
This post has been republished via RSS; it originally appeared at: Microsoft Research.
Recent progress in natural language understanding (NLU) has been driven in part by the availability of large-scale benchmarks that provide an environment for researchers to test and measure the performance of AI models. Most of these benchmarks are designed for academic settings–typically datasets that feature independent and identically distributed (IID) training, validation, and testing sections drawn from data that have been collected or annotated by crowdsourcing.
However, increasing evidence shows that AI models that achieve human-level performance on academic benchmarks may underperform in real-world settings where a) task-specific labels are unavailable for model training and b) the dataset contains various adversarial examples. Ironically, models that reached human-level performance in academic settings highlight the limitation of these benchmarks in reliably evaluating the two capabilities of AI models that, we believe, are crucial for real-world applications:
- Learning efficiency: Most existing benchmarks give models access to large amounts of labeled data for training–far more data than people need to achieve strong performance. Such large amounts of human-labeled data are rarely available for most real-world applications.
- Robustness: State-of-the-art models remain vulnerable to carefully crafted adversarial examples, which can fool the models into outputting arbitrarily wrong answers by altering input sentences in a way that is unnoticeable to humans. Real-world systems built upon these vulnerable models can be misled in ways that could have profound security concerns.
To address these limitations, Microsoft Research is releasing two new NLU benchmarks, including one created in collaboration with the University of Illinois at Urbana-Champaign, to simulate real-world settings where AI models must adapt to new tasks with few task labels and are robust to changes or adversarial attacks.
CLUES: Evaluating few-shot learning in NLU
Despite increasing interest in data-efficient, few-shot learning with language models, no standardized evaluation benchmark exists for few-shot natural language understanding (NLU). As a result, different research studies yield different experimental settings.
To help accelerate work on few-shot learning for NLU, Microsoft researchers have created CLUES, a benchmark for evaluating the few-shot learning capabilities of NLU models.
CLUES was designed with the following principles in mind:
- Task Selection: tasks should provide high coverage and diversity across NLU task types and must show a significant gap between human and machine performance
- Task Formulation: should follow a consistent format to unify different types of tasks and model families to encourage broad usage and adoption
- Evaluation: measuring true few-shot learning capabilities requires unified metrics to compare and aggregate model performance across diverse tasks and evaluation settings

In a research paper, “CLUES: Few-Shot Learning Evaluation in Natural Language Understanding”, we show that while recent models reach human performance when they have access to large amounts of task-specific labeled data, a huge gap in performance exist in the few-shot setting for many NLU tasks. In this paper, which has been accepted at the 2021 Conference on Neural Information Processing Systems (NeurIPS2021), we also show differences between alternative model families and adaptation techniques in the few-shot setting. Finally, we discuss several principles and choices in designing the experimental settings for evaluating the true few-shot learning performance and suggest a unified standardized approach to few-shot learning evaluation.
The paper also presents other interesting findings, as summarized below:
Evaluation settings: We observe a wide variance in the few-shot performance with classic fine-tuning that is exacerbated by the model size, and considerable variance with prompt-based fine-tuning. As a result, we provide, and recommend using, multiple splits of few-shot training examples and reporting the mean and variance on a single test set to measure the robustness and generalizability of different models.
Human performance: We conduct extensive human annotation studies on all tasks to assess human performance in the limited labeled data settings. We observe that people can achieve very good performance on all tasks, even when shown only a small number of examples. For some tasks, humans do equally well when shown a short description of the task, even with no labeled examples at all.
Model vs. human performance: In the fully supervised setting, models can match or exceed human performance for many tasks. However, in the few-shot setting, humans outperform the best models with a huge performance gap. This gap is even more pronounced for more complex tasks like named entity recognition and machine reading comprehension, where people perform very well with only a few demonstrative examples, whereas all models perform close to random.
Model capacity: In the fully supervised setting with adequate training data, the performance of different models generally improves with increasing model size. However, for the few-shot setting, we do not observe any consistent trend or impact of the model size on the performance with classic fine-tuning for most tasks. Yet for prompt tuning, bigger models tend to perform better.
We hope that CLUES encourages research on NLU models that can generalize to new tasks with a small number of examples. More details are available at https://aka.ms/clues-benchmark and in the upcoming NeurIPS 2021 paper.
AdvGLUE: Evaluating the Robustness of language models
Despite the tremendous success of large-scale pre-trained language models across a wide range of NLU tasks, recent studies reveal that the robustness of these models can be challenged by carefully crafted textual adversarial examples. While several individual datasets have been proposed to evaluate model robustness, a principled and comprehensive benchmark is still missing.
To quantitatively and thoroughly explore and evaluate the vulnerabilities of modern large-scale language models under various types of adversarial attacks, researchers from Microsoft and the University of Illinois at Urbana-Champaign have created Adversarial GLUE (AdvGLUE), a new multi-task benchmark. This work is detailed in the paper, “Adversarial GLUE: A Multi-Task Benchmark for Robustness Evaluation of Language Models,” which has been accepted for publication at NeurIPS 2021.
AdvGLUE systematically applies 14 textual adversarial attack methods to GLUE tasks. We then perform extensive filtering processes, including validation by humans, to exclude erroneous or poor-quality examples. This helps produce the reliable annotations necessary to curate a high-quality benchmark. Most existing automated adversarial attack algorithms are prone to generating invalid or ambiguous adversarial examples. Around 90% of them either change the original semantic meanings or mislead both human annotators and models.
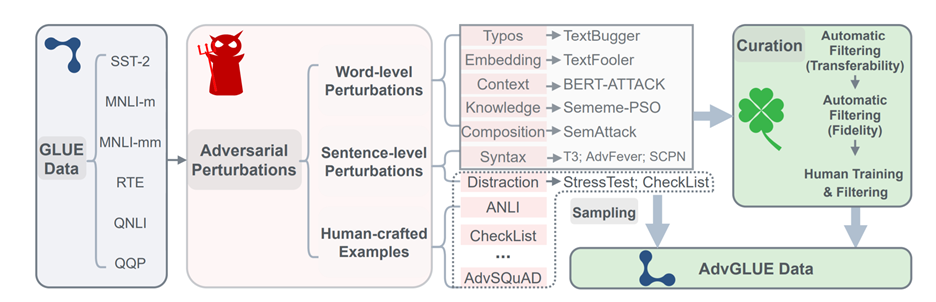
AdvGLUE is designed to create a unique and valuable asset to the community for improving the robustness of language models, with the following objectives in mind:
- Comprehensive coverage: We consider textual adversarial attacks from different perspectives and hierarchies, including word-level transformations, sentence-level manipulations, and human-written adversarial examples. As a result, we believe AdvGLUE provides substantial coverage of adversarial linguistic phenomena.
- Systematic human annotations: Systematic evaluation and annotation over the generated textual adversarial examples can be accomplished through crowdsourcing to identify high-quality adversarial data for reliable evaluation.
- General compatibility: To obtain comprehensive understanding of the robustness of language models across different NLU tasks, AdvGLUE covers the widely-used GLUE tasks and creates an adversarial version of the GLUE benchmark to evaluate the robustness of language models.
- High transferability and effectiveness: AdvGLUE has high adversarial transferability and can effectively attack a wide range of state-of-the-art models. We observe a significant performance drop for models evaluated on AdvGLUE compared with their standard accuracy on the GLUE leaderboard. For instance, the average GLUE score of ELECTRA (Large) drops from 93.16 to 41.69.
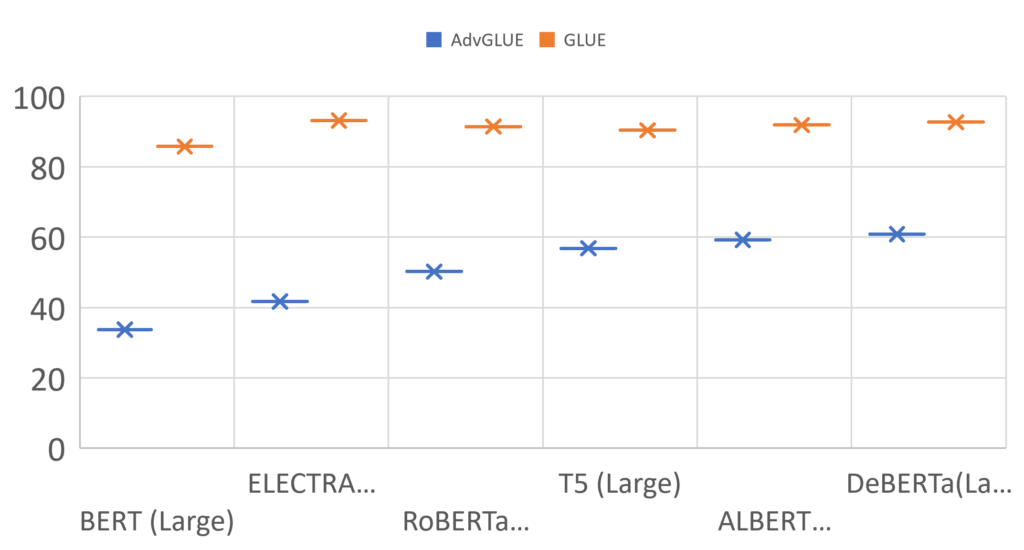
We hope that AdvGLUE will inspire active research and discussion in the community. More details are available at https://adversarialglue.github.io and in the upcoming NeurIPS 2021 paper.
Acknowledgements
The first paper in this post was a collaboration across Microsoft researchers, Subhabrata Mukherjee, Xiaodong Liu, Guoqing Zheng, Saghar Hosseini, Hao Cheng, Greg Yang, Chris Meek, Ahmed Awadallah and Jianfeng Gao.
The second paper in this post was collaboration across Microsoft researchers Shuohang Wang, Zhe Gan, Yu Cheng, Jianfeng Gao and Ahmed H. Awadallah as well as researchers from the University of Illinois at Urbana-Champaign, Boxin Wang, Chejian Xu and Bo Li.
The post You get what you measure: New NLU benchmarks for few-shot learning and robustness evaluation appeared first on Microsoft Research.