
This post has been republished via RSS; it originally appeared at: Microsoft Research.
Deep learning algorithms, supported by the availability of powerful Azure computing infrastructure and massive training data, constitutes the most significant driving force in our AI evolution journey. In the past three years, Microsoft reached several historical AI milestones being the first to achieve human parity in the following public benchmark tasks that have been broadly used in the speech and language community:
- 2017: Speech Recognition on the conversational speech transcription task (Switchboard)
- 2018: Machine Translation on the Chinese to English news translation task (WMT17)
- 2019: Conversational QA on the Stanford conversational question and answering task (CoQA)
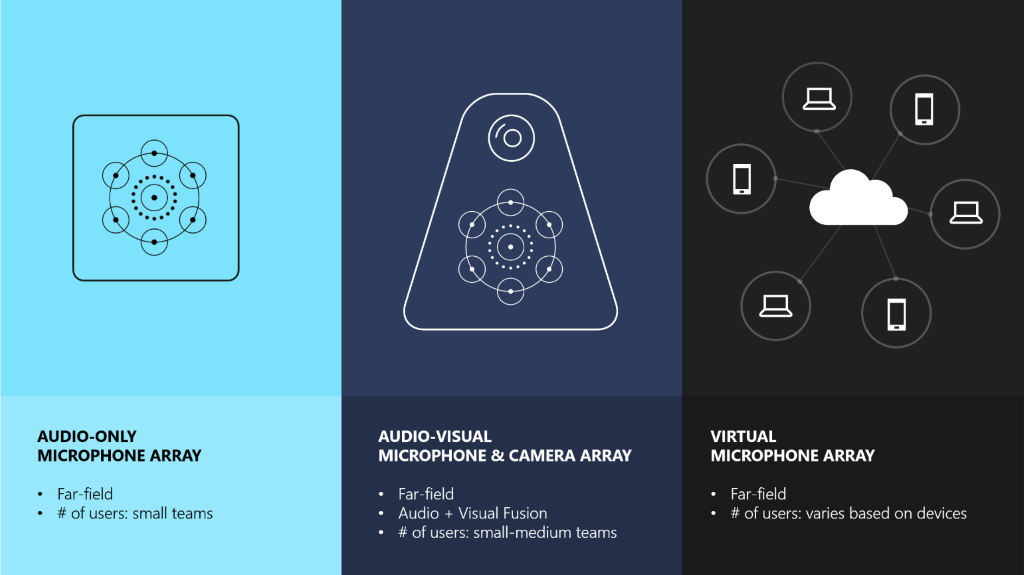
These breakthroughs have a profound impact on numerous spoken language applications from translation applications to smart loudspeakers. While smart speakers are commercially available today, most of them can only handle a single person’s speech command one at a time and require a wake-up word before issuing such a command. We have incorporated some of our significant technical breakthroughs into Azure Speech Service with a new Conversation Transcription capability, available in preview today. This capability is enhanced by the availability of audio-only or audio-visual microphone array devices via our referenced Devices SDK (DDK). This is an important step in AI’s evolution journey since ambient far-field multi-person speech transcription has been a staple of science fiction for decades.
The new Conversation Transcription capability expands Microsoft’s existing Azure speech service to enable real-time, multi-person, far-field speech transcription and speaker attribution. Paired with a Speech DDK, Conversation Transcription can effectively recognize conversational speech for a small group of people in a room and generate a transcription handling common yet challenging scenarios such as “cross-talk”.
For customers interested in piloting an end-to-end transcription solution with video capabilities, we are engaging with selected customers and Systems Integration (SI) partners such as Accenture, Avanade and Roobo to customize and integrate the Conversation Transcription solution in US and China respectively. The advanced capability is similar to what we first demonstrated in last year’s Build. We invite you to apply for the gated preview to experience how AI powered Conversation Transcription can improve collaboration and productivity. Contact us to learn more.
The Conversation Transcription capability utilizes multi-channel data including audio and visual signals from a Speech DDK that is codenamed Princeton Tower. The edge device is based on our reference-designed 360-degree audio microphone array or 360-degree fisheye camera with audio-visual fusion to support improved transcription. The edge device sends signals to Azure cloud for neural signal processing and speech recognition. Audio-only microphone array DDKs can be purchased from http://ddk.roobo.com. Advanced audio-visual microphone array DDKs are available from our SI partners.
We continue to innovate beyond the traditional microphone array and advanced audio-visual microphone array DDKs. Today we also unveiled our latest research progress (Project Denmark) that enables dynamic creation of a virtual microphone array with a set of existing devices such as mobile phones or laptops equipped with an ordinary microphone. The virtual microphone array combines existing devices like mobile phones or laptops equipped with an ordinary microphone like Lego blocks into a single larger array dynamically. Project Denmark can potentially help our customers more easily transcribe conversations anytime and anywhere using Azure speech services, with or without a dedicated microphone array DDK. Future application scenarios are broad. For example, we may pair up multiple Microsoft Translator applications to help multiple people communicate more effectively using mobile phones to minimize language barriers. Check out the latest research progress and demo from //Build Vision Keynote.
Finally, accurate speech transcription is very difficult if the domain vocabulary such as acronyms is unavailable. To solve for this, we are extending Azure custom speech recognition capabilities and enabling organizations to easily create custom speech models using their Office 365 data. For Office 365 enterprise customers opting in for this service, Azure can automatically generate a custom model leveraging Office 365 data such as Contacts, Emails, and Documents in a completely eyes-off, secure and compliant fashion. This delivers more accurate speech transcription on organization-specific vernacular such as technical terms and people names. For customers interested in piloting this new feature, we are offering a private preview for your organization to benefit from a dedicated and optimized speech service. Contact us to learn more.

Microsoft’s Azure speech services have been supporting Microsoft’s own M365 solutions as well as many 3rd party customers using the same unified speech platform. Customers from Allstate to Xiaomi have all started leveraging Azure speech services to accelerate their digital transformation. As we continue to make Azure the most effective speech and language application platform, what will you do with our amazing technologies? The opportunities are unlimited as we can further augment Azure conversation transcription with NLP technologies such as machine translation, QA, and ultimately automatic meeting minutes to help customers achieve more. Get started today.
The post New Advancements in Spoken Language Processing appeared first on Microsoft Research.