
This post has been republished via RSS; it originally appeared at: Ask the Directory Services Team articles.
First published on TechNet on Dec 04, 2017hi!
Get your crash helmets on and strap into your seatbelts for a JET engine / ESE database special...
This is Linda Taylor, Senior AD Escalation Engineer from the UK here again. And WAIT...... I also somehow managed to persuade Brett Shirley to join me in this post. Brett is a Principal Software Engineer in the ESE Development team so you can be sure the information in this post is going to be deep and confusing but really interesting and useful and the kind you cannot find anywhere else :- )
BTW, Brett used to write blogs before he grew up and got very busy. And just for fun, you might find this old
“Brett” classic
entertaining. I have never forgotten it. :- )
Back to today's post...this will be a rather more grown up post, although we will talk about DITs but in a very scientific fashion.
In this post, we will start from the ground up and dive deep into the overall file format of an ESE database file including practical skills with
esentutl
such as how to look at raw database pages. And as the title suggests this is Part1 so there will be more!
What is an ESE database?
Let’s start basic. The Extensible Storage Engine (ESE), also known as JET Blue, is a database engine from Microsoft that does not speak SQL. And Brett also says … For those with a historical bent, or from academia, and remember ‘before SQL’ instead of ‘NoSQL’ ESE is modelled after the
ISAMs (indexed sequential access method)
that were vogue in the mid-70s. ;-p
If you work with Active Directory (which you must do if you are reading this post :-) then you will (I hope!) know that it uses an ESE database. The respective binary being,
esent.dll
(or Brett loves exchange, it's
ese.dll
for the Exchange Server install). Applications like active directory are all ESE clients and use the
JET APIs
to access the ESE database.
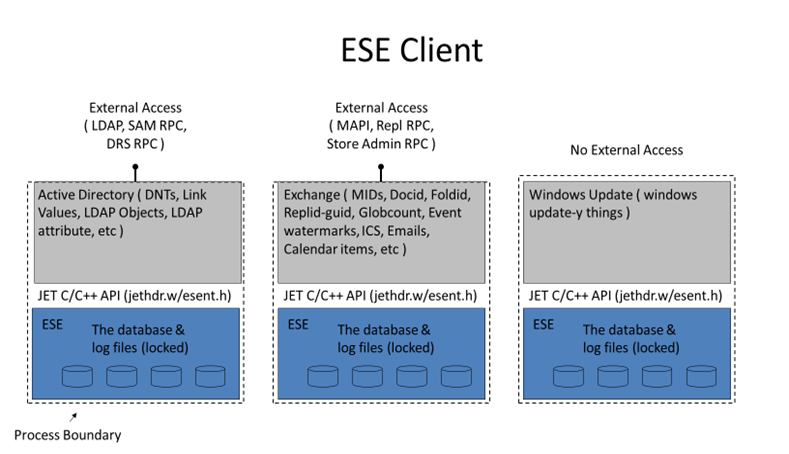
This post will dive deep into the Blue parts above. The ESE side of things. AD is one huge client of ESE, but there are many other Windows components which use an ESE database (and non-Microsoft software too), so your knowledge in this area is actually very applicable for those other areas. Some examples are below:

Tools
There are several built-in command line tools for looking into an ESE database and related files.
-
esentutl . This is a tool that ships in Windows Server by default for use with Active Directory, Certificate Authority and any other built in ESE databases. This is what we will be using in this post and can be used to look at any ESE database.
-
eseutil . This is the Exchange version of the same and gets installed typically in the Microsoft\Exchange\V15\Bin sub-directory of the Program Files directory.
-
ntdsutil . Is a tool specifically for managing an AD or ADLDS databases and cannot be used with generic ESE databases (such as the one produced by Certificate Authority service). This is installed by default when you add the AD DS or ADLDS role.
For read operations such as dumping file or log headers it doesn’t matter which tool you use. But for operations which write to the database you MUST use the matching tool for the application and version (for instance it is not safe to run esentutl /r from Windows Server 2016 on a Windows Server 2008 DB). Further throughout this article if you are looking at an Exchange database instead, you should use eseutil.exe instead of esentutl.exe. For AD and ADLDS always use ntdsutil or esentutl. They have different capabilities, so I use a mixture of both. And Brett says that If you think you can NOT keep the read operations straight from the write operations, play it safe and match the versions and application.
During this post, we will use an AD database as our victim example. We may use other ones, like ADLDS for variety in later posts.
Database logical format - Tables
Let’s start with the logical format. From a logical perspective, an ESE database is a set of tables which have rows and columns and indices.
Below is a visual of the list of tables from an AD database in Windows Server 2016. Different ESE databases will have different table names and use those tables in their own ways.

In this post, we won’t go into the detail about the DNTs, PDNTs and how to analyze an AD database dump taken with LDP because this is AD specific and here we are going to look at ESE specific level. Also, there are other blogs and sources where this has already been explained. for example, here on AskPFEPlat. However, if such post is wanted, tell me and I will endeavor to write one!!
It is also worth noting that all ESE databases have a table called MSysObjects and MSysObjectsShadow which is a backup of MSysObjects. These are also known as “the catalog” of the database and they store metadata about client’s schema of the database – i.e.
-
All the tables and their table names and where their associated B+ trees start in the database and other miscellaneous metadata.
-
All the columns for each table and their names (of course), the type of data stored in them, and various schema constraints.
-
All the indexes on the tables and their names, and where their associated B+ trees start in the database.
This is the boot-strap information for ESE to be able to service client requests for opening tables to eventually retrieve rows of data.
Database physical format
From a physical perspective, an ESE database is just a file on disk. It is a collection of fixed size pages arranged into B+ tree structures. Every database has its page size stamped in the header (and it can vary between different clients, AD uses 8 KB). At a high level it looks like this:

The first “page” is the Header (H).
The second “page” is a Shadow Header (SH) which is a copy of the header.
However, in ESE “page number” (also frequently abbreviated “pgno”) has a very specific meaning (and often shows up in ESE events) and the first NUMBERED page of the actual database is page number / pgno 1 but is actually the third “page” (if you are counting from the beginning :-).
From here on out though, we will not consider the header and shadow header proper pages, and page number 1 will be third page, at byte offset = <page size> * 2 = 8192 * 2 (for AD databases).
If you don’t know the page size, you can dump the database header with esentutl /mh.
Here is a dump of the header for an NTDS.DIT file – the AD database:

The page size is the cbDbPage. AD and ADLDS uses a page size of 8k . Other databases use different page sizes.
A caveat is that to be able to do this, the database must not be in use. So, you’d have to stop the NTDS service on the DC or run esentutl on an offline copy of the database.
But the good news is that in WS2016 and above we can now dump a LIVE DB header with the /vss switch! The command you need would be "esentutl /mh ntds.dit /vss” (note: must be run as administrator).
All these numbered database pages logically are “owned” by various B+ trees where the actual data for the client is contained … and all these B+ trees have a “type of tree” and all of a tree’s pages have a “placement in the tree” flag (Root, or Leaf or implicitly Internal – if not root or leaf).
Ok, Brett, that was “proper” tree and page talk - I think we need some pictures to show them...
Logically the ownership / containing relationship looks like this:

More about B+ Trees
The pages are in turn arranged into B+ Trees. Where top page is known as the ‘Root’ page and then the bottom pages are ‘Leaf’ pages where all the data is kept. Something like this (note this particular example does not show ‘Internal’ B+ tree pages):

-
The upper / parent page has partial keys indicating that all entries with 4245 + A* can be found in pgno 13, and all entries with 4245 + E* can be found in pgno 14, etc.
-
Note this is a highly simplified representation of what ESE does … it’s a bit more complicated.
-
This is not specific to ESE; many database engines have either B trees or B+ trees as a fundamental arrangement of data in their database files.
You should know that there are different types of B+ trees inside the ESE database that are needed for different purposes. These are:
-
Data / Primary Trees – hold the table’s primary records which are used to store data for regular (and small) column data.
-
Long Value (LV) Trees – used to store long values . In other words, large chunks of data which don't fit into the primary record.
-
Index trees – these are B+Trees used to store indexes.
-
Space Trees – these are used to track what pages are owned and free / available as new pages for a given B+ tree. Each of the previous three types of B+ Tree (Data, LV, and index), may (if the tree is large) have a set of two space trees associated with them.
Each Row of a table is limited to 8k (or whatever the page size is) in Active Directory and AD LDS. I.e. so each record has to fit into a single database page of 8k..but you are probably aware that you can fit a LOT more than 8k into an AD object or an exchange e-mail! So how do we store large records?
Well, we have different types of columns as illustrated below:

Tagged columns can be split out into what we call the Long Value Tree. So in the tagged column we store a simple 4 byte number that’s called a LID (Long Value ID) which then points to an entry in the LV tree. So we take the large piece of data, break it up into small chunks and prefix those with the key for the LID and the offset.
So, if every part of the record was a LID / pointer to a LV, then essentially we can fit 1300 LV pointers onto the 8k page. btw, this is what creates the 1300 attribute limit in AD . It’s all down to the ESE page size.
Now you can also start to see that when you are looking at a whole AD object you may read pages from various trees to get all the information about your object. For example, for a user with many attributes and group memberships you may have to get data from a page in the ”datatable” \ Primary tree + “datatable” \ LV tree + sd_table \ Primary tree + link_table \ Primary tree.
Index TreesAn index is used for a couple of purposes. Firstly, to make a list of the records in an intelligent order, such as by surname in an alphabetical order. And then secondly to also cut down the number of records which sometimes greatly helps speed up searches (especially when the ‘selectivity is high’ – meaning few entries match).
Below is a visual illustration (with the B+ trees turned on their side to make the diagram easier) of a primary index which is the DNT index in the AD Database – the Data Tree. And a secondary index of dNSHostName. You can see that the secondary index only contains the records which has a dNSHostName populated. It is smaller.

You can also see that in the secondary index, the primary key is the data portion (the name) and then the data is the actual Key that links us back to the REAL record itself.
Inside a Database page
Each database page has a fixed header . And the header has a checksum as well as other information like how much free space is on that page and which B-tree it belongs to.
Then we have these things called TAGS (or nodes), which store the data.
A node can be many things, such as a record in a database table or an entry in an index.
The TAGS are actually out of order on the page, but order is established by the tag array at end.
-
TAG 0 = Page External Header
This contains variable sized special information on the page, depending upon the type of B-tree and type of page in B tree (space vs. regular tree, and root vs. leaf).
-
TAG 1,2,3, etc are all “nodes” or lines, and the order is tracked.
The key & data is specific to the B Tree type.
And TAG 1 is actually node 0!!! So here is a visual picture of what an ESE database page looks like:

It is possible to calculate this key if you have an object's primary key. In AD this is a DNT.
The formulae for that (if you are ever crazy enough to need it) would be:
-
Start with 0x7F, and if it is a signed INT append a 0x80000000 and then OR in the number
-
For example 4248 –> in hex 1098 –> as key 7F80001098 (note 5 bytes).
-
Note: Key buffer uses big endian, not little endian (like x86/amd64 arch).
-
If it was a 64-bit int, just insert zeros in the middle (9 byte key).
-
If it is an unsigned INT, start with 0x7F and just append the number.
-
Note: Long Value (LID) trees and ESE’s Space Trees (pgno) are special, no 0x7F (4 byte keys).
-
And finally other non-integers column types, such as String and Binary types, have a different more complicated formatting for keys.
Why is this useful? Because, for example you can take a DNT of an object and then calculate its key and then seek to its page using esentutl.exe dump page /m functionality and /k option.
The Nodes also look different (containing different data) depending on the ESE B+tree type. Below is an illustration of the different nodes in a Space tree, a Data Tree, a LV tree and an Index tree.

The green are the keys. The dark blue is data.
What does a REAL page look like?You can use esentutl to dump pages of the database if you are investigating some corruption for example.
Before we can dump a page, we want to find a page of interest (picking a random page could give you just a blank page) … so first we need some info about the table schema, so to start you can dump all the tables and their associated root page numbers like this :

Note, we have findstring’d the output again to get a nice view of just all the tables and their pgnoFDP and objidFDP. Findstr.exe is case sensitive so use the exact format or use /i switch.
objidFDP identifies this table in the catalog metadata. When looking at a database page we can use its objidFDP to tell which table this page belongs to.
pgnoFDP is the page number of the Father Data Page – the very top page of that B+ tree , also known as the root page. If you run esentutl /mm <dbname> on its own you will see a huge list of every table and B-tree (except internal “space” trees) including all the indexes.
So, in this example page 31 is the root page of the datatable here.
Dumping a pageYou can dump a page with esentutl using /m and /p. Below is an example of dumping page 31 from the database - the root page of the “datatable” table as above.


The objidFDP is the number indicating which B-tree the page belongs to. And the cbFree tells us how much of this page is free. (cb = count of bytes). Each database page has a double header checksum – one ECC (Error Correcting Code) checksum for single bit data correction, and a higher fidelity XOR checksum to catch all other errors, including 3 or more bit errors that the ECC may not catch. In addition, we compute a logged data checksum from the page data, but this is not stored in the header, and only utilized by the Exchange 2016 Database Divergence Detection feature.
You can see this is a root page and it has 3 nodes (4 TAGS – remember TAG1 is node 0 also known as line 0! :-) and it is nearly empty! (cbFree = 8092 bytes, so only 100 bytes used for these 3 nodes + page header + external header).
The objidFDP tells us which B-Tree this page belongs to.
And notice the PageFlushType, which is related to the JET Flush Map file we could talk about in another post later.
The nodes here point to pages lower down in the tree. And we could dump a next level page (pgno: 1438)....and we can see them getting deeper and more spread out with more nodes.


So you can see this page has 294 nodes! Which again all point to other pages. It is also a ParentOfLeaf meaning these pgno / page numbers actually point to leaf pages (with the final data on them).
Are you bored yet?

Or are you enjoying this like a geek? either way, we are nearly done with the page internals and the tree climbing here.
If you navigate more down, eventually you will get a page with some data on it like this for example, let's dump page 69 which TAG 6 is pointing to:


So this one has some data on it (as indicated by the “Leaf page” indicator under the fFlags).
Finally, you can also dump the data - the contents of a node (ie TAG) with the /n switch like this:

Remember: The /n specifier takes a pgno : line or node specifier … this means that the :3 here, dumped TAG 4 from the previous screen. And note that trying to dump “/n69:4” would actually fail.
This /n will dump all the raw data on the page along with the information of columns and their contents and types. The output also needs some translation because it gives us the columnID (711 in the above example) and not the attribute name in AD (or whatever your database may be). The application developer would then be able to translate those column IDs to some meaningful information. For AD and ADLDS, we can translate those to attribute names using the source code.
Finally, there really should be no need to do this in real life, other than in a situation where you are debugging a database problem. However, we hope this provided a good and ‘realistic’ demo to help understand and visualize the structure of an ESE database and how the data is stored inside it!
Stay tuned for more parts .... which Brett says will be significantly more useful to everyday administrators! ;-)
The End!
Linda & Brett