functions (top-1, top-2, noisy, and 32-bit). In addition, we have devised a new technique called “Random Token Selection,” described in more detail in our tutorial, which greatly improves convergence, is part of the DeepSpeed library, and is enabled by default so users can take advantage of it without any code changes.

Powering state-of-the-art performance in production scenarios
Z-code, a part of Microsoft Project Turing, consists of a family of multilingual pretrained models that can be used for various downstream language tasks. The DeepSpeed library has been used to scale and accelerate the training of many Z-code models, resulting in state-of-the-art performance on various tasks. Powered by DeepSpeed MoE, we can now train MoE models that are much larger compared with dense models.
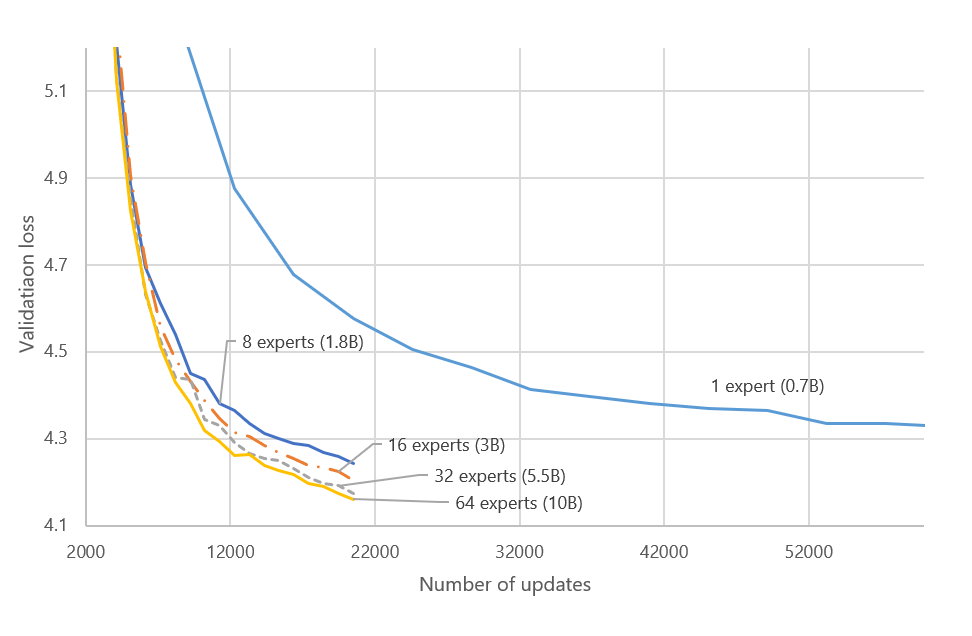
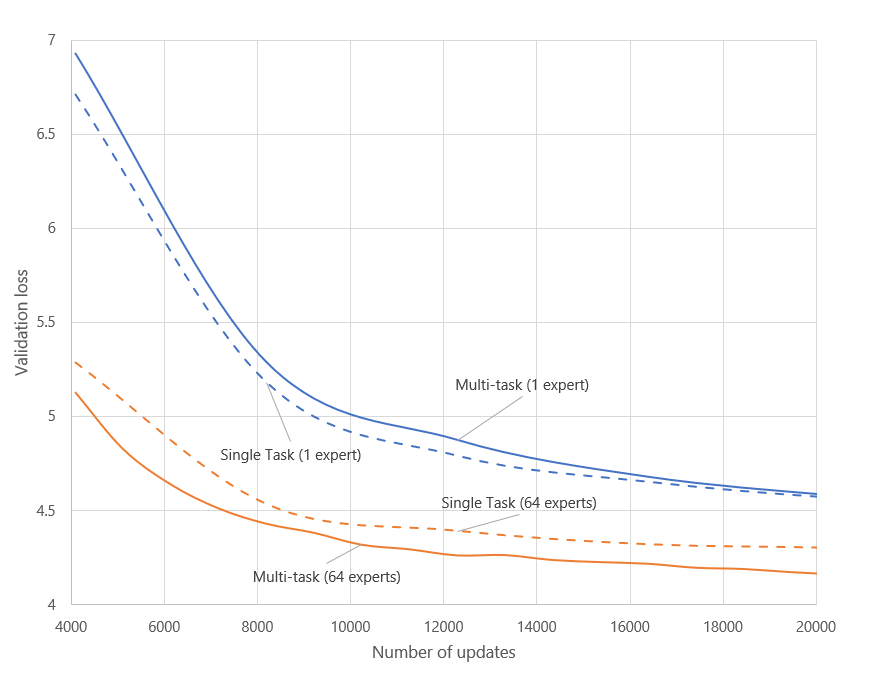
We trained a 24-layer encoder and a 12-layer decoder transformer model that had 1024 embedding and 4096 feedforward layer dimensions. By including experts in every other encoder/decoder layer, similar to the Switch Transformer, we scaled up a 700 million-parameter dense model from 1.8 billion parameters (using eight experts) to 10 billion parameters (using 64 experts). As shown in Figure 4, all MoE configurations converge faster and achieve better loss with much fewer training steps. The 10 billion-parameter model is 14 times larger than its dense equivalent model and was trained using fewer than 10 times the training steps and five times less wall-clock time, reaching a loss value of 4.3 on 64 NVIDIA A100 GPUs. This highlights the efficiency and the scalability of the MoE model.
The models were trained as generic text-to-text transformation models, similar to the T5. We trained them on machine translation and denoising auto-encoding tasks using multilingual parallel and monolingual data with 336 billion tokens in 50 languages. We used Z-code MoE (10B), shown in Figure 5, to demonstrate its efficacy on various downstream tasks. We are excited to report that the Z-code MoE model outperformed both the dense model and the highly optimized individual bilingual models.
MoE with multitask learning. We found multitask learning to be very efficient in utilizing multiple learning tasks for improving downstream tasks, especially in multilingual and multimodal setups. We also found that dense models are harder to learn in multitask setups due to the difficulty of balancing model capacity between tasks. By leveraging DeepSpeed MoE, the Z-code MoE model achieved improved convergence and higher quality with multitask training setting compared with the non-MoE model, as shown in Figure 6.
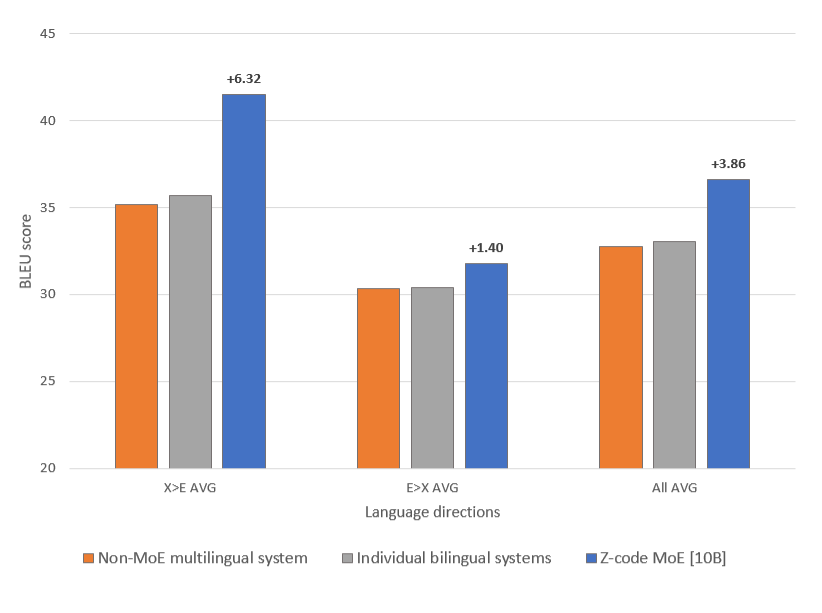
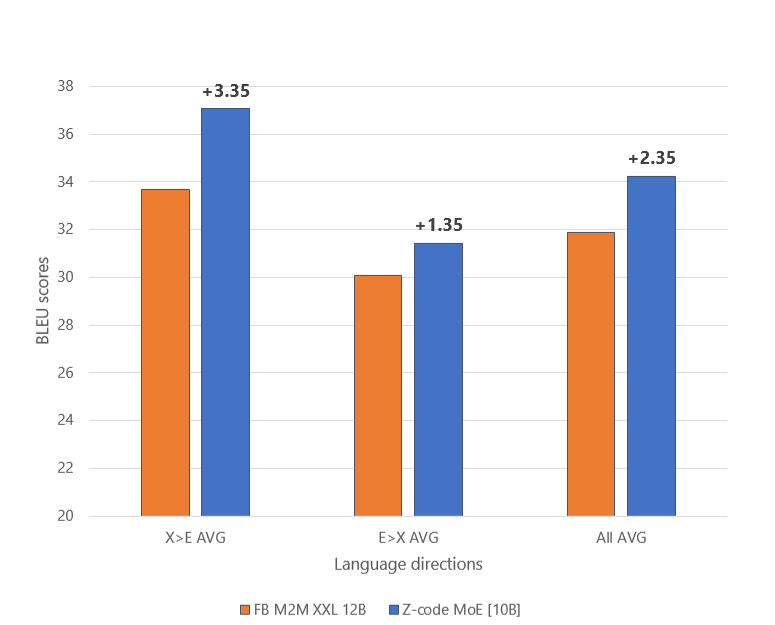
The dense model performed better with a single machine translation task while the Z-code MoE model performed better with a multitask learning setup. This enabled the Z-code MoE model to achieve state-of-the-art performance on multilingual machine translation upstream tasks, outperforming the M2M 12 billion-parameter model, as shown in Figure 7.
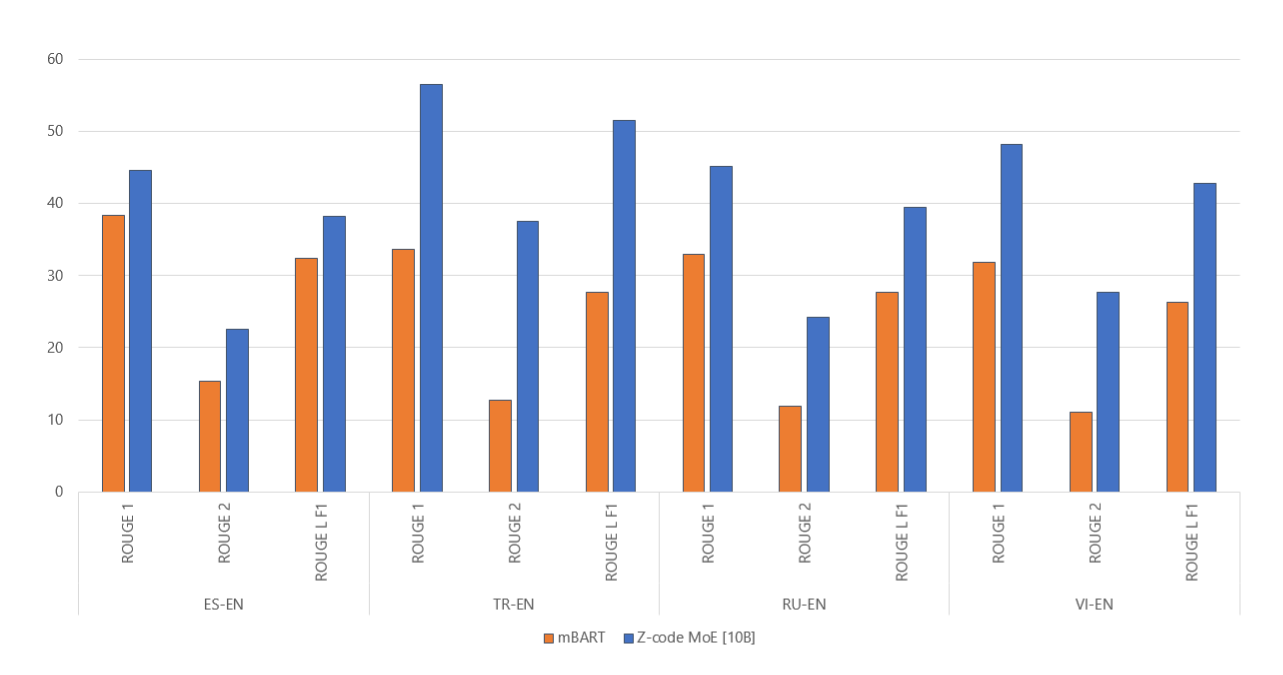
Z-code MoE as a multitask multilingual model can be utilized for various downstream language tasks. The model achieved a state-of-the-art result on the Wikilingua dataset, a multilingual abstractive summarization task, by scoring 50 percent more than the best published ROUGE score, as illustrated in Figure 8. We did this by fine-tuning the pretrained Z-code MoE model with the dataset.
Growing Z-code MoE models even bigger and better. With DeepSpeed MoE, Z-code language models are being scaled even further. We are currently working to train a 200 billion-parameter version of the model. Ongoing scaling results continue to demonstrate the efficiency of the DeepSpeed MoE implementation and the effectiveness of the Z-code MoE model. We have observed over 20,000 updates performed in less than two days with 256 NVIDIA A100 GPUs. In contrast, a dense model of similar size would take approximately 24 days to run through the same number of updates on the same hardware. Furthermore, compared with the 10 billion-parameter version, Z-code MoE 200B uses similar training time and achieves higher accuracy.
As demonstrated above, MoE models with fewer resources, excellent throughput, and near-linear scalability can achieve great results. We’re confident that our memory-efficient, high-performance, and easy-to-use MoE implementation will help accelerate the development of your production models and help power the ambition of training multibillion- and multitrillion-parameter MoE models. Please visit the DeepSpeed website and the GitHub repository for code, tutorials, and documentation on DeepSpeed MoE.
About the Z-code Team:
The Z-code team comprises a group of researchers and engineers: Young Jin Kim, Alex Muzio, Felipe Cruz Salinas, Liyang Lu, Amr Hendy, Hany Hassan Awadalla (team lead)—who are part of Azure AI and Project Turing, focusing on building multilingual, large-scale language models that support various production teams.
About the DeepSpeed Team:
We are a group of system researchers and engineers—Samyam Rajbhandari, Ammar Ahmad Awan, Conglong Li, Minjia Zhang, Jeff Rasley, Reza Yazdani Aminabadi, Elton Zheng, Cheng Li, Olatunji Ruwase, Shaden Smith, Arash Ashari, Niranjan Uma Naresh, Jeffrey Zhu, Yuxiong He (team lead)—who are enthusiastic about performance optimization of large-scale systems. We have recently focused on deep learning systems, optimizing deep learning’s speed to train, speed to convergence, and speed to develop.
If this type of work interests you, the DeepSpeed team is hiring both researchers and engineers! Please visit our careers page.
The post DeepSpeed powers 8x larger MoE model training with high performance appeared first on Microsoft Research.