
First published on MSDN on Sep 19, 2017
Authored by Rangarajan Srirangam
Authors: Rangarajan Srirangam, Mandar Inamdar, John Hoang
Reviewers: Murshed Zaman, Sanjay Mishra, Dimitri Furman, Mike Weiner, Kun Cheng
Overview
You might have worked with enterprise data pipelines using the SQL Server suite of products on-premises, or using virtual machines in the cloud. Now, you can build a similar enterprise data pipeline on Azure, comprised purely of Platform as a Service (PaaS) services. This article discusses data pipelines composed using Azure PaaS services, the main benefits, hybrid pipelines and some best practices.
Traditional Enterprise Data Pipeline
Enterprise data pipelines based on the SQL Server suite of products have been traditionally used on-premises to meet organizational needs of transaction processing, data analytics and reporting. SQL Server Database Engine is a favorite choice to host online transactional databases serving high volume transactions. With data marts hosted in SQL Server Analysis Services, Online Analytical Processing (OLAP), cubes can be built for analytical needs. With the addition of capabilities such as
ColumnStore
, using SQL Server Database Engine to host Data marts is another viable alternative. With
SQL Server APS
(formerly PDW), the scale and performance benefits inherent in a massively parallel processing (MPP) architecture can be realized. Reports with rich and powerful visualizations can be built using
SQL Server Reporting Services
.
SQL Server Integration Services
can be used to implement data transformation and/or data movement pipelines across the SQL Server product suite and can connect to external data sources and sinks. SQL Server Agent is a popular choice to schedule automated jobs for data maintenance and movement. Windows Server Active Directory provides a uniform identity management and single sign on solution. The SQL Server product suite (except for SQL Server APS which is an appliance) can be hosted on physical or virtual machines in an on-premises datacenter, or on virtual machines in the public cloud. This style of enterprise data warehouse (EDW) construction is depicted in figure 1 below
Figure 1:

While the above continues to be a perfectly valid style of deployment on-premises or in the Azure Cloud, there is now an alternate, modern way to construct the same architectural pipeline using Azure PaaS Services.
Enterprise Data Pipeline on Azure PaaS
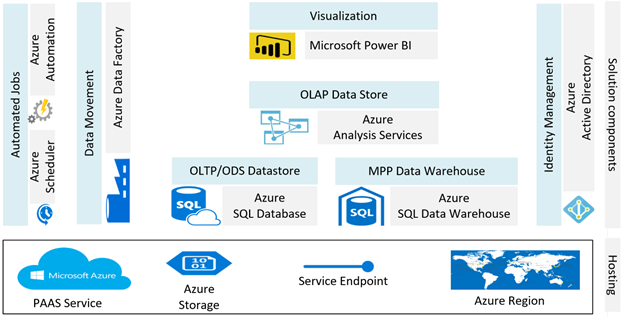
Azure SQL Database
which supports most of the Transact-SQL features available in SQL Server is your first choice OLTP RDBMS in Azure.
Azure SQL Data Warehouse
provides a cloud-based MPP data platform similar to SQL Server APS.
Azure Analysis services
, which is compatible with SQL Server Analysis Services, enables enterprise-grade data modeling in the cloud.
Power BI
is a suite of business analytics tools to deliver insights by connecting to a variety of data sources, enabling ad hoc analysis, creating rich visualizations, and publishing reports for web/mobile consumption.
Azure Automation
provides a way for users to automate and schedule tasks on the cloud. Using
Azure Scheduler
, you can run your jobs on simple or complex recurring schedules.
Azure Data Factory
is a cloud-based data integration service that orchestrates and automates the movement and transformation of data.
Azure Active Directory
is a multi-tenant cloud based directory and identity management service integrated with Azure PaaS Services. The services mentioned above are
made available in Azure regions
as autonomous Microsoft managed PaaS services and are accessed through named service end points. This style of enterprise EDW construction on Cloud using PaaS services is depicted in figure 2 below. Note that this is not the only one way of composing PaaS services and is intended to illustrate a like-for-like replacement for equivalents in a traditional pipeline. With a large number of varied cloud services in Azure, many other possibilities open up – for example, your cloud Analytics pipeline could leverage
Azure Data Lake Storage
or
Azure HD Insight
depending on the requirement
Figure 2:
Benefits
Let us look at a few benefits you can get by constructing an enterprise data pipeline on Azure PaaS.
Rapid provisioning
: Instances of PaaS services can be created quickly – typically seconds or minutes. For example, an Azure Analysis Services instance can be created and deployed usually within seconds.
Ease of Scale up/down:
The services can be scaled up or scaled down easily. For example, databases in an
Azure SQL Database Elastic Pool
can automatically scale up from a few to thousands to meet demand. Azure SQL Database can scale up and down through changes to service tier and performance level or scale-out via elastic scale and elastic pool.
Global Availability
: Each service is made available in multiple Azure regional datacenters across the world, so you can choose a region close to your user base. Check the
Azure Regions
page to find out more.
Cost Management
: PaaS Services are costed on a pay-as-you go model, rather than a fixed cost model. You can terminate (or in some cases also pause) services once they are no-longer needed. For example, Azure SQL Data Warehouse is costed based on the provisioned
Data Warehouse Units
, which can be scaled up or down depending on your demand.
Hardware/Software update and patch management
: The updating and patching of the hardware and software constituents of PaaS services is done by Microsoft, removing this concern from you.
Integration
: The PaaS services provide mechanisms to integrate with each other, as applicable, and with other non-Azure services. Power BI, for example, can connect directly to
Azure Analysis Services
,
Azure SQL Database
, and
Azure Data Warehouse
. Azure Data Factory supports a
variety of data sources
including
Amazon Redshift
,
DB2
,
MySQL
,
Oracle
,
PostgreSQL
,
SAP HANA
,
Sybase
and
Teradata
.
Security and Compliance:
Security features and compliance certifications continue to be added to each PaaS service. Azure SQL Database, for example, supports
multiple security features
such as authentication, authorization, row-level security, data masking, and auditing. The SQL Threat Detection feature
in Azure SQL Database
and
in Azure SQL Data Warehouse
helps detect potential security threats. Data movement with Azure Data Factory has been
certified for HIPAA/HITECH, ISO/IEC 27001, ISO/IEC 27018 and CSA STAR
.
Common Tools
: There are common tools that can be used with most services. For example, the
Azure Portal
can be used for creating, deleting, modifying and monitoring resources. Most services also support deployment and management through
Azure Resource Manager
. Familiar tools like
SQL Server Management Studio
, DMVs etc., continue work with Azure SQL Database, Azure SQL Data Warehouse and Azure Analysis Services. Azure Data Factory is a common mechanism to move data between services. There is a
common place
to view the health of these and other Azure services.
High Availability & Disaster Recovery:
Specific services offer built-in High Availability and Disaster Recovery options. For example, Azure SQL Database
Active geo-replication
enables you to configure readable secondary databases in the same or different data center locations (regions). Azure SQL Data Warehouse offers
backups
that can be locally and geographically redundant, while blob snapshots provide a way to restore a SQL Server database to a point in time.
SLAs
: Each service provides an SLA. This SLA is specific to each service. For example, Azure Automation provides an
SLA
for the maximum time for a runbook job to start, and for the availability of the Azure Automation DSC agent.
Which style wins – Physical Server/VM based or PaaS service based?
Your requirements and goals determine what style is most applicable to you. Box products as well as Azure PaaS services continue to improve and interoperate, expanding your possibilities rather than narrowing them down. For example, in SQL Server the
Managed Backup to Microsoft Azure
manages and automates SQL Server backups to Microsoft Azure Blob storage. As another example, Azure Analysis Services provides
data connections
to both cloud data sources and on-premises data sources. These and many more mechanisms allow you to think of one style as complementing or supplementing another, letting you build hybrid architectures if needed.
Hybrid data pipeline Architectures
You can have hybrid architectures with a combination of PaaS and IaaS services in the same solution. Customers are already implementing such architectures today. For example, SQL Server can be deployed in Azure Virtual Machines working seamlessly with Azure SQL Data Warehouse or Azure Analysis Services. Data may reside in multiple SQL Servers on virtual machines representing application databases. Data from these databases relevant to DW could be consolidated into a data warehouse on Azure SQL Data Warehouse. Conversely Azure SQL Data Warehouse could act a Hub for warehouse data and feed multiple SQL Servers/SQL Server Analysis Services/Azure Analysis Services systems as spokes for analysis / ad hoc / reporting needs. Again, for ETL and data movement orchestration you can use SQL Server Integration Services as an alternative to ADF, or for better performance you can use
PolyBase
to load the data. Hybrid architectures allow a staged migration of on-premises solutions to Azure, and enable a part of the deployment to be on-premises during the transition. For example, customers who have traditional warehouses on premises and are in the process of migrating to cloud can choose to keep some of the data sources on premises. ETL processes can move data over a
Site to Site VPN
(S2S VPN) or
Express Route
connection between Azure and the on-premises data center.
Customer implementations in the real world
Let’s explore two different real-world Enterprise data pipelines built by customers
Cloud PaaS Centered Architecture

The first example, depicted above, caters to the back-end analytical needs of an Azure customer who decided to adopt a PaaS based solution architecture after considering the ease of provisioning and elastic scale abilities. There is an on-premise Data warehouse implemented in Hive that holds current and historical data. Data relevant to analytics is copied from the on-premise data warehouse to Azure blob storage using Azure Blob Storage REST APIs over HTTPS.
This data (consisting of sale transactions, financial data, web user clickstreams, master data and prior historical data) is loaded into Azure SQL Data Warehouse using Polybase every night. In-memory tabular data models are then built in Azure Analysis Services over aggregates extracted from Azure SQL Data Warehouse (every night post data loading) with incremental processing of Tabular data model. These compute and memory intensive aggregates are executed on Azure SQL Data Warehouse for efficiency while Azure Analysis Services stores these aggregates and supports a much larger user/connection concurrency than allowed by Azure SQL Data Warehouse. The data models could be hosted in Azure Analysis Services or on Power BI. The customer chose to host on Azure Analysis Services considering the size of data to be stored in memory.
Power BI is used to build visually appealing dashboards for Sales Performance, Click Stream Analysis, Web-site Traffic Patterns etc. A few hundred organization users access the Power BI dashboards. Power BI users and the Service Accounts to administer Azure Services are provisioned in Azure Active Directory.
Automated scheduled jobs needed for Azure SQL Data Warehouse and Azure Analysis Services (data loading, index maintenance, statistics update, scheduled cube processing, etc.) are executed using runbooks hosted in Azure Automation. A Disaster Recovery (DR) setup in a secondary Azure region can be easily implemented by periodically copying backups of Azure Analysis Services data and by enabling geo-redundant backups in Azure SQL Data Warehouse.
Hybrid IaaS – PaaS Architecture

The second example depicted above caters to the backend analytical needs of a customer in the financial sector. The solution is a hybrid in using IaaS and PaaS services on Azure. The on-premise deployment continues to host the multiple data sources including SQL Server 2016, Oracle, flat files etc., for legacy application compatibility reasons though there is thinking on migrating these sources eventually to cloud. These data sources store customer, financial, CRM, user clickstream and credit bureau data.
A few GBs of data need to be transferred every night and around 50 GB data over the weekend from on-premise to Azure. The customer has connected the on-premise data center to Azure via Azure Express Route given the data volumes involved and a need for SLAs on network availability. Data is moved from on-premise data sources into flat files using Windows Scheduled Jobs. This data is copied onto a local file server and compressed using algorithms like gzip on-premise. Compressed files are copied onto Azure Storage over HTTPS using the
AzCopy
tool.
The data loading workflow from Azure Blob Storage to Azure SQL Data Warehouse is orchestrated by SQL Server Integration services (SSIS) hosted in an Azure Virtual Machine. This allows the customer to reuse existing SSIS packages developed for SQL Server and available skill sets in the technical team on SSIS. The customer is also considering migrating these jobs to Azure Data Factory in the future. The data load jobs are scheduled using SQL Server Agent on the same SQL Server Virtual Machine.
SSIS then loads the data into Azure SQL Data Warehouse using the PolyBase engine. Some dimension tables are loaded without PolyBase engine (using direct Inserts) as the number of records are very small. For larger dimension tables with a considerable number of rows and columns, the customer chose to vertically divide the tables to overcome certain limitations of the PolyBase engine. Azure Automation is used to schedule on-cloud maintenance activities such as re-indexing, and statistics updating for Azure SQL Data Warehouse.
This customer implemented a
“Hub and Spoke”
pattern with heavy analytical queries served from the “hub” and smaller queries (fetching few rows with FILTER conditions) served from the “spoke”. Azure SQL Data Warehouse functions as the Hub and SQL Server 2016 running on Azure Virtual Machines functions as the Spoke. This SQL Server 2016 instance has a subset of the data from Azure SQL Data Warehouse. For Ad hoc reporting /dashboards another spoke using Azure Analysis Services with the In-Memory tabular data model option is being evaluated. More spokes can be added in future if needed.
Azure Active Directory
Authentication is used for connecting to Azure SQL Data Warehouse. The user accounts are assigned specific
resource classes
in Azure SQL Data Warehouse depending on the quantum of the workload. Based on factors such as the nature of operations (data loading, maintenance activities, ad hoc queries, application queries, etc.) and priority, a relevant user account with the appropriate resource class connects to Azure SQL Data Warehouse.
Azure SQL Data Warehouse firewall rules are used to restrict IP ranges that connect to Azure SQL Data Warehouse. Encryption at rest is used with Azure Storage and Azure SQL Data Warehouse. All IaaS VMs and PaaS services are chosen from same Azure region. A Disaster Recovery (DR) setup in a secondary Azure region can be easily implemented by using Always on for SQL Server 2016, periodically copying backups of Azure Analysis Services data and by enabling geo-redundant backups in Azure SQL Data Warehouse.
Best Practices
To realize the benefits from a PaaS based solution architecture, it is important to follow a few best practices.
Co-locate Services:
When you allocate a set of PaaS services that need to communicate with each other, consider co-locating the services in the same Azure region to reduce inter-service latencies and any cross-datacenter network traffic charges. Certain services may not be available in all regions, so you may need to plan your deployment accordingly.
Understand Service Limits
: Each PaaS service works within certain limits, and these limits keep getting regularly raised. For example, there are
resource limits on Azure SQL Database
. You should design your application to work within the limits. There can be some difference between the capability in the SQL Server product suite and equivalent cloud service capabilities. For e.g. Azure Analysis Services currently supports only tabular models at the 1200 and 1400 Preview compatibility levels, whereas SQL Server Analysis Services also supports Multi-dimensional models
Design to Scale Out:
As a general best practice on any public cloud, you can realize greater benefits by designing for scale out. Using multiple smaller data stores instead of a single large one, doing horizontal/vertical partitioning etc., are common strategies to consider when you need to work within service limits. Azure SQL Database even provides elastic database tools to
scale out Azure SQL Databases
.
Pausing and Scaling
: Some services offer a pause and resume feature – you should consider using it to reduce costs. When you have a period of inactivity (say night times or weekends as applicable), you can pause Azure SQL Data Warehouse further reducing your bill. Not all services offer a pause feature though. But there are other options to control costs based on demand, such as changing performance levels within a tier, and moving from a higher performance tier to a lower tier. The reverse (scaling up or moving to a higher tier) applies for periods of high activity. If you know that the pausing/scaling needs to be done periodically, you can consider automating the pause/scale using Azure Automation.
Semantic layer with Azure Analysis Services:
Creating an abstraction, or a semantic layer, between the data warehouse and the end user, as supported by Azure Analysis Services, makes it easier for users to query data. In addition, Azure Analysis Services in Cache mode supports more concurrent users than Azure SQL Data Warehouse. If the number of report users is large, and/or a lot of ad hoc reporting queries are used, then instead of connecting Power BI directly to your Azure SQL Data Warehouse, it is good to buffer such access though Azure Analysis Services.
Follow the best practices specific to each individual service:
It is important to follow the documented best practices for each individual service, if mentioned in the documentation. For example, with Azure SQL Data Warehouse it is important to
drain transactions
before pausing or scaling an Azure SQL Data Warehouse, else the pause or scale can take a long time to complete. There is a number of other individual best practices for Azure SQL Data Warehouse as documented
here
and
patterns
and
anti-patterns
that are important to understand.
Refer to the product documentation of other services and
AzureCAT
and
SQLCAT
blogs for more information.