
This post has been republished via RSS; it originally appeared at: Running SAP Applications on the Microsoft Platform articles.
First published on MSDN on Oct 09, 2015For customers of SAP (and others) it is very important that the runtime of the different reports or programs is predictable, fast and stable. From time to time it happens that former fast query executions deteriorate in their runtime and need much more time than before. For most of the customers it is totally unclear why this happens and what the root may be. In this blog I will try to describe how changing query runtimes can be explained by uneven data distribution and query compilation.
SQL Server, like most other DBMS, is caching query plans to reduce the CPU and memory overhead of compiling statements. The cache that is used for the plans is called plan, statement or procedure cache. A plan of a query is compiled and stored when the query is executed the first time. The SQL Server optimizer will create the access plan based on the given parameters for the WHERE clause of the first execution of the query. This cached plan then has to used for all subsequent executions of the same query, independently of the parameter sets of the subsequent executions. So the values of the first execution parameters determine the plan efficiency of the first and all subsequent executions.
I'd like to discuss the underlying problem with an easy example. I set up a table named ORDERS with customer orders. It has only 7 columns

a primary key (ORDERNUMBER) and three nonclustered indexes, one for CUSTOMER_ID alone, one for CUSTOMER_ID with ITEMS and one for CUSTOMER_ID with REGION.

Side Note: This set of indexes is not fully optimized as the ORDERS_NC_CUSTOMER_ID index is redundant, as both the ORDERS_NC_ITEMS or ORDERS_NC_REGION can be used for the same purpose (searching for CUSTOMER_ID only). The indexes are only created to show the problem more clearly. In general the order of the columns in an index should follow their selectivity, starting with the most selective filed at the beginning down to the least selective field at the end.
I inserted 160.000 rows with fictional orders of 20 customers. They all have more or less the same amount of orders (around 4.700 orders each), only the customer with the ID number of 2 has only 250 orders and the busy customer with ID = 15 has 76000 orders. The graph of the distribution looks like:
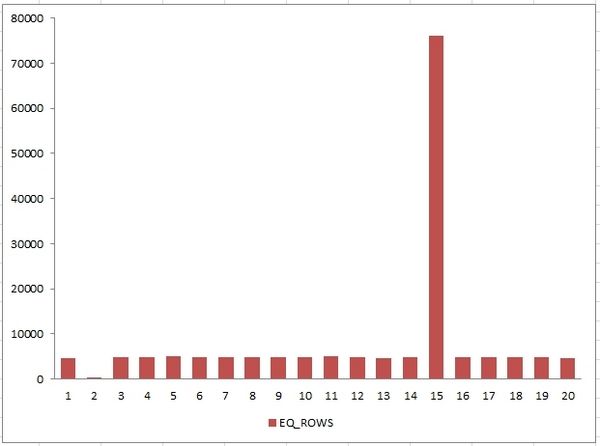
This will be our starting point. As SAP uses at least since version 640 prepared statements for the access to the data in SQL Server databases, I'm using simple and prepared statements to select from this table:
SELECT REGION, ITEMS FROM ORDERS WHERE CUSTOMER_ID = @P1
It is searching for an CUSTOMER_ID and will give back the REGION and ITEMS of this customer. The complete execution looks like:
DBCC FREEPROCCACHE -- Clear the cache so that we get a new plan every time (only for testing)
GO
DECLARE @P2 INT ;
EXEC sp_prepexec @P2 output,N'@P2 INT', N'SELECT REGION, ITEMS FROM ORDERS WHERE CUSTOMER_ID = @P1',@P1 = 2
EXEC sp_unprepare @P1 ;
GO
Setting @P1 either to 2 (for the small customer), to 15 (for the busy customer with many orders) or to any other ID (e.g. 12), we might see different plans of the SQL Server to get the data. I ran all three execution in one batch to see the relative cost of each statement compared to the other two.
Lets get started with ID = 12, one of the normal customers with an average amount of orders. As we have an index on CUSTOMER_ID and we are selecting only roughly 4.700 rows out of 160.000 rows (2,9 %) we could expect that the optimizer will use an index.

SQL Server is choosing two index intersections with a Hash Match, the first between the ITEMS and the CUSTOMER_ID index and with resulting row set with the REGION index. The cost of this query was 27 % out of 100 % for all three queries (CUSTOMER_ID = 2,12 and 15), so this query is cheaper as the expected average of 33 %.
In this plan SQL Server gives us an index recommendation to speed up this statement. The recommended index has the CUSTOMER_ID as the only key column, but includes the REGION and ITEMS as an included fields. This would avoid the lookup of the rows to get the REGION and ITEMS, as they would be included in the index directly. SAP supports included columns in index definitions.
This was a fairly complex plan for customer 12, so what can we expect from the big customer (number 15)?

SQL Server was choosing a full table scan to retrieve the data, as we are selecting 74.000 rows out of 160.000 rows (46 %). Therefore the SQL Server is choosing the primary key as he has to retrieve REGION and ITEMS from the table and none of the indexes contain both columns. The cost of the query lies at 70 %, what was expected due to the table scan. This query would benefit from the recommended index as well, as the SQL Server then has to scan only the smaller index instead of the complete table. The tipping point between an Index Seek and a Table Scan lies somewhere between 2-5 % of the rows of the table. If SQL Server estimates more that this amount of rows to be returned, it will perform more likely a table scan. If there are less rows an Index Seek or Index Range Scan is more likely. There are many other factors beside the amount of rows that are considered by SQL Server when the plan is compiled.
After this expensive plan, what will customer number 2 with only 250 rows give us ?

SQL Server uses again an index intersection, but this time only one between the REGION and the ITEMS index. The cost of this query is very low with only 3%.
So we got three different plans, depending on which parameter value was use to create the plan. In my example I created a new plan every time, but what will happen if we have to reuse the same plan all the time as it is the case for an SAP system ? The plan will be the same for all three executions !
| Customer 12 |

|
| Customer 15 |

|
| Customer 2 |
|
When you look at the plans you will see that the plans that were created for customer 12 and 2 show a yellow warning for the customer 15 execution. This is because this plan is so expensive that it spools data into tempdb for the execution with customer 15, what will slow down the execution even more.
What we proved today is, that depending on the initial value that is used to compile the plan and the selectivity of the value, the plan for the exact same statement can be totally different and might be not optimal for all subsequent executions of the same statement.
But why can a plan change happen ? There are many causes for a plan eviction from the cache or a recompilation of the plan. Here only the most important and most frequent ones:
| Changes made to a table or view referenced by the query. | Installation of a SAP Support package or transport |
| Changes to any indexes used by the execution plan | Installation of a SAP Support package or transport |
|
Updates on statistics used by the execution plan, either explicitly
|
Manually or after a certain amount of row changes. |
| The Plan fell out of the LRU Plan Cache |
When many other new plans push out the plan out
of the plan cache |
| SQL Server Service restart | Only manually |
|
An explicit call to sp_recompile to recreate the plan(s) for one
statement or table |
Only manually |
| An explicit flush of the complete plan cache | Only manually |
Solutions:
What can be the solutions in a case like this?
- Create a fitting index
SQL Server suggested a new index for two of the three executions, what will happen if we create this index ?
CREATE NONCLUSTERED INDEX ORDERS_GOOD ON [dbo].[ORDERS] ([CUSTOMER_ID])
INCLUDE ([REGION],[ITEMS])
GO
The plans for the three executions are like this:

We will get a stable plan as the plan is the same for all three parameter values. You can see the different costs for the different values, but the plan is the optimal plan for all three statements. But sometimes it is not possible to create a good index for all possible values, what else can we do ?
-
Recompile the statement at each execution
When we force SQL Server to compile the statement at each execution, we will get the best plan for all parameter sets, but with a CPU penalty as the compilations cost CPU. But based on experiences with many customer systems, CPU is not a limited resource anymore, especially with the new and powerful commodity server that available today.
How can we force a recompilation from within the SAP System ? Therefore we have to change the ABAP report to add a database hint. Given a fictional ABAP statement:
SELECT REGION, ITEMS FROM ORDERS
INTO TABLE it_orders
WHERE CUSTOMER_ID EQ it_CU_ID.
This statement uses a variable it_CU_ID to pass the customer ID to the statement and will run on the database ilk one of the above shown statements. To enable the recompilation you have to add a line with the database specific hint:
SELECT REGION, ITEMS FROM ORDERS
INTO TABLE it_orders
WHERE CUSTOMER_ID EQ it_CU_ID
%_HINTS MSSQLNT '&REPARSE&'.
The resulting SQL Server statement will include a WITH (RECOMPILE) clause. This statement is then compiled at every execution by SQL Server. -
ABAP rewrite
This is only a last-resort option and should only be used if any other solution didn't show a result. The idea behind this is, to use the unique ABAP statement ID to get separate plan. Each ABAP statement has a unique identification, which is part of the statement (Comment block at the end of the statement). So each ABAP statement will get its own plan. When we now separate the executions of the big and small customer from the "normal" ones, we will get a unique plan for each of them. The ABAP pseudo code might then look like:
IF it_CU_ID = 15 THEN
SELECT REGION, ITEMS FROM ORDERS
INTO TABLE it_orders
WHERE CUSTOMER_ID EQ it_CU_ID.
ELSE IF it_CU_ID = 2 THEN
SELECT REGION, ITEMS FROM ORDERS
INTO TABLE it_orders
WHERE CUSTOMER_ID EQ it_CU_ID.
ELSE
SELECT REGION, ITEMS FROM ORDERS
INTO TABLE it_orders
WHERE CUSTOMER_ID EQ it_CU_ID.
The selection are the same, but the underlying ABAP statement ID is different and so the plans are. There might be other ways to change the ABAP to work around distribution problems. Keep in mind that the maintenance effort and error rate might be higher when you implement something like this.
More information:
Execution Plan Caching and Reuse (MSDN article)
Parameters and Execution Plan Reuse (MSDN article)
SQL Execution Plans Part 1 or 3
SQL Execution Plans Part 2 or 3
SQL Execution Plans Part 3 or 3