
This post has been republished via RSS; it originally appeared at: Microsoft Research.
This research paper was presented at the 17th ACM International Conference on Web Search and Data Mining (opens in new tab) (WSDM 2024), the premier conference on web-inspired research on search and data mining.

In today’s data-driven landscape, tables are indispensable for organizing and presenting information, particularly text. They streamline repetitive content, enhance data manageability, enable easier data analysis, and improve machine processing capabilities. Meanwhile, large language models (LLMs) are advancing in their ability to tackle challenges associated with natural language, but the degree to which they understand tables included in their prompts remains an open question. Our research aims to explore this question and improve how LLMs use and work with table-based data.
Our paper, “Table Meets LLM: Can Large Language Models Understand Structured Table Data? A Benchmark and Empirical Study (opens in new tab),” presented at WSDM 2024 (opens in new tab), investigates what kinds of prompts most effectively enable LLMs to understand tables; how much LLMs inherently detect structured data; and how LLMs’ existing knowledge can be harnessed to improve this understanding. We also analyze the complex trade-off among multiple combinations of input designs and overall performance.
To address these questions, we propose a new benchmark called Structural Understanding Capabilities (SUC), shown in Figure 1 (a), which focuses on specific tasks to assess LLMs’ ability to understand structured data in tables and compare different types of prompts. We conducted a series of experiments using different prompt designs. Our findings, detailed in the paper, evaluate how each design enhances LLMs’ ability to work with tables.

Insights and findings using the SUC benchmark
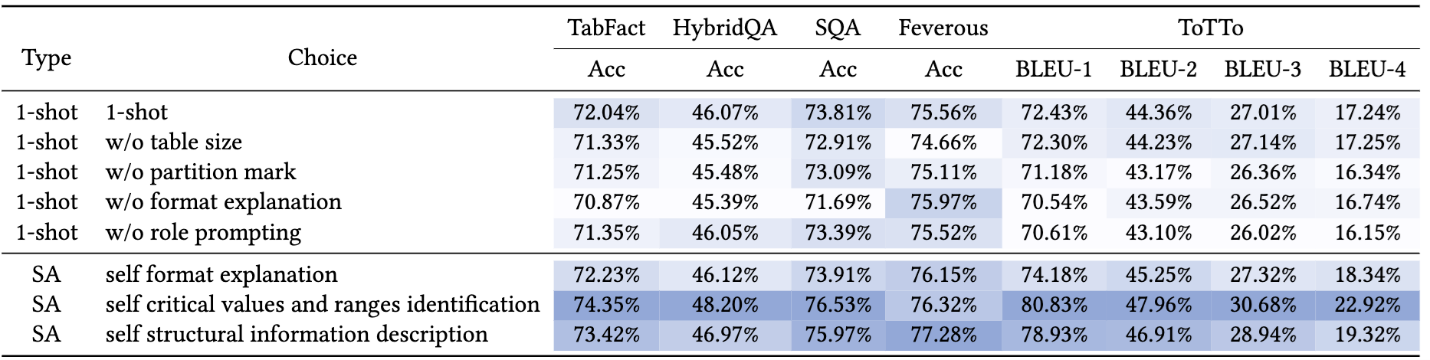
Based on humans’ perception of tables, we developed tasks to evaluate how LLMs understand them. We conducted evaluations on GPT-3.5 and GPT-4 and discovered that the results depended on certain input factors, such as table format, content order, and partition marks. The findings, detailed in Tables 1 and 2, reveal some notable and unexpected findings:
- Delimiter-separated formats (e.g., CSV, TSV), underperformed compared with HTML by 6.76 percent.
- Using HTML and few-shot learning consistently improved performance. The effectiveness of other approaches, such as format explanation, role prompting, order change, and partition marks, varied depending on task difficulty and the required capacity.
- Despite the simplicity of the benchmark tasks, the highest overall accuracy across seven tasks is only 65.43 percent. This underscores the need for LLMs to have better awareness of table structures and highlights areas for further improvement in table serialization.
Our exploration suggests that:
- LLMs have a basic understanding of table structures but are far from perfect, even in straightforward tasks like detecting the number of columns and rows.
- Choosing the right combination of input designs can significantly enhance LLMs’ understanding of structured data.
Our findings revealed significant performance gaps in downstream tasks, attributed to the different combinations of serialization functions and input options. These gaps remained even with GPT-4, underscoring the effectiveness of our benchmark approach.


Improved performance with self-augmented prompting
Based on these benchmark evaluations, we investigated how LLMs’ existing knowledge could be used to enhance their understanding of structured data. To do this, we introduced self-augmentation, a model-agnostic technique that improves structural prompting—enabling LLMs to identify key values and ranges by tapping into their own internal knowledge. This technique simplifies and optimizes how LLMs utilize their existing knowledge base to improve their understanding of structured content, allowing them to generate intermediate structural insights. This process is shown in Figure 2, with the results detailed in Table 3.
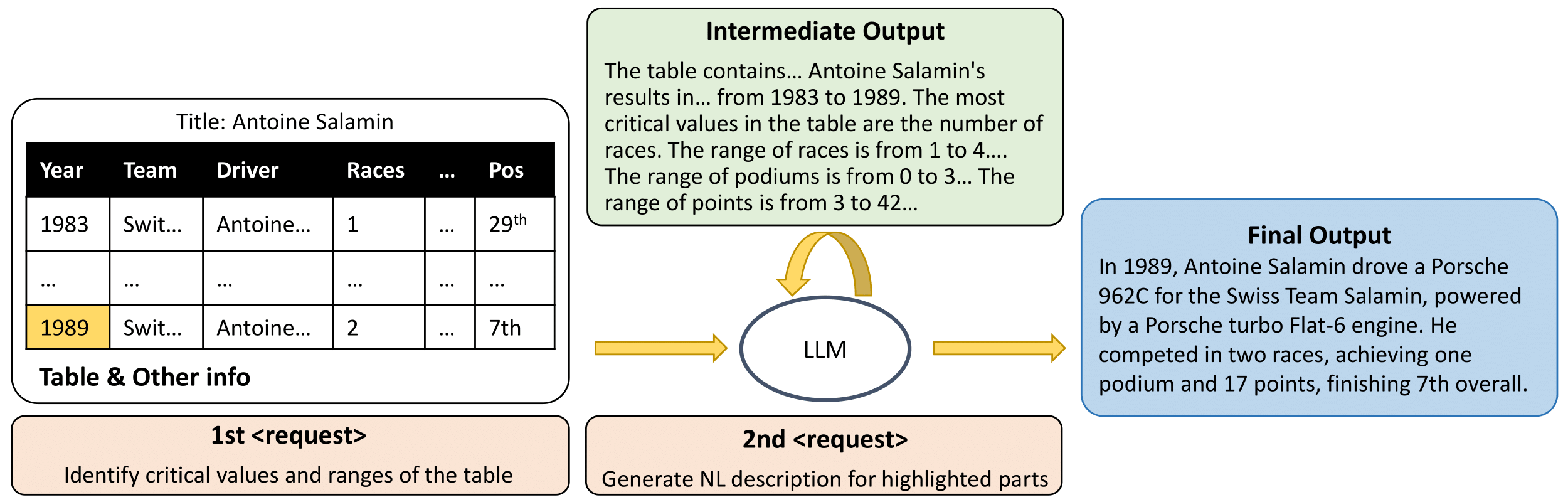
Looking forward
Our study sets a key benchmark in expanding the capabilities of LLMs to better understand structured table data, moving beyond conventional natural language processing tasks. We suggest future research should prioritize the integration of structural information to improve performance with various structured data types. Additionally, we propose exploring LLMs’ ability to use external tools or agents for improved handling of structured data, opening new avenues for application.
The post Improving LLM understanding of structured data and exploring advanced prompting methods appeared first on Microsoft Research.