
This post has been republished via RSS; it originally appeared at: New blog articles in Microsoft Community Hub.
When I introduce app developers to the concept of RAG (Retrieval Augmented Generation), I often present a diagram like this:
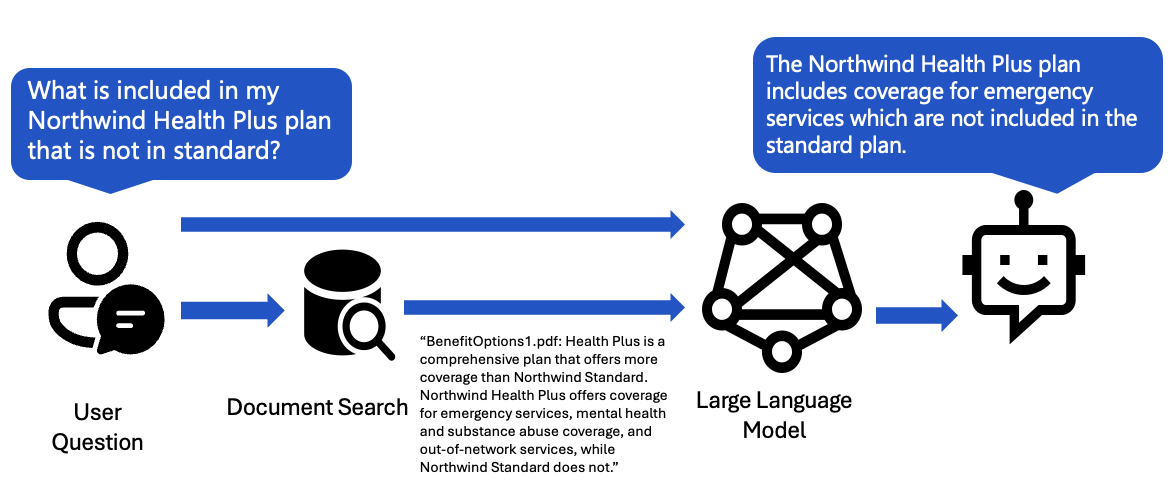
The app receives a user question, uses the user question to search a knowledge base, then sends the question and matching bits of information to the LLM, instructing the LLM to adhere to the sources.
That's the most straightforward RAG approach, but as it turns out, it's not what quite what we do in our most popular open-source RAG solution, azure-search-openai-demo.
The flow instead looks like this:

After the app receives a user question, it makes an initial call to an LLM to turn that user question into a more appropriate search query for Azure AI search. More generally, you can think of this step as turning the user query into a datastore-aware query. This additional step tends to improve the search results, and is a (relatively) quick task for an LLM. It also cheap in terms of output token usage.
I'll break down the particular approach our solution uses for this step, but I encourage you to think more generally about how you might make your user queries more datastore-aware for whatever datastore you may be using in your RAG chat apps.
Converting user questions for Azure AI search
Here is our system prompt:
Notice that it describes the kind of data source, indicates that the conversation history should be considered, and describes a lot of things that the LLM should not do.
We also provide a few examples (also known as "few-shot prompting"):
Developers use our RAG solution for many domains, so we encourage them to customize few-shots like this to improve results for their domain.
We then combine the system prompts, few shots, and user question with as much conversation history as we can fit inside the context window.
We send all of that off to GPT-3.5 in a chat completion request, specifying a temperature of 0 to reduce creativity and a max tokens of 100 to avoid overly long queries:
Once the search query comes back, we use that to search Azure AI search, doing a hybrid search using both the text version of the query and the embedding of the query, in order to optimize the relevance of the results.
Using chat completion tools to request the query conversion
What I just described is actually the approach we used months ago. Once the OpenAI chat completion API added support for tools (also known as "function calling"), we decided to use that feature in order to further increase the reliability of the query conversion result.
We define our tool, a single function search_sources that takes a search_query parameter:
Then, when we make the call (using the same messages as described earlier), we also tell the OpenAI model that it can use that tool:
Now the response that comes back may contain a function_call with a name of search_sources and an argument called search_query. We parse back the response to look for that call, and extract the value of the query parameter if so. If not provided, then we fallback to assuming the converted query is in the usual content field. That extraction looks like:
This is admittedly a lot of work, but we have seen much improved results in result relevance since making the change. It's also very helpful to have an initial step that uses tools, since that's a place where we could also bring in other tools, such as escalating the conversation to a human operator or retrieving data from other data sources.
To see the full code, check out chatreadretrieveread.py.
When to use query cleaning
We currently only use this technique for the multi-turn "Chat" tab, where it can be particularly helpful if the user is referencing terms from earlier in the chat. For example, consider the conversation below where the user's first question specified the full name of the plan, and the follow-up question used a nickname - the cleanup process brings back the full term.

We do not use this for our single-turn "Ask" tab. It could still be useful, particularly for other datastores that benefit from additional formatting, but we opted to use the simpler RAG flow for that approach.
Depending on your app and datastore, your answer quality may benefit from this approach. Try it out, do some evaluations, and discover for yourself!