
This post has been republished via RSS; it originally appeared at: Microsoft Research.
Since the DeepSpeed optimization library was introduced last year, it has rolled out numerous novel optimizations for training large AI models—improving scale, speed, cost, and usability. As large models have quickly evolved over the last year, so too has DeepSpeed. Whether enabling researchers to create the 17-billion-parameter Microsoft Turing Natural Language Generation (Turing-NLG) with state-of-the-art accuracy, achieving the fastest BERT training record, or supporting 10x larger model training using a single GPU, DeepSpeed continues to tackle challenges in AI at Scale with the latest advancements for large-scale model training. Now, the novel memory optimization technology ZeRO (Zero Redundancy Optimizer), included in DeepSpeed, is undergoing a further transformation of its own. The improved ZeRO-Infinity offers the system capability to go beyond the GPU memory wall and train models with tens of trillions of parameters, an order of magnitude bigger than state-of-the-art systems can support. It also offers a promising path toward training 100-trillion-parameter models.
ZeRO-Infinity at a glance: ZeRO-Infinity is a novel deep learning (DL) training technology for scaling model training, from a single GPU to massive supercomputers with thousands of GPUs. It powers unprecedented model sizes by leveraging the full memory capacity of a system, concurrently exploiting all heterogeneous memory (GPU, CPU, and Non-Volatile Memory express or NVMe for short). Learn more in our paper, “ZeRO-Infinity: Breaking the GPU Memory Wall for Extreme Scale Deep Learning.” The highlights of ZeRO-Infinity include:
- Offering the system capability to train a model with over 30 trillion parameters on 512 NVIDIA V100 Tensor Core GPUs, 50x larger than state of the art.
- Delivering excellent training efficiency and superlinear throughput scaling through novel data partitioning and mapping that can exploit the aggregate CPU/NVMe memory bandwidths and CPU compute, offering over 25 petaflops of sustained throughput on 512 NVIDIA V100 GPUs.
- Furthering the mission of the DeepSpeed team to democratize large model training by allowing data scientists with a single GPU to fine-tune models larger than Open AI GPT-3 (175 billion parameters).
- Eliminating the barrier to entry for large model training by making it simpler and easier—ZeRO-Infinity scales beyond a trillion parameters without the complexity of combining several parallelism techniques and without requiring changes to user codes. To the best of our knowledge, it’s the only parallel technology to do this.
We are also pleased to announce DeepSpeed’s integration with Azure Machine Learning and open-source solutions. The DeepSpeed curated environment in Azure Machine Learning makes it easier for users to get started on Azure. DeepSpeed is now integrated in Hugging Face v4.2 and PyTorch Lightning v1.2. Hugging Face and PyTorch Lightning users can easily accelerate their models with DeepSpeed through a simple “deepspeed” flag!
Addressing the needs of large model training now and into the future with ZeRO-Infinity
In the last three years, the largest trained dense model has grown over 1,000x, from a hundred million parameters in the pre-BERT era to over a hundred billion parameters now. However, in the same duration, single GPU memory has only increased by 5x (16 GB to 80 GB). Therefore, the growth in model size has been made possible mainly through advances in system technology for training large DL models, with parallel technologies such as model parallelism, pipeline parallelism, and ZeRO allowing large models to fit in aggregate GPU memory, creating a path to training larger and more powerful models.
The state-of-the-art in large model training technology is 3D parallelism. It combines model parallelism (tensor slicing) and pipeline parallelism with data parallelism in complex ways to efficiently scale models by fully leveraging the aggregate GPU memory and compute of a cluster. 3D parallelism has been used in DeepSpeed and NVIDIA Megatron-LM, among other frameworks.
Despite the incredible capabilities of 3D parallelism for large model training, we are now arriving at the GPU memory wall. The aggregate GPU memory is simply not large enough to support the growth in model size. Even with the newest NVIDIA A100 GPUs, which have 80 GB of memory, 3D parallelism requires 320 GPUs just to fit a trillion-parameter model for training. Furthermore, 3D parallelism requires significant code refactoring from data scientists, creating a large barrier to entry. Three questions arise:
- Looking ahead, how do we support the next 1,000x growth in model size, going from models like GPT-3 with 175 billion parameters to models with hundreds of trillions of parameters?
- Focusing on the present, how can we make the large models of today accessible to more data scientists who may not have access to hundreds to GPUs currently required to fit these models?
- Can we make large model training easier by eliminating this need for model refactoring?
Today, we take a leap forward from 3D parallelism by introducing ZeRO-Infinity, a novel system capable of addressing all the above-mentioned challenges of large model training. ZeRO-Infinity extends the ZeRO family of technology with new innovations in data mapping and high-performance heterogeneous memory access, which allows ZeRO-Infinity to support massive model sizes on limited GPU resources by exploiting CPU and NVMe memory simultaneously, unencumbered by their limited bandwidth.
ZeRO-Infinity can also train these models without the need to combine multiple forms of parallelism in 3D parallelism. It does so via a novel memory-centric computation-tiling approach aimed at reducing GPU memory requirements of large individual layers that would otherwise require model parallelism (tensor slicing) to fit the model in GPU memory. In addition, ZeRO-Infinity makes large model training easy by identifying and automating all the communication required for training any arbitrary model architecture, virtually eliminating the need for any model refactoring even when scaling to trillions of parameters. Last but not least, ZeRO-Infinity offers a powerful compute-and-communication-overlap engine designed to push training efficiency to the limits by hiding as much communication latency as possible.
With all these innovations, ZeRO-Infinity redefines the capabilities of a DL system, offering unprecedented model scale that is accessible and easy to use while achieving excellent training efficiency.
Unprecedented model scale: Train 30-trillion-parameter models on 512 GPUs
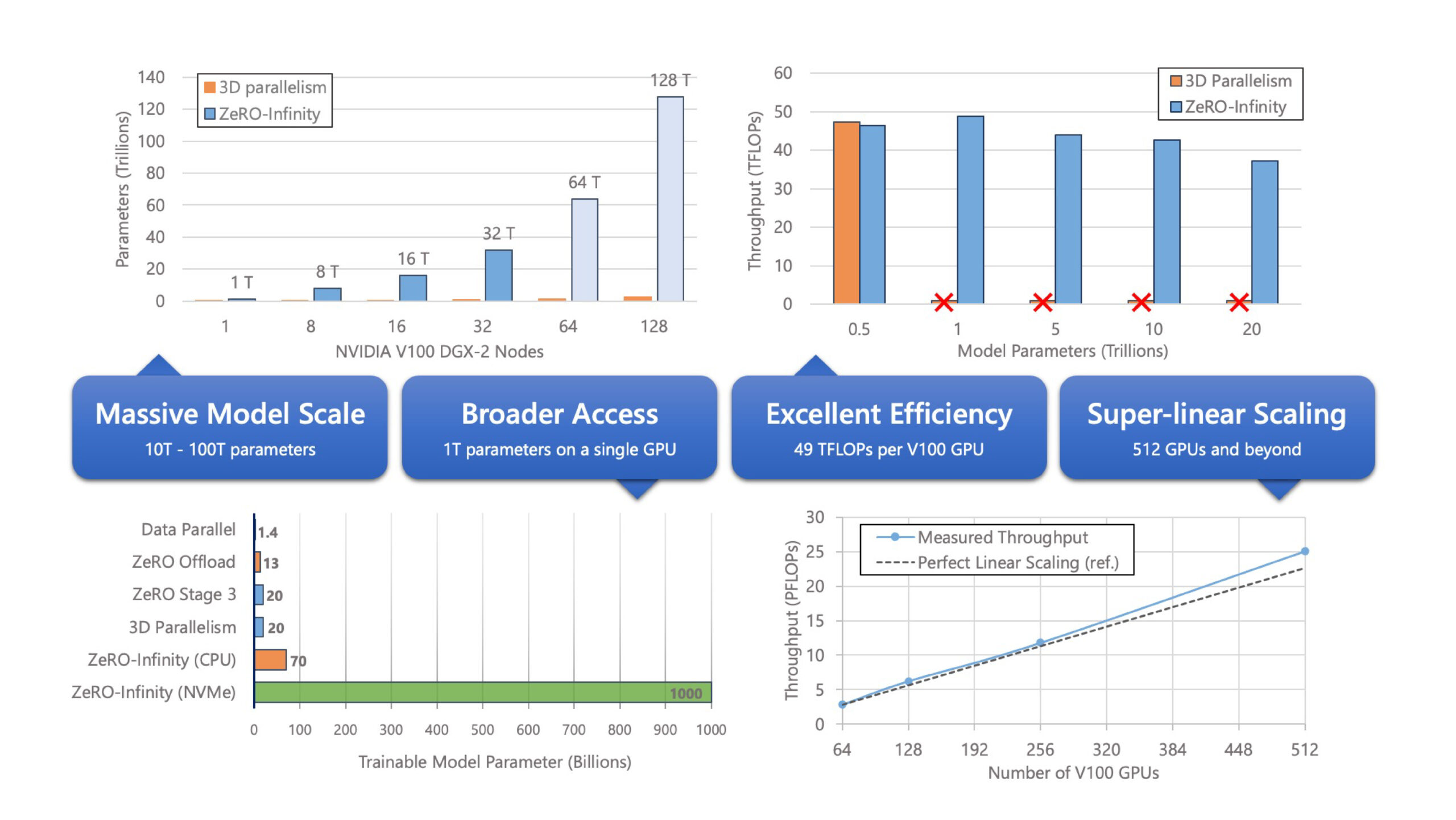
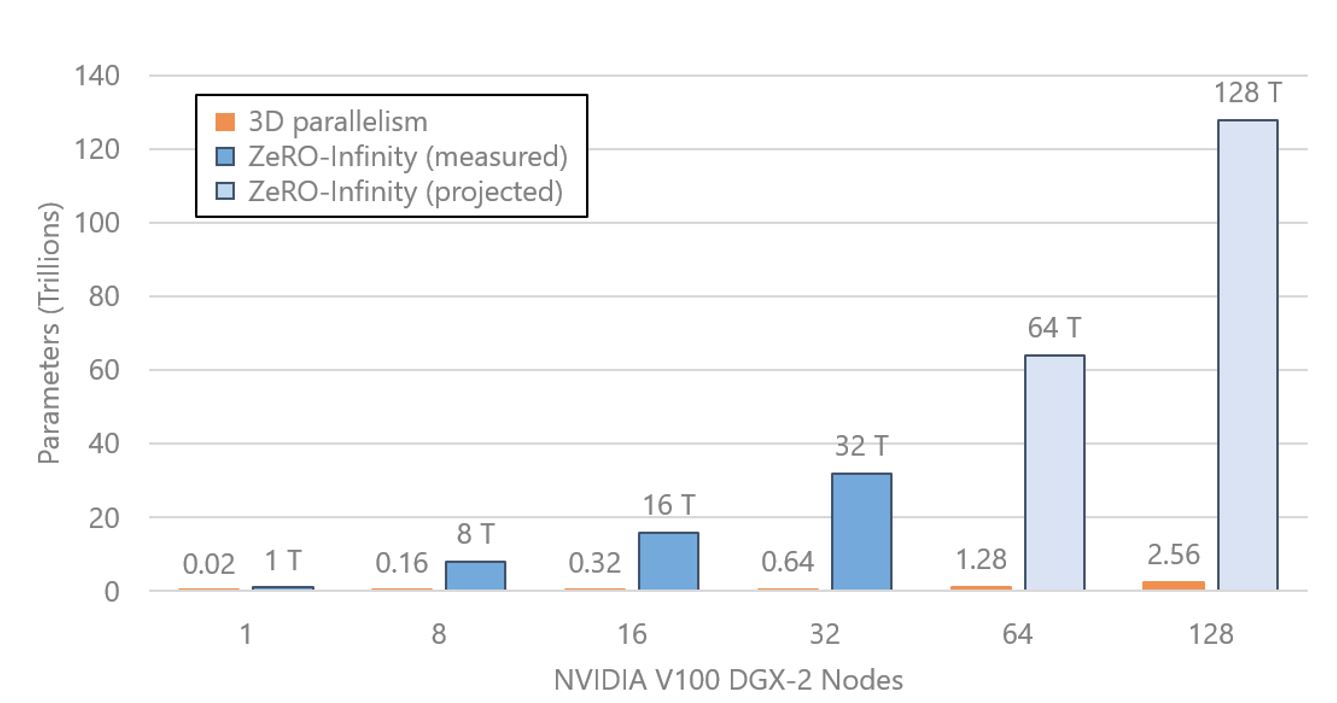
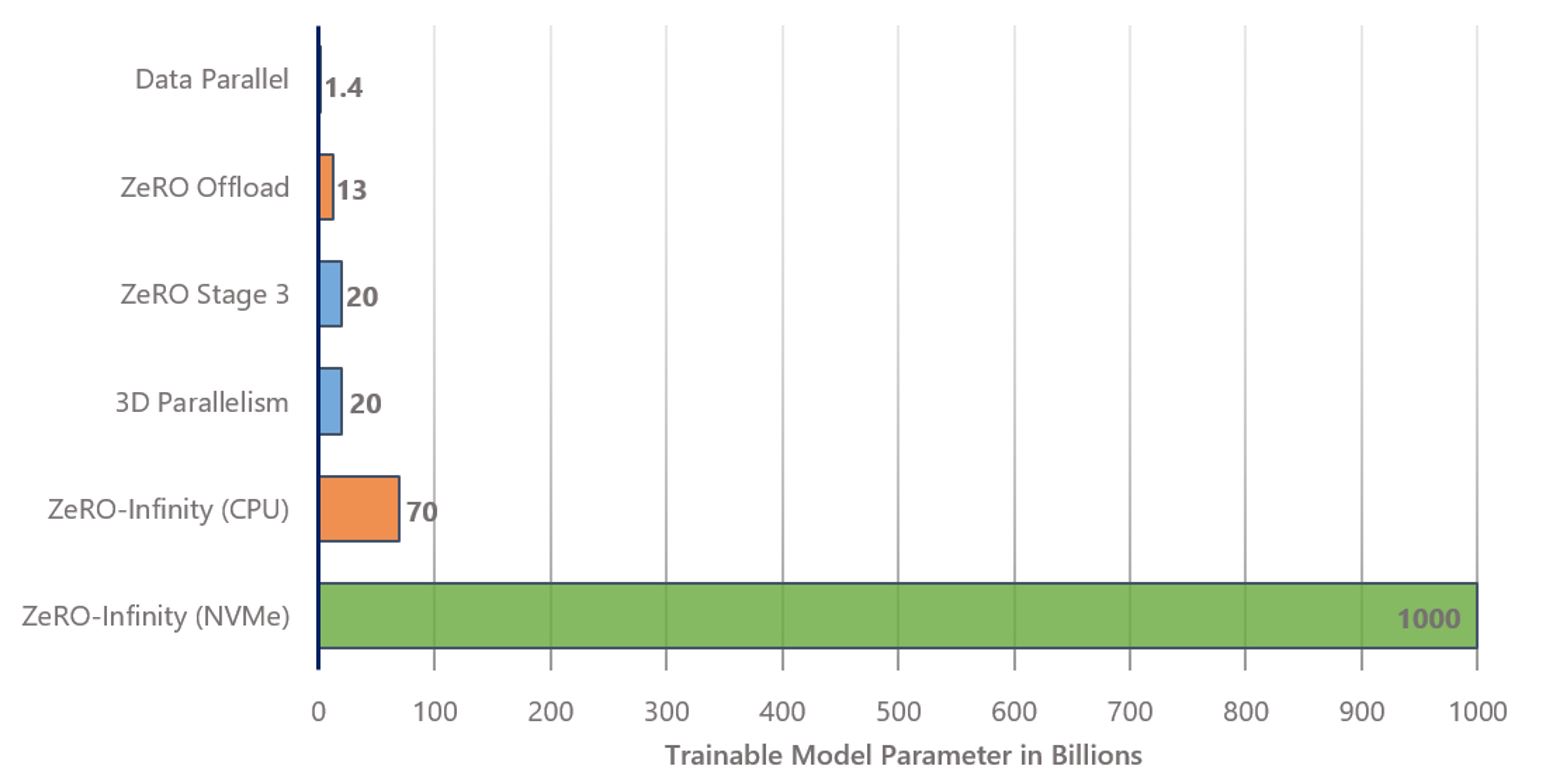
ZeRO-Infinity offers a leap of orders of magnitude in DL training system technology, opening a path to supporting the next 1,000x increase in model scale by efficiently exploiting the heterogeneous memory systems on current and future generations of hardware. It runs a model with over a trillion parameters on a single NVIDIA DGX-2 node and over 30 trillion parameters on 32 nodes (512 GPUs). With a hundred DGX-2 nodes in a cluster, we project ZeRO-Infinity can train models with over a hundred trillion parameters. (see Figure 1 for details).
To enable model training at this scale, ZeRO-Infinity extends the ZeRO family of technology with distinct innovations targeting different memory bottlenecks.
1. Stage 3 of ZeRO (ZeRO-3) allows for removing all memory redundancies in data-parallel training by partitioning model states across data-parallel processes.
This first piece in ZeRO-Infinity represents the ultimate set of memory optimization in the original ZeRO paper.
ZeRO is a family of memory optimization technologies for large-scale distributed deep learning. Unlike data parallelism (which is efficient but can only support a limited model size), model parallelism/tensor slicing (which can support larger model sizes but adds communication overhead that limits efficiency), or pipeline parallelism (which can be efficient but requires significant model code refactoring), ZeRO allows fitting larger models in memory without requiring code refactoring while remaining very efficient. ZeRO does so by eliminating the memory redundancy that is inherent in data parallelism while limiting the communication overhead to a minimum.
ZeRO removes the memory redundancies across data-parallel processes by partitioning the three model states (optimizer states, gradients, and parameters) across data-parallel processes instead of replicating them. By doing this, it boosts memory efficiency compared to classic data-parallelism while retaining its computational granularity and communication efficiency.
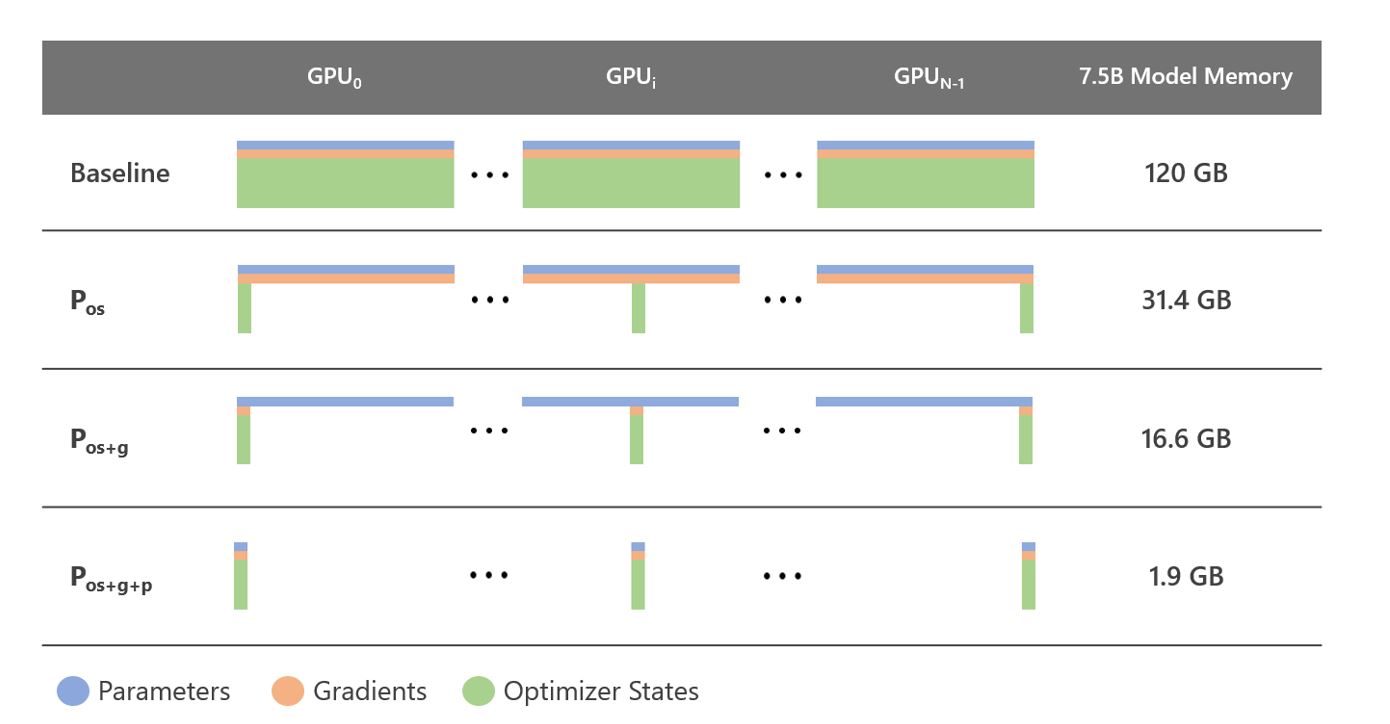
There are three stages in ZeRO corresponding to three model states, as shown in Figure 2: the first stage (ZeRO-1) partitions only the optimizer states, the second stage (ZeRO-2) partitions both the optimizer states and the gradients, and the final stage (ZeRO-3) partitions all three model states (for more details see the ZeRO paper).
During the training, ZeRO-3 ensures that the parameters required for the forward or backward pass of an operator are available right before its execution by issuing communication collective operations, such as broadcast or all-gather. After the execution of the operator, ZeRO-3 also removes the parameters as they are no longer needed until the next forward or backward pass of the operator. Additionally, during the parameter update phase of training, ZeRO-3 ensures that each data-parallel process only updates the optimizer states corresponding to the parameters that it owns. Therefore, ZeRO-3 can keep all the model states partitioned throughout the training except for the parameters that are required by the immediate computation. By leveraging ZeRO-3, ZeRO-Infinity can exploit the aggregate GPU memory available on a cluster to fit the model states. ZeRO-3 alone supports a trillion parameters with 1,024 NVIDIA V100 GPUs.
2. Infinity Offload Engine, a novel data offloading library, allows for fully exploiting modern heterogeneous memory architectures by offloading partitioned model states to CPU or NVMe device memory, which are much bigger than GPU memory.
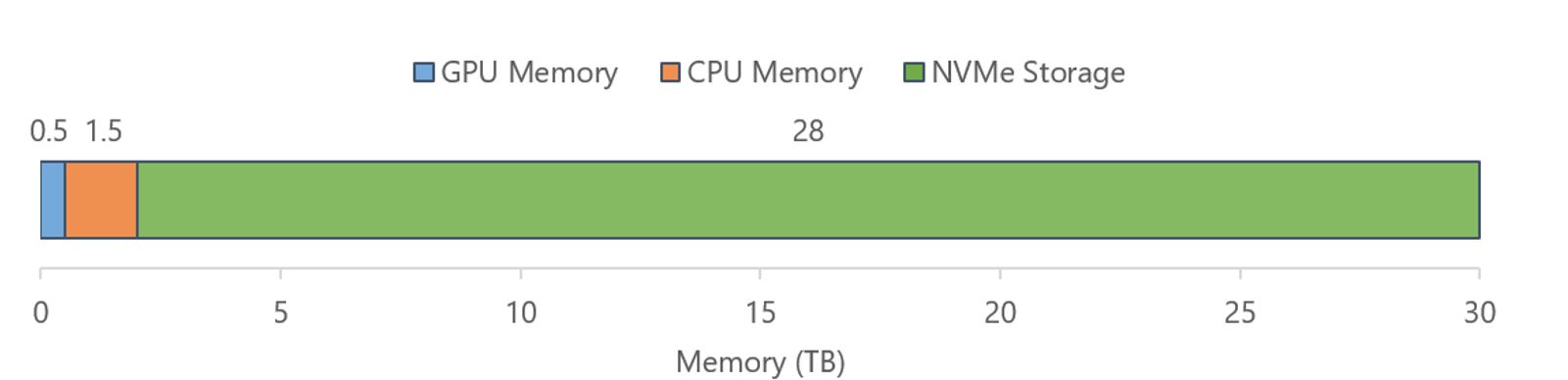
Infinity Offload Engine: State-of-the-art DL training systems, such as 3D parallelism, are bottlenecked by the aggregate GPU memory. However, modern GPU clusters have 2–3x more total CPU memory than total GPU memory, and a whopping 50x more total NVMe memory (see Figure 3 for details). Furthermore, the existing NVMe technology allows for over 25 GB/sec of achievable read/write speeds per DGX-2 node, comparable to PCIe 4.0 links. While this is nowhere close to the peak GPU memory bandwidth (1 TB/sec), we realized that we can fully exploit these memories to achieve extreme model scales, without being bottlenecked by their bandwidth, through careful design and optimizations.
The new Infinity Offload Engine is the brainchild of this realization. It is a novel data transfer library consisting of carefully crafted high-performance data movement kernels for training DL models. It can fully exploit both the CPU memory and the NVMe memory to offload the model states partitioned by ZeRO-3, allowing ZeRO-Infinity to create and train models at an unprecedented scale. ZeRO-Infinity can train a trillion-parameter model on a single GPU within a DGX-2 node (100x larger than the current start of the art), or it can train models with over 30 trillion parameters on 32 such nodes (50x larger than 3D parallelism on the same number of nodes). Refer back to Figure 1 for details.
3. Activation checkpointing with CPU offload allows for reducing activation memory footprint, which can become the memory bottleneck on the GPU after the memory required by the model states are addressed by ZeRO-3 and the Infinity Offload Engine.
Activation checkpointing with CPU offload: Models with over tens of billions of parameters require a significant amount of memory for storing activations; memory beyond what is available on a single GPU. To avoid running out of memory, we can use activation checkpointing, where instead of storing all activations, we only store them at specified intervals to save memory at the expense of activation re-computation in the backward pass. Activation checkpointing can reduce the activation memory footprint by orders of magnitude. However, for massive models, the memory requirement after activation checkpointing can still be too large to fit in GPU memory. To address this, we support activation checkpointing with CPU offload, allowing all the activation to reside in the CPU memory.
4. Memory-centric operator tiling, a novel computation rescheduling technique that works together with the ZeRO data access and communication schedule, allows for reducing the memory footprint of incredibly massive individual layers that can be too large to fit in GPU memory even one layer at a time.
Memory-centric operator tiling: Models with hundreds of billions to trillions of parameters require significant memory even for individual layers. As an example, a single intermediate layer in a Transformer model with a hidden dimension of 64K requires over 64 GB of memory to store the parameters and gradients in fp16. Computing the forward and backward passes on such a layer requires not only over 64 GB of working memory, but also at least two contiguous memory buffers of over 32 GB, one for parameters and another for the gradients. This is very difficult—even on NVIDIA A100 80 GB GPU cards—due to presence of memory fragmentation in general.
Model parallelism solves this issue by partitioning the individual layer across GPUs. Alternatively, it is possible to partition this layer in the same way as with model parallelism but execute these partitions in sequence on the same GPU. We call this approach memory-centric operator tiling. When combined with ZeRO-3, which can gather and remove parameters on demand, this tiling reduces the working memory proportional to the number of partitions, supporting arbitrarily large hidden sizes that would otherwise require model parallelism to fit even a single model layer.
Broader access to fine-tuning extremely large models: GPT-3 or even larger models on a single GPU
While pretraining is the first important step in creating a massive model, fine-tuning for specific tasks is essential to leveraging the full potential of the model for different scenarios. Making fine-tuning of massive models easily accessible to data scientists could allow the creation of many derived models to meet the need of various application scenarios. These tasks might range from grammar correction to writing assistance, from image captioning to code generation—any task possible with large AI models.
Unlike pretraining, which can require millions of GPU compute hours, fine-tuning a model with hundreds of billions of parameters is much cheaper, requiring significantly less GPU compute hours, and can be done on a single compute node with a handful of GPUs. While such compute resources are accessible to many businesses and users, they are unfortunately restricted by the memory available on these compute nodes, which in turn limits the size of the model that can be fine-tuned. It makes large model fine-tuning inaccessible to most businesses and companies that do not have access to massive GPU clusters.
ZeRO-Infinity completely changes this landscape by enabling data scientists with access to a single node, such as the NVIDIA DGX-2, to fine-tune models with over a trillion parameters (Figure 4). In fact, it can run models with over a trillion parameters even on a single GPU of such a node since it has enough CPU and NVMe memory. This is nearly 100x larger than state of the art for single GPU training. With ZeRO-Infinity, the memory bottleneck is no longer the GPU memory or even the CPU memory. Instead, we can now leverage them together with the much larger and cheaper NVMe memory.
Through ZeRO-Infinity, we take another step toward democratization of AI by enabling users and businesses with limited resources to leverage the power of massive models for their business-specific applications.

Microsoft research webinars
Train massive models without any code refactoring
Scaling models to hundreds of billions and trillions of parameters is challenging. Data parallelism cannot scale a model’s size much further beyond a billion parameters. Model parallelism with tensor slicing is challenging to efficiently scale beyond a single node due to communication overheads. Finally, pipeline parallelism cannot scale beyond the number of layers available in a model, which limits both the model size and the scale of GPUs.
The only existing parallel technology available that can scale to over a trillion parameters on massively parallel GPU clusters is 3D parallelism, which combines data, model, and pipeline parallelism in complex ways. While such a system can be very efficient, it requires data scientists to do major model code refactoring, splitting the model into load-balanced pipeline stages. This also makes 3D parallelism inflexible in the type of models that it can support since models with complex dependency graphs cannot be easily converted into a load-balanced pipeline.
ZeRO-Infinity addresses these challenges in two ways. First, with groundbreaking model scaling, ZeRO-Infinity is the only DL parallel technology that can efficiently scale to trillions of parameters without requiring a hybrid parallelism strategy, greatly simplifying the system stack for DL training. Second, ZeRO-Infinity requires virtually no model refactoring from data scientists, liberating data scientists to scale up complex models from hundreds of billions to hundreds of trillions of parameters, as the compute becomes available.
Excellent training efficiency and superlinear scalability
ZeRO-Infinity can offload model states and activations to NVMe and CPU, which have orders-of-magnitude slower communication bandwidth (10–25 GB/sec) than GPU memory bandwidth (about 900 GB/sec). Furthermore, it incurs 50 percent additional GPU-to-GPU communication overhead of ZeRO-3 compared to data-parallel training. Despite these limitations, ZeRO-Infinity can achieve excellent training efficiency that is comparable to state-of-the-art GPU-only solutions like 3D parallelism, and it is significantly better than standard data-parallel training with PyTorch.
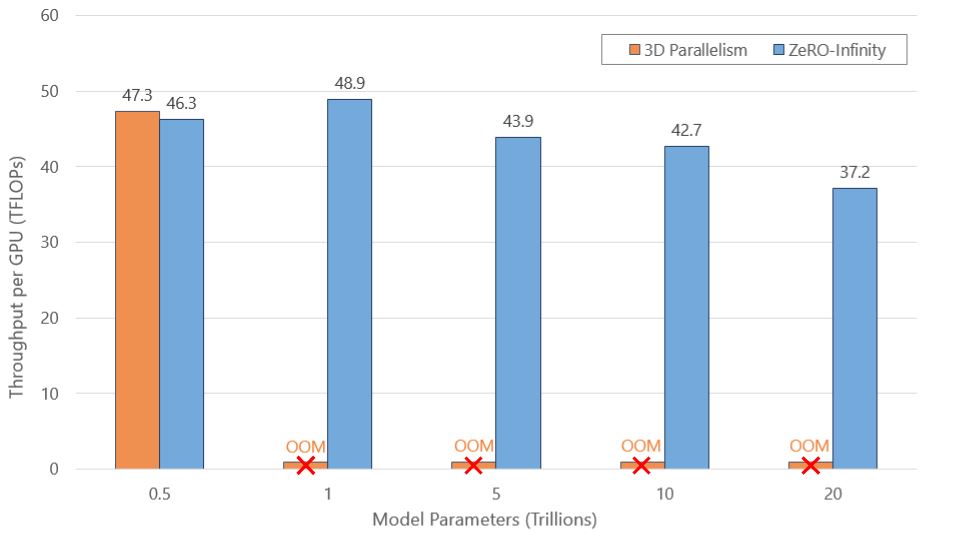
As a concrete example, ZeRO-Infinity achieves a sustained throughput of 37–50 teraflops/GPU for model sizes ranging from 400 billion parameters to 20 trillion parameters running on 512 NVIDIA V100 GPUs (see Figure 5). In comparison, 3D parallelism achieves very similar throughput (48 teraflops/GPU) for a 650-billion-parameter model, the largest model that can be trained on the same number of GPUs. Standard data-parallel training with PyTorch only achieves 30 teraflops per GPU for a 1.3 billion-parameter model, the largest model that can be trained using data parallelism alone.
There are three key innovations behind the excellent training efficiency of ZeRO-Infinity:
- Bandwidth-centric partitioning enables parallel memory access resulting in virtually unlimited heterogeneous memory bandwidth. With ZeRO-Infinity, the effective NVMe and CPU memory bandwidth grow linearly with the number of available devices. For instance, the NVMe bandwidth is about 25 GB/sec per DGX-2 node, but on a cluster with 64 such nodes, this increases to 1.6 TB/sec, even faster than the GPU HBM2 memory on the NVIDIA V100 GPU that can achieve 0.9 TB/sec.
Bandwidth-centric partitioning: In the original ZeRO, parameters for each layer are owned by a unique data-parallel process, requiring each rank to broadcast the parameters when needed. If these parameters are located in CPU memory, then they first must be copied to GPU before the broadcast operation. The copy bandwidth is therefore limited by a single PCIe link bandwidth. On the contrary, in ZeRO-Infinity, the parameters for each layer are partitioned across all data-parallel processes, and they use an all-gather operation instead of broadcast when needed. If parameters for each layer are located in GPU memory, this makes no difference—as both broadcast and all-gather have the same communication cost. But if they are located in CPU, this makes a significant difference as each data-parallel process only transfers its partition of the parameters to the GPU in parallel before all-gather is done. Therefore, ZeRO-Infinity can leverage the aggregate bandwidth across all PCIe links instead of being bottlenecked by a single PCIe link.
2. Communication-overlap-centric design and implementation allows ZeRO-Infinity to hide nearly all communication volume at a reasonable batch size. ZeRO-Infinity can effectively overlap NVMe read/write, CPU-GPU data transfers, GPU-GPU communication, and GPU computation all at once.
Overlap-centric design: With the option of offloading model states to CPU and NVMe, overlapping communication is challenging. Before partitioned parameters can be reconstructed on the GPU using all-gather, it must be first brought from NVMe to CPU and then from CPU to the GPU. Therefore, retrieving a parameter during training requires a three-step communication process which can severely limit training efficiency.
To hide the cost of this communication, ZeRO-Infinity implements a dynamic prefetcher that traces the forward and backward computation on the fly, constructing an internal map of the operator sequence for each iteration. During each iteration, the prefetcher tracks where it is in the operator sequence and can prefetch the parameter required by future operators. The prefetcher is aware of the three-step communication process, and therefore can overlap the NVMe-CPU transfer for parameters of one layer, with CPU-GPU transfer and GPU-GPU all-gather of parameters of other layers, effectively overlapping all three communication stages with compute.
3. DeepNVMe module, created by the DeepSpeed team, allows for asynchronously reading and writing tensors to NVMe storage at near-peak NVMe bandwidth in PyTorch.
DeepNVMe Module: NVMe is a storage interface that is designed to fully utilize the maximum I/O performance of modern Solid State Disk (SSD) devices. However, despite the popularity of SSDs, it remains difficult for most applications to enjoy the full benefits of SSDs due to the lack of user-level libraries that conveniently and efficiently provide NVMe functionality. An effective user-level NVMe module must address at least two key challenges: 1) provide a convenient interface to enable integration without major redesign of application logic and 2) furnish an efficient software that imposes negligible overhead on request processing. DeepNVMe was developed to fill this gap as a user-level library that enables applications to easily exploit the maximum SSD performance. DeepNVMe addresses the interface and performance challenges of user-level NVMe libraries as follows.
From an interface perspective, DeepNVMe allows applications to flexibly submit both blocking and non-blocking I/O requests (reads or writes), and it allows synchronization requests to flush pending read or write requests. This flexible interface enables easy integration of DeepNVMe into existing application logic rather than restructuring application to adapt to DeepNVMe.
From a performance perspective, DeepNVMe allows applications to leverage both intra-request parallelism (I/O request from one user thread) and inter-request parallelism (I/O requests from multiple user threads). DeepNVMe efficiently supports these different forms of request parallelism using a number of optimizations including low-overhead multi-threading, smart work scheduling, avoiding data copying, and memory pinning. ZeRO-Infinity uses DeepNVMe to copy tensors to and from the local SSD devices in order to make space in GPU and CPU memory for training multi-trillion parameter models. The benefit of DeepNVMe is clearly demonstrated by the ability to effectively support a massive, data-intensive, and performance-critical application like ZeRO-Infinity.
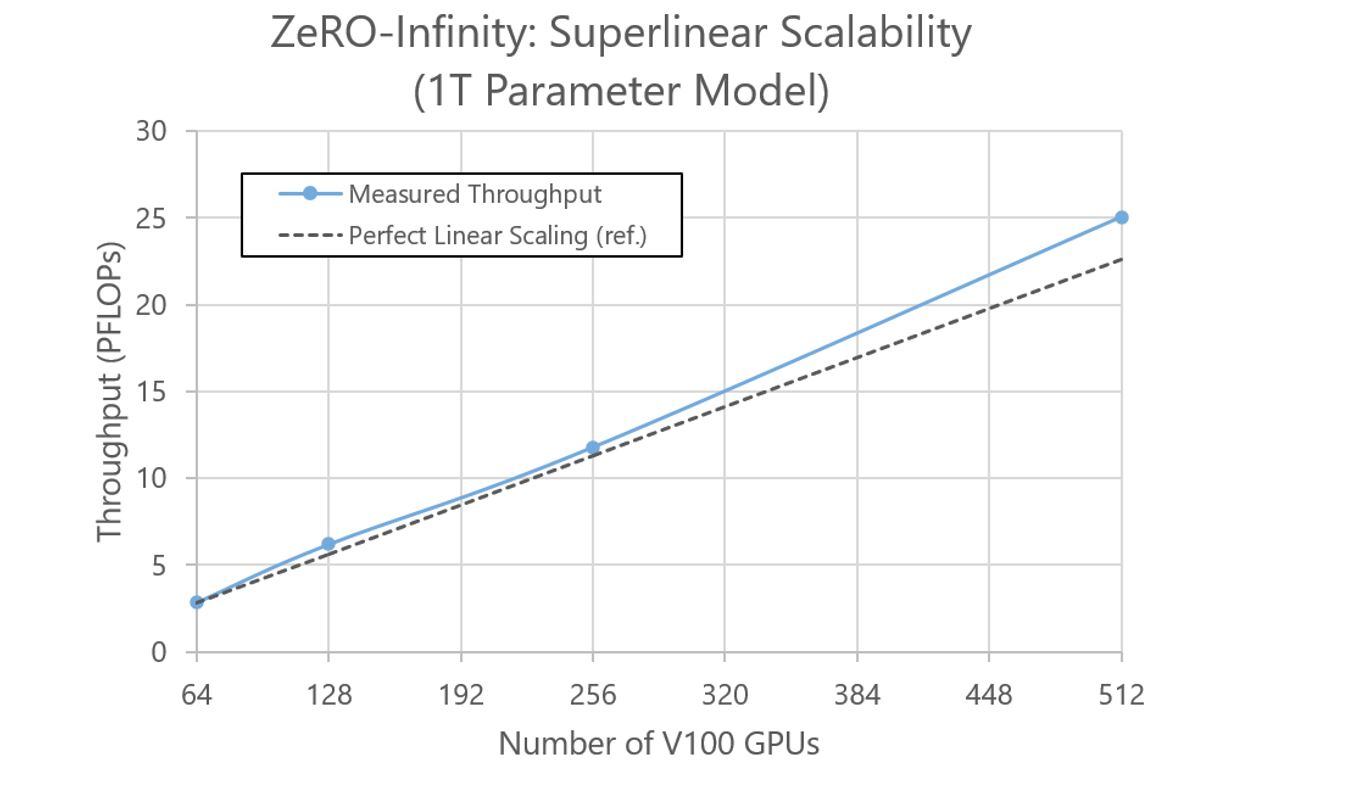
In addition to achieving high training efficiency, ZeRO-Infinity preserves superlinear scalability (see Figure 6) that we have demonstrated with all our previous ZeRO technologies (ZeRO-1, ZeRO-2, and ZeRO-Offload). This is possible because of the memory-and-compute access pattern of ZeRO-Infinity—it reduces the NVMe/CPU communication time as well as the optimizer update time linearly with the increasing number of GPUs and nodes, respectively.
ZeRO-Infinity redefines the large model training landscape
It was less than a year ago that 3D parallelism enabled training of a model at a scale of a trillion parameters with 800 NVIDIA V100 GPUs. Now, with ZeRO-Infinity, the same scale can be achieved on a single DGX-2 node (16 V100 GPUs) with virtually no model refactoring. Massive model training is no longer just a possibility for companies with access to massive supercomputers and heavy system expertise. Instead, it’s now easily accessible to many data scientists with access to only a single GPU or a few GPUs.
In addition, ZeRO-Infinity offers a paradigm shift in how we think about memory for large model training. It is no longer necessary to fit DL training on ultra-fast yet expensive memory with limited size, like HBM2. ZeRO-Infinity demonstrates that it is possible to transcend the GPU memory wall by leveraging cheap and slow, but massive, CPU or NVMe memory in parallel across multiple devices to achieve the aggregate bandwidth necessary for efficient training.
With memory no longer a limitation on model scale or efficiency, it is now critical that we focus on the innovations in compute performance and GPU-to-GPU bandwidth. While it is now possible to fit a 30 trillion parameter model for training on 512 NVIDIA V100 GPUs with ZeRO-Infinity, it is very challenging to complete the end-to-end pre-training in a reasonable time. This could demand 100x improvements in compute performance and the interconnect bandwidth between GPUs compared to what is available on current NVIDIA DGX V100 clusters. The state-of-the-art NVIDIA A100 GPUs and the DGX A100 nodes are good steps in that direction offering over 3x – 6x in compute performance and 2x improvement in interconnect bandwidth per GPU than the NVIDIA DGX V100 nodes. We welcome such improvements, and are excited that the NVIDIA A100 GPU will soon be available through Azure ND A100 v4 VMs.
Finally, we hope that with memory no longer a limitation, ZeRO-Infinity will further inspire an acceleration in compute and network bandwidth focused design of future ultra-powerful devices and supercomputing clusters necessary for the next 1000x growth in model scale and the quality improvements they will offer.
Please read our ZeRO-Infinity paper for more details and visit the DeepSpeed website and GitHub repository for the codes, tutorials, and documentations about these new technologies!
About DeepSpeed’s integration with Azure Machine Learning and open-source solutions
- Azure Machine Learning: DeepSpeed and Azure Machine Learning team have made it simple for users to train DeepSpeed-powered models on Azure Machine Learning. Specifically, the DeepSpeed curated environment makes it simple for users to get started with DeepSpeed on Azure. Example DeepSpeed models are actively being added to the official Azure Machine Learning-examples repo. Get started with our Open AI GPT-2 and cifar examples. Azure Machine Learning provides powerful GPU support to accelerate model development.
- Hugging Face: Hugging Face recently announced its integration with DeepSpeed, which allows users to easily accelerate their models through a simple “—deepspeed” flag and config file. Through this integration, DeepSpeed is able to bring 3x faster speedups in multi-GPU training compared with the original solution. DeepSpeed also allows fitting a significantly larger model for users who own just a single GPU (or a few GPUs) with much higher compute efficiency than alternatives.
- PyTorch lighting: We are happy to announce that PyTorch Lightning integrates DeepSpeed as a plugin for DL training optimizations: Accessing Multi-Billion Parameter Model Training with Pytorch Lightning + DeepSpeed. To enable DeepSpeed in Lightning 1.2, it is as simple as passing plugins=’deepspeed’ to the Lightning trainer (docs).
About the DeepSpeed Team:
We are a group of system researchers and engineers—Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, Shaden Smith, Elton Zheng, Reza Yazdani Aminabadi, Arash Ashari, Ammar Ahmad Awan, Cheng Li, Conglong Li, Niranjan Uma Naresh, Minjia Zhang, Jeffrey Zhu, Yuxiong He (team lead)—who are enthusiastic about performance optimization of large-scale systems. We have recently focused on deep learning systems, optimizing deep learning’s speed to train, speed to convergence, and speed to develop!
If this type of work interests you, the DeepSpeed team is hiring both researchers and engineers! Please visit our careers page.
The post ZeRO-Infinity and DeepSpeed: Unlocking unprecedented model scale for deep learning training appeared first on Microsoft Research.