
This post has been republished via RSS; it originally appeared at: Microsoft Research.
Today, we’re excited to announce the release of SynapseML (previously MMLSpark), an open-source library that simplifies the creation of massively scalable machine learning (ML) pipelines. Building production-ready distributed ML pipelines can be difficult, even for the most seasoned developer. Composing tools from different ecosystems often requires considerable “glue” code, and many frameworks aren’t designed with thousand-machine elastic clusters in mind. SynapseML resolves this challenge by unifying several existing ML frameworks and new Microsoft algorithms in a single, scalable API that’s usable across Python, R, Scala, and Java.
With SynapseML, developers can build scalable and intelligent systems for solving challenges in domains such as:
• Anomaly detection
• Computer vision
• Deep learning
• Form and face recognition
• Gradient boosting
• Microservice orchestration
• Model interpretability
• Reinforcement learning and personalization
• Search and retrieval
• Speech processing
• Text analytics
• Translation
Simplifying distributed ML through a unified API
Writing fault-tolerant distributed programs is complex and a process that’s prone to errors. For example, consider the distributed evaluation of a deep network. The first step is to send a multi-GB model to hundreds of worker machines without overwhelming the network. Then, data readers must coordinate to ensure that all data is queued for processing and that GPUs are at full capacity. If new computers join or leave the cluster, new worker machines must receive copies of the model, and data readers need to adapt to share work with the new machines and re-compute lost work. Finally, progress must be tracked to ensure resources are properly freed.
Sure, frameworks like Horovod can manage this, but if a teammate wants to compare against a different ML framework, such as LightGBM, XGBoost, or SparkML, it requires a new environment and cluster. Moreover, these training systems aren’t designed to serve or deploy models, so separate inference and streaming architectures are required.
SynapseML simplifies this experience by unifying many different ML learning frameworks with a single API that is scalable, data- and language-agnostic, and that works for batch, streaming, and serving applications. It’s designed to help developers focus on the high-level structure of their data and tasks, not the implementation details and idiosyncrasies of different ML ecosystems and databases.
A unified API standardizes many of today’s tools, frameworks, and algorithms, streamlining the distributed ML experience. This enables developers to quickly compose disparate ML frameworks for use cases that require more than one framework, such as web-supervised learning, search engine creation, and many others. It can also train and evaluate models on single-node, multi-node, and elastically resizable clusters of computers, so developers can scale up their work without wasting resources.
In addition to its availability in several different programming languages, the API abstracts over a wide variety of databases, file systems, and cloud data stores to simplify experiments no matter where data is located, as shown in Figure 1.
General availability, and enterprise support on Azure Synapse Analytics
Over the past five years, we have worked to improve and stabilize the SynapseML library for production workloads. Developers who use Azure Synapse Analytics will be pleased to learn that SynapseML is now generally available on this service with enterprise support. They can now build large-scale ML pipelines using Azure Cognitive Services, LightGBM, ONNX, and other selected SynapseML features. It even includes templates to quickly prototype distributed ML systems, such as visual search engines, predictive maintenance pipelines, document translation, and more. Please see this GA announcement guide for added details.
Getting started with state-of-the-art, pre-built intelligent models
Many tools in SynapseML don’t require a large labelled training dataset. Instead, SynapseML provides simple APIs for pre-built intelligent services, such as Azure Cognitive Services, to quickly solve large-scale AI challenges related to both business and research. SynapseML enables developers to embed over 45 different state-of-the-art ML services directly into their systems and databases. The latest release includes added support for distributed form recognition, conversation transcription, and translation, as illustrated in Figure 2. These ready-to-use algorithms can parse a wide variety of documents, transcribe multi-speaker conversations in real time, and translate text to over 100 different languages.

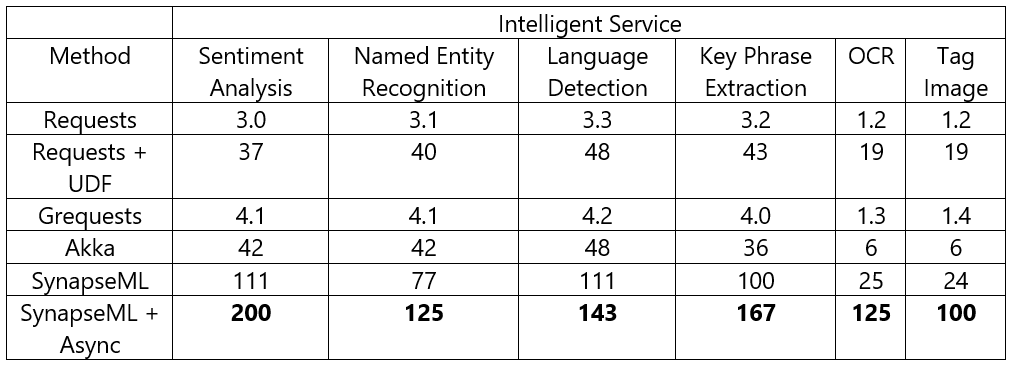
Working with web services at scale can be challenging due to networking issues, throttling, and large amounts of CPU downtime while the client waits on the server’s response. To make SynapseML’s integration with Azure Cognitive Services fast and efficient, we introduced several new tools into Apache Spark. In particular, SynapseML automatically parses common throttling responses to ensure that jobs don’t overwhelm backend services. Additionally, it uses exponential back-offs to handle unreliable network connections and failed responses. Finally, Spark’s worker machines stay busy with new asynchronous parallelism primitive to Spark. This allows worker machines to send requests while waiting on a response from the server, which can yield a tenfold increase in throughput. Table 1 shows how these features help SynapseML achieve significantly better throughputs than many baseline implementations. The paper Large-Scale Intelligent Microservices provides a deeper look at this system’s architecture.
Broad ecosystem compatibility with ONNX
For tasks that cannot be solved with existing cognitive services, SynapseML enables developers to use models from many different ML ecosystems through the Open Neural Network Exchange (ONNX) framework and runtime. With this integration, developers can execute a wide variety of classical and deep learning models at scale with only a few lines of code. This integration between ONNX and Spark automatically handles distributing ONNX models to worker nodes, batching and buffering input data for high throughput, and scheduling work on hardware accelerators, as shown in Figure 3.
Bringing ONNX to Spark not only helps developers scale deep learning models, it also enables distributed inference across a wide variety of ML ecosystems. In particular, ONNXMLTools converts models from TensorFlow, scikit-learn, Core ML, LightGBM, XGBoost, H2O, and PyTorch to ONNX for accelerated and distributed inference using SynapseML. Furthermore, we have contributed the ONNX Model Hub, making it easy to deploy over 120 state-of-the-art pre-trained models across domains, such as vision, object detection, face analysis, speech recognition, style transfer, and others.

Training your own reinforcement learners with Vowpal Wabbit
SynapseML enables developers not only to use existing models and services, but also to build and train their own. This release of SynapseML introduces new algorithms for personalized recommendation and contextual bandit reinforcement learning using the Vowpal Wabbit framework. This Vowpal Wabbit integration can distribute model training and prediction for a single model or parallelize training across multiple models. This is especially useful for quickly tuning hyper parameters of policy optimization and personalization systems. New users can get started with Vowpal Wabbit on this GitHub page.
Building responsible AI systems with SynapseML
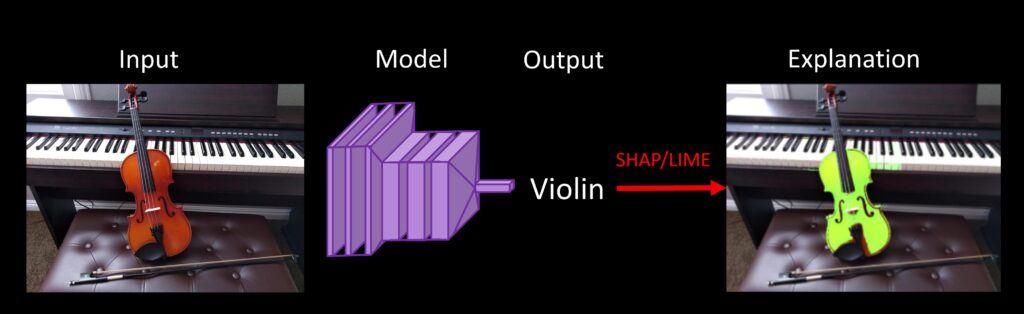
After building a model, it’s imperative that researchers and engineers understand its limitations and behavior before deployment. SynapseML helps developers and researchers build responsible AI systems by introducing new tools that reveal why models make certain predictions and how to improve the training dataset to eliminate biases. More specifically, SynapseML includes distributed implementations of Shapley Additive Explanations (SHAP) and Locally Interpretable Model-Agnostic Explanations (LIME) to explain the predictions of vision, text, and tabular models. For example, Figure 4 shows how to quickly interpret a trained visual classifier to understand why it made its predictions. Ordinarily, these opaque-box methods typically require thousands of model evaluations per explanation, and it can take days to explain every prediction over a large a dataset. SynapseML dramatically speeds the process of understanding a user’s trained model by enabling developers to distribute computation across hundreds of machines.
In addition to supervised model explainability, SynapseML also introduces several new capabilities for unsupervised responsible AI. With our new tools for understanding dataset imbalance, researchers can detect whether sensitive dataset features, such as race or gender, are over- or under-represented and take steps to improve model fairness. Furthermore, SynapseML’s distributed isolation forest enables researchers to detect outliers and anomalies in their datasets without needing labelled training data. Here at Microsoft, we are actively using these techniques to detect and prevent abuse on LinkedIn.
Finally, Azure Synapse Analytics users can take advantage of the private preview of a distributed implementation of Explainable Boosting Machines, which combines the modeling power of gradient-boosted trees with the interpretability of linear additive models. This allows data scientists to learn high-quality nonlinear models without sacrificing their ability to understand a model’s predictions.
Simplifying the path to production systems
We hope developers and others who build production-ready scalable ML systems find that SynapseML simplifies the process. SynapseML standardizes a variety of ML frameworks, such as those mentioned in this blog post, to enable new classes of ML systems that compose pieces from different ML ecosystems. Our goal is to free developers from the hassle of worrying about the distributed implementation details and enable them to deploy them into a variety of databases, clusters, and languages without needing to change their code. Moreover, with our announcement of the general availability of SynapseML on Azure Synapse Analytics, developers can depend on enterprise support for their production systems.
Learn more
Large-Scale Intelligent Microservices
Using SynapseML in Azure Synapse Analytics
Acknowledgements
Many fantastic contributors are actively developing SynapseML. Special thanks to Serena Ruan, Jason Wang, Ilya Matiach, Wenqing Xu, Tom Finley, Markus Weimer, Nellie Gustafsson, Jeff Zheng, Kashyap Patel, Ruixin Xu, Martha Laguna, Tomas Talius, Jack Gerrits, Markus Cozowicz, Sudarshan Raghunathan, Anand Raman, the Synapse Team, the Azure Cognitive Services Team, and everyone who contributed to MMLSpark and SynapseML.
The post SynapseML: A simple, multilingual, and massively parallel machine learning library appeared first on Microsoft Research.