This post has been republished via RSS; it originally appeared at: DataCAT articles.
First published on MSDN on Sep 09, 2013
Authored by AzureCAT team
As of September 1, 2013 we decided to remove SQLCAT.COM site and use MSDN as the primary vehicle to post new SQL Server content. This was done to minimize reader confusion and to streamline content publication.
MSDN SQLCAT blogs
already includes most SQLCAT.COM Content and will continue to be updated with more SQLCAT learnings.
To make the transition to MSDN smoother, we are in the process of reposting a few of SQLCAT.COM’s blogs that are still being very actively viewed. Following is reposting of one of the SQLCAT.Com blogs that still draws huge interest.
Also, Follow us on Twitter as we normally use our Twitter handles
@SQLCAT
and
@WinAzureCAT
to announce new news.
Thank you for your interest.
When to Breakdown Complex Queries
Writer:
Steve Howard
Technical Reviewers:
BoB Taylor, Jay Askew, David Levy, James Podgorski, Thomas Kejser, Shaun Tinline-Jones, Stuart Ozer, Lubor Kollar, Campbell Fraser, Kun Cheng, Venkata Raj Pochi
raju
Published:
October 2011
Applies to:
Microsoft SQL Server 2005, Microsoft SQL Server 2008, Microsoft SQL Server 2008 R2, Microsoft SQL Server code-named “Denali,” SQL Azure
Executive Summary
Microsoft SQL Server is able to create very efficient query plans in most cases. However, there are certain query patterns that can cause problems for the query optimizer; this paper describes four of these patterns. These problematic query patterns generally create situations in which SQL Server must either make multiple passes through data sets or materialize intermediate result sets for which statistics cannot be maintained. Or, these patterns create situations in which the cardinality of the intermediate result sets cannot be accurately calculated.
Breaking these single queries into multiple queries or multiple steps can sometimes provide SQL Server with an opportunity to compute a different query plan or to create statistics on the intermediate result set. Taking this approach instead of using query hints lets SQL Server continue to react to changes in the data characteristics as they evolve over time.
Although the query patterns discussed in this paper are based on customer extract, transform, and load (ETL) and report jobs, the patterns can also be found in other query types.
This paper focuses on the following four problematic query patterns:
·
OR logic in the WHERE clause
In this pattern, the condition on each side of the OR operator in the WHERE or JOIN clause evaluates different tables. This can be resolved by use of a UNION operator instead of the OR operator in the WHERE or JOIN clause.
·
Aggregations in intermediate results sets
This pattern has joins on aggregated data sets, which can result in poor performance. This can be resolved by placing the aggregated intermediate result sets in temporary tables.
·
A large number of very complex joins
This pattern has a large number of joins, especially joins on ranges, which can result in poor performance because of progressively degrading estimates of cardinality. This can be resolved by breaking down the query and using temporary tables.
·
A CASE clause in the WHERE or JOIN clause
This pattern has CASE operators in the WHERE or JOIN clauses, which cause poor estimates of cardinality. This can be resolved by breaking down the cases into separate queries and using the Transact-SQL IF statement to direct the flow for the conditions.
An understanding of the concepts introduced in these four cases can help you identify other situations in which these or similar patterns are causing poor or inconsistent performance; you can then construct a replacement query which will give you better, more consistent performance.
Query Anti-Pattern 1: OR Logic in the WHERE Clause
There are several options for putting an OR operator in the WHERE clause, and not all of the options produce poor results. The following tested examples can help you determine whether or not your query might produce poor query plans and what those plans might look like.
Nonproblematic Uses of OR
Following are some examples of uses of OR that do not cause problems:
·
WHERE a.col1 = @val1 OR a.col1 = @val2 …
This pattern is just another way of writing WHERE col1 IN (@val1, @val2 …). Testing this pattern did not produce poor query plans. However, note that each value in parentheses requires SQL Server to navigate from the top of an index B tree to the bottom, increasing the number of logical reads by the depth of the index multiplied by the number of values in parentheses.
The key to this pattern is that the same column is being evaluated by both sides of the OR operator. In the example, this column is col1. If an index exists with col1 as its first column, a seek operation on this index can satisfy each condition. If the index is small and does not cover the query, you might get a scan. The same guidelines apply to covering indexes with this pattern as apply to other queries.
·
WHERE a.col1 = @val1 OR a.col2 = @val2 …
In this query pattern, two columns in the same table are evaluated by the two sides of the OR operator. If two indexes exist on this table—one with col1 as its leading column and the other with col2 as its leading column—then SQL Server will run a scan if the tables are small. However, when the data set gets large enough, SQL Server will use an index union to retrieve the rows. (See Figure 1.) When SQL Server is able to use this index union, this query pattern is not a problem.

Figure 1: In this query plan, the pattern of WHERE a.col1 = @val1 OR a.col2 = @val2 is used on a large table. The query plan used involves an index union to retrieve the rows meeting either requirement. The Stream Aggregate operator eliminates any duplicates. The Key Lookup operator is required after elimination of duplicates to retrieve columns in rows where ManagerID = 10, but the columns are not included in the forTest index.
·
WHERE a.col1 = @val1 OR a.col2 IN (SELECT col2 FROM tab2)
By analyzing this pattern, you can see that SQL Server rewrote the IN clause and performed a join to tab2, as expected. Different indexes are used to retrieve the rows that fit either condition, and the results are sorted to eliminate duplicates at the end. (See Figure 2.) This is an efficient plan; applying the techniques discussed in this paper does not result in a better query plan.

Figure 2: This plan uses a variation of the pattern WHERE a.col1 = @val1 OR a.col2 IN (SELECT col2 FROM tab2). The retrieval from the dbo.Employee table (which would be ‘a’ in the pattern) is performed with two seeks. The smallest table is scanned because there is no filter in the IN clause. The plan produced is not problematic.
Problematic Use of OR
In the examples above, the condition on each side of the OR operator evaluated the same table; therefore, these plans were not problematic. However, when the conditions on each side of the OR operator are evaluating different tables, problems can arise:
·
WHERE a.col1 = @val1 OR b.col2 = @val2
The pattern represented by this query predicate is problematic. Breaking down the query into two steps produces a significantly “cheaper” plan. Note that in this pattern, there are two tables involved; on each side of the OR operator is a condition that applies to different tables. This problematic condition is detailed, from setup to execution, in Appendix A: Example of a Problematic Use of OR.
Note:
For simplicity, the pattern is written using only equality (=) as a condition. However, using inequality or variants such as a condition that contains BETWEEN can create the same situation.
Following is the example query described in Appendix A, which causes a problematic query plan.
/*
The first script uses local variables to set up the range
and uses the OR logic in the WHERE clause
*/
DECLARE@minEmpINT
DECLARE@maxEmpINT
SET@minEmp= 100
SET@maxEmp= 200
SELECTe.*FROMdbo.Employeee
LEFTJOINAdventureworks.Person.ContactcONe.EmployeeId=c.ContactID
WHEREEmployeeIdBETWEEN@minEmpand@maxEmp
ORc.EmailAddressIN('sabria0@adventure-works.com','teresa0@adventure-works.com','shaun0@adventure-works.com')
You can see that the OR condition is now between a condition on dbo.Employee.EmployeeID and Adventureworks.Person.Contact.EmailAddress.
A quick check of indexes on Person.Contact shows the indexes listed in Table 1.
Table 1. Indexes for Adventureworks.Person.Contact
index_name
|
index_description
|
index_keys
|
AK_Contact_rowguid
|
nonclustered, unique located on PRIMARY
|
rowguid
|
IX_Contact_EmailAddress
|
nonclustered located on PRIMARY
|
EmailAddress
|
PK_Contact_ContactID
|
clustered, unique, primary key located on PRIMARY
|
ContactID
|
An index exists on Adventureworks.Person.Contact (EmailAddress) that should be able to retrieve the three email addresses requested in the query. The primary key on dbo.Employee in the example tables is on EmployeeId, and the supporting index is clustered. SQL Server should be able to retrieve the results from the two tables with two inexpensive index seeks. However, executing the query results in an execution plan in which SQL Server scans the clustered index on both tables involved in the join. (See Figure 4.)
Figure 4: In this query pattern, SQL Server scans the clustered index on both tables involved in the join.
When STATISTCS IO and STATISTCS TIME are set to ON, as they are in the example in Appendix A, the query plan results in the following output.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 1 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
Table 'Contact'. Scan count 1, logical reads 569, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Employee'. Scan count 1, logical reads 6963, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 94 ms, elapsed time = 304 ms.
SQL Server Execution Times:
CPU time = 94 ms, elapsed time = 304 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
The result is a total of 7,532 page reads and 94 milliseconds of CPU time. This may not be noticeable in a small system in which the plan is not executed frequently. However, as tables grow in size or as a query grows in complexity, this type of query can become a drain on the system because both the number of page reads and the CPU time will increase as the data size increases.
To reduce the cost, you can break down the query into separate queries that SQL Server can interpret more easily; you can rewrite the query, breaking the WHERE clause predicates into conditions that apply to the tables individually.
For a simple query such as that in the example, it is easy to see that the end result set is a union of results that meet the condition of a.EmployeeId between 100 and 200 and the rows that have the three email addresses you are searching for, as shown below.
DECLARE @minEmp INT
DECLARE @maxEmp INT
SET @minEmp = 100
SET @maxEmp = 200
SELECT e.*FROM dbo.Employee e
LEFTJOIN Adventureworks.Person.Contact c ON e.EmployeeId = c.ContactID
WHERE EmployeeId BETWEEN @minEmp and @maxEmp
UNION
SELECT e.*FROM dbo.Employee e
LEFTJOIN Adventureworks.Person.Contact c ON e.EmployeeId = c.ContactID
WHERE
c.EmailAddress in('sabria0@adventure-works.com','teresa0@adventure-works.com','shaun0@adventure-works.com')
Though functionally equivalent to the original query, SQL Server now handles this query differently. In this query plan, a UNION is used instead of an OR condition. By using the UNION, SQL Server is able to perform seeks on all indexes, reducing the overall query cost. (See Figure 5.)
Figure 5: In this query plan, a UNION is used instead of an OR condition. By using the UNION, SQL Server is able to perform seeks on all indexes, and the overall query cost has been reduced dramatically.
The results of STATISTICS IO and STATISTICS TIME when executing this query are as follows.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 8 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
Table 'Employee'. Scan count 1, logical reads 17, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Contact'. Scan count 3, logical reads 9, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 212 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
Although it required a little more typing, using the UNION in place of the OR reduced the number of page reads to 26 and the CPU time to less than one millisecond.
Note that the example above was simplified for illustration. For a more realistic query and improvement using this break-down method, see Appendix B: Example of a Query Improved by Using UNION Instead of OR.
Query Anti-Pattern 2: Aggregations in Intermediate Result Sets
Keywords such as GROUP BY or DISTINCT produce result sets with a different number of rows than that stored in the table. If these intermediate result sets are then joined to other tables or data sets, statistics on the intermediate result sets do not exist. SQL Server tries to estimate cardinality based on the original data sets, but these estimates can quickly degrade in accuracy. An inaccurate estimate of cardinality at any place in a query can lead to a poor query plan.
When poor cardinality estimates result from out-of-date statistics, updating the statistics on the tables or indexes in a query can improve the query plan. However, no statistics on the intermediate result set are available when a query is written in such a way that the intermediate result set must first be materialized and then used in subsequent steps in the query plan. Although derived from the statistics on the base tables, estimates of cardinality might not be accurate enough to consistently produce a good execution plan.
Appendix C and Appendix D of this paper provide an example of a query pattern that results in poor performance caused by aggregations in intermediate result sets. In production systems, queries such as those in the example are sometimes found in ETL or report jobs.
Appendix C: Setup for Aggregations Example contains the setup for the example. Note that the challenge in demonstrating this pattern is getting enough data to set up the situation. The setup in Appendix C creates just enough data to show the beginnings of performance degradation. Note also that it can take five or more minutes to run the script in Appendix C.
Appendix D: Aggregation Example Queries contains two queries that demonstrate the problem and the solution.
To prepare to run the example, follow these steps:
1. Copy the setup queries from Appendix C into a query window, and execute them.
2. Copy Query 1 and Query 2 from Appendix D into separate query windows pointing to the database you used when you ran the setup in Appendix C.
3. In each window from step 2, run SET STATISTICS IO ON and SET STATISTICS TIME ON.
4. Click
Include Actual Execution Plan
at the top of the page.
After the setup is complete, run Query 1 from Appendix D twice; the first execution will include parse, execute time, and physical reads, which might skew the comparison to Query 2. After the second execution has completed, click the
Execution plan
tab (next to the
Results
and
Messages
tabs). Hold the mouse over the nodes and lines, and compare the “Actual Number of Rows” with the “Estimated Number of Rows” in the tool tip that appears for each node and line.
Notice that near the beginning of the data flow, the estimated number of rows and actual number of rows are very similar. However, as each aggregated intermediate result set is joined to other aggregated intermediate result sets, the quality of the estimate degrades quickly.
As you follow the flow of data from right to left, and particularly from the bottom of the query plan toward the top of the query plan, you can see that the estimated number of rows quickly decreases even though the actual number of rows does not. Eventually, the estimated number of rows reaches one, even though the actual number of rows is over 300, as determined by the number of rows in the “Customer” table. (See Figure 6.)
Figure 6: As joins are made between aggregated intermediate result sets, the "Estimated Number of Rows" diverges farther from the "Actual Number of Rows," as you can see in the tool tip that appears in the execution plan.
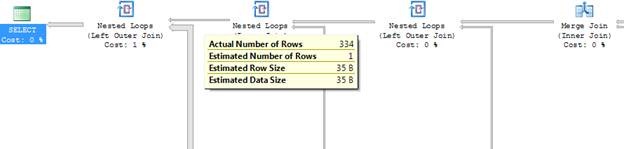
When SQL Server underestimates the size of the data set from an operation, it can cause the query optimizer to make suboptimal decisions for strategies such as joins or join order in subsequent operations. For example, a particularly poor decision underestimation can lead to is the use of the intermediate result set as the “outer table” (the table accessed first) in a nested loop join. (See Figure 7.)
Figure 7: SQL Server underestimates the number of rows at this stage in the execution plan, leading to the decision to use a nested loop join strategy for the next left outer Join.
In the nested loop join, the operation on the inner table (the table accessed second, i.e., the one on the bottom) must be performed for each row in the outer table, or result set. In this example, SQL Server chooses a nested loop because the estimated number of rows in the outer result set is one; the estimate shows that the inner operation must be performed only once.
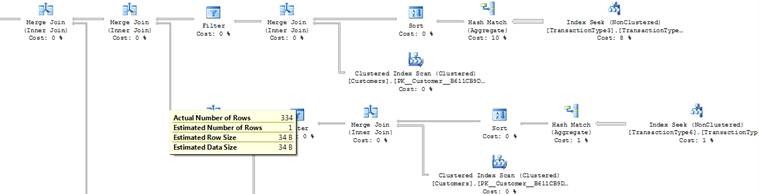
The underestimation becomes a problem when the inner operation is a scan, such as an index or table scan. (See Figure 8.) As shown in Figure 8, there are actually 334 rows going into the nested loop join, while the query plan was created on an estimate for only one row.
Figure 8: A wider view of the part of the query plan shows that the table scan (at the bottom) will be performed 334 times rather than the one time that the estimated number of rows would indicate. This type of underestimation with a nested loop join can cause the query cost to skyrocket.
As a result of the estimate, SQL Server determined that it was optimal to scan the SurveyDetails table instead of using any indexes that are in place or using a different join strategy. The scan of SurveyDetails would have accounted for 18 percent of the total query cost if the estimates were correct. However, since there are 334 rows instead of one, the operation that was originally estimated to be performed once was actually performed 334 times. This is the type of cost explosion that can occur from underestimated cardinality.
Since the statistics were all up to date at the time the query plan was compiled, this is as close as SQL Server could come with this query pattern. SQL Server needs to be able to calculate statistics on the intermediate result sets to make a better decision in this case.
Resolving the Issue
To avoid suboptimal query plans that cause cost explosion, you can use temporary tables to allow SQL Server to compute statistics and recompile.
Note:
You must use temporary tables, not table variables. While statistics for the data are created when temporary tables are populated, they are neither created nor maintained on table variables. However, when a table variable is used in a query hinted with OPTION (RECOMPILE), row count estimates from the table variable are obtained at recompile time.
Query 2 in Appendix D gets the same results as the first query but actually uses two queries. The first query is the SELECT … INTO query; this is used to bring the aggregated result set into a temporary table. Once the result set is in a temporary table, SQL Server can create or update statistics and compile or recompile a query plan as needed to ensure that cost explosion in the first query does not occur.
A second query is then used to get the final results; this query joins the intermediate result set in #temp to the last two tables. (See Figure 9.)
Figure 9: This plan breaks down the query by using a temporary table, SQL Server is able to compute statistics on the intermediate result set.
You can see that SQL Server has taken a few steps to make the overall query much more efficient, the most significant of which is to change the join types to hash match joins so that no scans are performed multiple times.
Note
: As query complexity increases, there are different ways you can break down the query to benefit performance. For example, each aggregated data set could be selected into a temporary table. You should follow the query plan and find places where there is a significant underestimation in the number of rows; good candidates are places where SQL Server estimates one row when a larger set is returned.
Is There Significant Improvement?
While the actual numbers might vary slightly because of the randomization used in creating the example data set, the improvement should be significant. Table 2 shows the key total statistics from STATISTICS IO and STATISTICS TIME obtained in the test run used to produce the example.
Table 2. Improvement on the demo data by breaking the query into two queries and using a temp table
Metric
|
First query
|
Second query
|
Improvement
|
Logical reads
|
1,622,398
|
11,685
|
99.90%
|
CPU time (ms)
|
4,914
|
1,139
|
76.82%
|
Elapsed time (ms)
|
5,278
|
2,803
|
46.89%
|
As the size of the data increases, performance degradation increases rapidly. Additional complexity in the query can also increase the performance degradation. The data in the example is just large enough to begin to show the benefit of breaking down the query in this pattern.
Although the example uses derived tables for aggregated data sets, the same situation can be created with common table expressions (CTEs) or with views that aggregate data in logical tables. Follow the same steps, and use temporary tables to store intermediate result sets in places where statistics need to be created to consistently obtain good estimates of cardinality for subsequent operations in the query plan.
Other Options
Note that the query plan on the first query indicated a missing index. Creating this index will eliminate the table scan and may improve the query performance, at least for smaller sets. These types of queries, however, typically appear as ETL or report queries, which are run only periodically. The tradeoff for maintaining this index during normal processing might be large. You should evaluate the tradeoff for your situation before deciding to add an index.
An option in some scenarios is to hint a hash join. However, note that this is not always the best option. Using the temp table to hold the intermediate result set allows the optimizer to evaluate the data as it is at execution time and to select an optimal query plan regardless of data changes. This tends to provide consistent query performance that might not always be offered by the join hint.
Another possible resolution is to create an indexed view representing the aggregated data set. In this case, statistics will be maintained on the indexed view. However, the indexed view can require a significant amount of maintenance during normal data modifications, and this can become a source of lock contention. You should evaluate all possible solutions carefully in light of your needs.
Other Query Types to Break Down
The two examples discussed in the previous sections are not the only ones for which breaking a single, complex query into multiple queries can result in more consistent performance. The optimizer is constantly being improved, and you might find other queries that can benefit from being broken down. Some examples include:
·
A query with a large number of very complex joins
With each subsequent join, the original data set becomes farther removed from the initial data set, and more factors are introduced into the estimation of cardinality. Data anomalies within a single table can cause a skewed cost estimate that is then multiplied across every subsequent join.
In queries with large numbers of joins, it might be better to break down the query into multiple queries, bringing intermediate result sets into temporary tables. You can then perform subsequent operations or joins on the intermediate sets in temporary tables.
·
A CASE clause in the WHERE or JOIN clause
This case refers specifically to a clause such as WHERE col1 = CASE @val1 WHEN 1 THEN ‘val1’ WHEN 2 THEN ‘val2’ WHEN 3 THEN col1. Such clauses create situations in which the number of rows is difficult, if not impossible, to estimate. Any time the number of rows can be badly misestimated, a poor query plan can result.
Instead of trying to include such logic in a query, use the Transact-SQL conditional statements IF and ELSE IF to break the conditions into multiple statements that can cover the different possible values for @val1. Breaking down the query in this way leads to a more accurate estimation of results.
Conclusion
It is seldom, if ever, necessary to perform all the work of retrieving a complex data set in a single query. In some situations, such as joining to an aggregated result, performing all steps within a single query can result in poorly estimated cardinality. This poor estimate can lead to poorly performing queries. In a single query, SQL Server cannot pause during query execution, calculate statistics on the intermediate result sets, and adjust the query plan accordingly.
Breaking down a query and storing the aggregated or intermediate result sets in a temporary table lets SQL Server do what it cannot do in a single query: calculate statistics on the intermediate result set and recalculate the execution plans on subsequent steps. Using a UNION or using IF logic also allows SQL Server to calculate more efficient query plans that provide the same results.
In SQL Server query design, good performance depends not only on obtaining the results, but also on how the results were retrieved. While the optimizer works well in most situations, there are times when statistics cannot be computed and you need to change the way you retrieve the results to get consistently good performance. This paper discusses techniques you can use to break down large and complex queries into smaller parts to improve performance.
Appendix A: Example of a Problematic Use of OR
This section illustrates the problematic query pattern
WHERE a.col1 = @val1 OR b.col2 = @val2
.
Breaking down the query into two steps produces a significantly “cheaper” plan.
To set up this example, follow these steps:
1. Ensure that the Adventureworks demo database is installed on SQL Server.
2. Run the following script to set up the other tables that are needed.
USE tempdb
go
SETNOCOUNTON
GO
IFOBJECT_ID('dbo.Employee')ISNOTNULL
DROPTABLE dbo.Employee
GO
/*
Create the first table to be used in the demo
*/
CREATETABLE dbo.Employee
(
EmployeeId INT NOTNULL PRIMARYKEY IDENTITY(1, 1)
, ManagerId INT NOTNULL
, NationalIDNbr NVARCHAR(15) NOTNULL
, Title NVARCHAR(15) NOTNULL
, BirthDate DATETIME NOTNULL
, OtherStuff NCHAR(100) NOTNULL DEFAULT' ' -- just to take up space a normal record might take up
, ModifiedDate DateTime NOTNULL
)
ALTERTABLE dbo.Employee ADDCONSTRAINT FK_Mgr FOREIGNKEY (EmployeeID)REFERENCES Employee(EmployeeID)
GO
-- create a function to create sort-of unique ID nbrs:
IFOBJECT_ID('dbo.IDNbr')ISNOTNULL
DROPFUNCTION dbo.IDNbr
GO
CREATEFUNCTION IDNbr(@count int)
RETURNSNVARCHAR(15)
BEGIN
DECLARE @first NCHAR(3)
DECLARE @second NCHAR(2)
DECLARE @third NCHAR(4)
DECLARE @retval NVARCHAR(15)
DECLARE @cur INT
SET @cur = @count % 997
IF @cur < 10
SET @first =N'00'+CAST(@cur ASNCHAR(1))
ELSEIF @cur < 100
SET @first =N'0'+CAST(@cur ASNCHAR(2))
ELSESET @first =CAST(@cur asNCHAR(3))
SET @cur = @count % 97
IF @cur < 10
SET @second =N'0'+CAST(@cur ASNCHAR(1))
ELSE
SET @second =CAST(@cur ASNCHAR(2))
SET @cur = @count % 9973
IF @cur < 10
SET @third =N'000'+CAST(@cur ASNCHAR(1))
ELSEIF @cur < 100
SET @third =N'00'+CAST(@cur ASNCHAR(2))
ELSEIF @cur < 1000
set @third =N'0'+CAST(@cur ASNCHAR(3))
ELSESET @third =CAST(@cur asNCHAR(4))
SET @retval = @first +N'-'+ @second +N'-'+ @third
RETURN @retval
END
GO
-- insert the primary record:
INSERT dbo.Employee(ManagerId, NationalIDNbr, Title, BirthDate, ModifiedDate)VALUES (1,'123-45-6789','Big Boss','1938-01-01',GETDATE())
-- the next 9 records are for the other managers. They all work for the Big Boss:
INSERT dbo.Employee(ManagerId, NationalIDNbr, Title, BirthDate, ModifiedDate)VALUES (1,'123-45-0001','Yes Man','1940-01-01',GETDATE())
INSERT dbo.Employee(ManagerId, NationalIDNbr, Title, BirthDate, ModifiedDate)VALUES (1,'123-45-0002','Yes Man','1940-01-01',GETDATE())
INSERT dbo.Employee(ManagerId, NationalIDNbr, Title, BirthDate, ModifiedDate)VALUES (1,'123-45-0003','Yes Man','1940-01-01',GETDATE())
INSERT dbo.Employee(ManagerId, NationalIDNbr, Title, BirthDate, ModifiedDate)VALUES (1,'123-45-0004','Yes Man','1940-01-01',GETDATE())
INSERT dbo.Employee(ManagerId, NationalIDNbr, Title, BirthDate, ModifiedDate)VALUES (1,'123-45-0005','Yes Man','1940-01-01',GETDATE())
INSERT dbo.Employee(ManagerId, NationalIDNbr, Title, BirthDate, ModifiedDate)VALUES (1,'123-45-0006','Yes Man','1940-01-01',GETDATE())
INSERT dbo.Employee(ManagerId, NationalIDNbr, Title, BirthDate, ModifiedDate)VALUES (1,'123-45-0007','Yes Man','1940-01-01',GETDATE())
INSERT dbo.Employee(ManagerId, NationalIDNbr, Title, BirthDate, ModifiedDate)VALUES (1,'123-45-0008','Yes Man','1940-01-01',GETDATE())
INSERT dbo.Employee(ManagerId, NationalIDNbr, Title, BirthDate, ModifiedDate)VALUES (1,'123-45-0009','Yes Man','1940-01-01',GETDATE())
-- from here on out, I just need enough records to fill out a decent sized table
DECLARE @ct INT
DECLARE @title VARCHAR(15)
DECLARE @natIdNbr VARCHAR(15)
DECLARE @birthdate DATETIME
-- Next level managers:
set @ct = 0
-- prime numbers to use for modulo for greatest chance of unique national ids: 997, 97, 9973
SET @title ='Manager'
WHILE @ct < 100
BEGIN
set @natIdNbr = dbo.IDNbr(@ct)
set @birthdate ='1941-01-01'
INSERT dbo.Employee(ManagerId, NationalIDNbr, Title, BirthDate, ModifiedDate)VALUES ((@ct % 8)+ 2, @natIdNbr, @title, @birthdate,GETDATE())
set @ct = @ct + 1
END
-- set up the next level:
set @title ='Mid-Level Manager'
WHILE @ct < 1000
BEGIN
set @natIdNbr = dbo.IDNbr(@ct)
set @birthdate ='1942-01-01'
INSERT dbo.Employee(ManagerId, NationalIDNbr, Title, BirthDate, ModifiedDate)VALUES ((@ct % 90)+ 10, @natIdNbr, @title, @birthdate,GETDATE())
set @ct = @ct + 1
END
-- set up junior level managers:
set @title ='Junior-Level Manager'
WHILE @ct < 10000
BEGIN
set @natIdNbr = dbo.IDNbr(@ct)
set @birthdate ='1943-01-01'
INSERT dbo.Employee(ManagerId, NationalIDNbr, Title, BirthDate, ModifiedDate)VALUES ((@ct % 900)+ 100, @natIdNbr, @title, @birthdate,GETDATE())
set @ct = @ct + 1
END
-- set up the workers:
set @title ='Worker'
WHILE @ct < 100000
BEGIN
set @natIdNbr = dbo.IDNbr(@ct)
set @birthdate ='1944-01-01'
INSERT dbo.Employee(ManagerId, NationalIDNbr, Title, BirthDate, ModifiedDate)VALUES ((@ct % 9000)+ 1000, @natIdNbr, @title, @birthdate,GETDATE())
set @ct = @ct + 1
END
insertinto Employee(ManagerId, NationalIDNbr, Title, BirthDate, ModifiedDate)
select ManagerId, NationalIDNbr, Title, BirthDate, ModifiedDate from Employee where EmployeeId > 1
alterindexallon Employee rebuild
createindex forTest on Employee(ManagerID)
Run the following statements in the connection you will be using to run the test queries; this lets you compare reads and time when executing the rest of the queries.
SETSTATISTICSIOON
SETSTATISTICSTIMEON
After these statements are run, your connection is ready to run the queries. If you want to free the procedure cache, you can run DBCC FREEPROCCACHE between runs to be sure you are getting newly compiled plans each time.
The following are the queries and scripts you can test one at a time.
/*
The first script uses local variables to set up the range
and uses the OR logic in the WHERE clause
*/
DECLARE @minEmp INT
DECLARE @maxEmp INT
SET @minEmp = 100
SET @maxEmp = 200
SELECT e.*FROM dbo.Employee e
LEFTJOIN Adventureworks.Person.Contact c ON e.EmployeeId = c.ContactID
WHERE EmployeeId BETWEEN @minEmp and @maxEmp
OR c.EmailAddress IN('sabria0@adventure-works.com','teresa0@adventure-works.com','shaun0@adventure-works.com')
GO
/*
The second script uses local variables to set up the range
and uses a UNION instead of the OR logic so that seeks can
be done on the indexes instead of scans
*/
DECLARE @minEmp INT
DECLARE @maxEmp INT
SET @minEmp = 100
SET @maxEmp = 200
SELECT e.*FROM dbo.Employee e
LEFTJOIN Adventureworks.Person.Contact c ON e.EmployeeId = c.ContactID
WHERE EmployeeId BETWEEN @minEmp and @maxEmp
UNION
SELECT e.*FROM dbo.Employee e
LEFTJOIN Adventureworks.Person.Contact c ON e.EmployeeId = c.ContactID
WHERE
c.EmailAddress in('sabria0@adventure-works.com','teresa0@adventure-works.com','shaun0@adventure-works.com')
GO
/*
The third query is a parameterized query using sp_executesql.
It uses parameters instead of local variables.
This sets up the possibility of parameter sniffing changing query plans.
Experiment with ranges to see that the query plan does not change.
This query uses the OR logic in the WHERE clause.
*/
EXECsp_executesqlN'SELECT e.* FROM dbo.Employee e
LEFT JOIN Adventureworks.Person.Contact c ON e.EmployeeId = c.ContactID
WHERE EmployeeId BETWEEN @minEmp and @maxEmp
OR c.EmailAddress IN (''sabria0@adventure-works.com'', ''teresa0@adventure-works.com'', ''shaun0@adventure-works.com'')'
,N'@minEmp int, @maxEmp int', 100, 200
GO
/*
The third query is a parameterized query using sp_executesql.
It uses parameters instead of local variables.
This sets up the possibility of parameter sniffing changing query plans.
Experiment with ranges to see that the query plan does not change.
This query uses the UNION to replace the OR logic in the WHERE clause.
*/
EXECsp_executesqlN'SELECT e.* FROM dbo.Employee e
LEFT JOIN Adventureworks.Person.Contact c ON e.EmployeeId = c.ContactID
WHERE EmployeeId BETWEEN @minEmp and @maxEmp
UNION
SELECT e.* FROM dbo.Employee e
LEFT JOIN Adventureworks.Person.Contact c ON e.EmployeeId = c.ContactID
WHERE
c.EmailAddress in (''sabria0@adventure-works.com'', ''teresa0@adventure-works.com'', ''shaun0@adventure-works.com'')'
,N'@minEmp int, @maxEmp int', 100, 200
Appendix B: Example of a Query Improved by Using UNION Instead of OR
This section shows an example of a query that is improved by using UNION instead of OR.
Original Query
The original query is as follows.
select s.AdvAssignment from study s
innerjoin Assignment_Status cnd on (s.AdvAssignment = cnd.AdvAssignment)
leftouterjoin UserAssignment us on( s.AdvAssignment = us.AdvAssignment)
where (us.AdvUser = @userid
and(us.assigndate <=getdate()and us.assigndateend >=getdate()))
or s.AdvReference in(select adv from @userListGroup)
and s.AdvInvalidated ISNULL
and(cnd.Digital_Attachment_Nbr > 0
andnot(cnd.Adv_Nbr = 0 andISNULL(cnd.Doc_Flag,'N')='Y')
or s.Is_Image= 1)
Query Using UNION
Following is the query after it has been broken down and UNION is used instead of OR.
select s.AdvAssignment from study s
innerjoin Assignment_Status cnd on (s.AdvAssignment = cnd.AdvAssignment)
where
s.AdvReference in(select adv from @userListGroup)
and s.AdvInvalidated ISNULL
and(cnd.Digital_Attachment_Nbr > 0
andnot(cnd.Adv_Nbr = 0 andISNULL(cnd.Doc_Flag,'N')='Y')
or s.Is_Image= 1)
UNION
select s.AdvAssignment from study s
innerjoin Assignment_Status cnd on (s.AdvAssignment = cnd.AdvAssignment)
leftouterjoin UserAssignment us on( s.AdvAssignment = us.AdvAssignment)
where (us.AdvUser = @userid
and(us.assigndate <=getdate()and us.assigndateend >=getdate()))
and s.AdvInvalidated ISNULL
and(cnd.Digital_Attachment_Nbr > 0
andnot(cnd.Adv_Nbr = 0 andISNULL(cnd.Doc_Flag,'N')='Y')
or s.Is_Image= 1)
Appendix C: Setup for Aggregations Example
This section provides the setup for the aggregations example.
/*
Do this all in tempdb to get the auto-cleanup after restart if all is forgotten
*/
USE tempdb
GO
SETNOCOUNTON
SETSTATISTICSIOOFF
SETSTATISTICSTIMEOFF
GO
/*
Cleanup so multiple runs can be done if necessary
*/
IFOBJECT_ID('dbo.Customers')ISNOTNULL
DROPTABLE dbo.Customers
IFOBJECT_ID('dbo.InternetOrders')ISNOTNULL
DROPTABLE dbo.InternetOrders
IFOBJECT_ID('dbo.StoreOrders')ISNOTNULL
DROPTABLE dbo.StoreOrders
IFOBJECT_ID('dbo.InternetQuotes')ISNOTNULL
DROPTABLE dbo.InternetQuotes
IFOBJECT_ID('dbo.StoreQuotes')ISNOTNULL
DROPTABLE dbo.StoreQuotes
IFOBJECT_ID('dbo.SurveyResults')ISNOTNULL
DROPTABLE dbo.SurveyResults
IFOBJECT_ID('dbo.SurveyDetails')ISNOTNULL
DROPTABLE dbo.SurveyDetails
IFOBJECT_ID('dbo.TransactionType3')ISNOTNULL
DROPTABLE dbo.TransactionType3
IFOBJECT_ID('dbo.TransactionType4')ISNOTNULL
DROPTABLE dbo.TransactionType4
IFOBJECT_ID('dbo.TransactionType5')ISNOTNULL
DROPTABLE dbo.TransactionType5
IFOBJECT_ID('dbo.TransactionType6')ISNOTNULL
DROPTABLE dbo.TransactionType6
/*
create tables for customers, internet orders, and store orders
*/
CREATETABLE dbo.Customers
(
customerID INT NOTNULL PRIMARYKEY IDENTITY(1, 1)
, customerName VARCHAR(30)NOTNULL
, otherStuff NCHAR(100) NULL
)
GO
CREATETABLE dbo.InternetOrders
(
customerID INT NOTNULL
, orderID INT NOTNULL PRIMARYKEY IDENTITY(1, 1)
, orderTotal MONEY NOTNULL
, orderDate DATETIME NOTNULL
, otherDetails NCHAR(100) NULL
)
CREATEINDEX InternetOrders_customerID on InternetOrders(customerID) INCLUDE(orderTotal)
CREATEINDEX InternetOrders_OrderDate ON dbo.InternetOrders(orderDate) INCLUDE(CustomerID, orderTotal)
GO
CREATETABLE storeOrders
(
customerID INT NOTNULL
, storeOrderID INT NOTNULL PRIMARYKEY IDENTITY(1, 1)
, orderTotal MONEY NOTNULL
, orderDate DATETIME NOTNULL
, otherDetails NCHAR(100) NULL
)
CREATEINDEX storeOrders_customerID ON storeOrders(customerID) INCLUDE(orderTotal)
CREATEINDEX StoreOrders_OrderDate ON dbo.StoreOrders(orderDate) INCLUDE(CustomerID, orderTotal)
GO
CREATETABLE dbo.InternetQuotes
(
customerID INT NOTNULL
, quoteID INT NOTNULL PRIMARYKEY IDENTITY(1, 1)
, quoteTotal MONEY NOTNULL
, quoteDate DATETIME NOTNULL
, otherDetails NCHAR(100) NULL
)
CREATEINDEX InternetQuotes_customerID on InternetQuotes(customerID) INCLUDE(quoteTotal)
CREATEINDEX Internetquotes_OrderDate ON dbo.InternetQuotes(quoteDate) INCLUDE(CustomerID, quoteTotal)
GO
CREATETABLE dbo.StoreQuotes
(
customerID INT NOTNULL
, storeQuoteID INT NOTNULL PRIMARYKEY IDENTITY(1, 1)
, quoteTotal MONEY NOTNULL
, quoteDate DATETIME NOTNULL
, otherDetails NCHAR(100) NULL
)
CREATEINDEX StoreQuotes_customerID on StoreQuotes(customerID) INCLUDE(quoteTotal)
CREATEINDEX StoreQuotes_OrderDate ON dbo.StoreQuotes(quoteDate) INCLUDE(CustomerID, quoteTotal)
GO
CREATETABLE dbo.TransactionType3
(
customerID INT NOTNULL
, orderID INT NOTNULL PRIMARYKEY IDENTITY(1, 1)
, orderTotal MONEY NOTNULL
, orderDate DATETIME NOTNULL
, otherDetails NCHAR(100) NULL
)
CREATEINDEX TransactionType3_customerID on dbo.TransactionType3(customerID) INCLUDE(orderTotal)
CREATEINDEX TransactionType3_OrderDate ON dbo.TransactionType3(orderDate) INCLUDE(CustomerID, orderTotal)
GO
CREATETABLE TransactionType4
(
customerID INT NOTNULL
, storeOrderID INT NOTNULL PRIMARYKEY IDENTITY(1, 1)
, orderTotal MONEY NOTNULL
, orderDate DATETIME NOTNULL
, otherDetails NCHAR(100) NULL
)
CREATEINDEX TransactionType4_customerID ON dbo.TransactionType4(customerID) INCLUDE(orderTotal)
CREATEINDEX TransactionType4_OrderDate ON dbo.TransactionType4(orderDate) INCLUDE(CustomerID, orderTotal)
GO
CREATETABLE dbo.TransactionType5
(
customerID INT NOTNULL
, orderID INT NOTNULL PRIMARYKEY IDENTITY(1, 1)
, orderTotal MONEY NOTNULL
, orderDate DATETIME NOTNULL
, otherDetails NCHAR(100) NULL
)
CREATEINDEX TransactionType5_customerID on dbo.TransactionType5(customerID) INCLUDE(orderTotal)
CREATEINDEX TransactionType5_OrderDate ON dbo.TransactionType5(orderDate) INCLUDE(CustomerID, orderTotal)
GO
CREATETABLE TransactionType6
(
customerID INT NOTNULL
, storeOrderID INT NOTNULL PRIMARYKEY IDENTITY(1, 1)
, orderTotal MONEY NOTNULL
, orderDate DATETIME NOTNULL
, otherDetails NCHAR(100) NULL
)
CREATEINDEX TransactionType6_customerID ON dbo.TransactionType6(customerID) INCLUDE(orderTotal)
CREATEINDEX TransactionType6_OrderDate ON dbo.TransactionType6(orderDate) INCLUDE(CustomerID, orderTotal)
GO
CREATETABLE dbo.SurveyResults
(
contactID INT NOTNULL PRIMARYKEY IDENTITY(1, 1)
, customerID INT NULL
, partnerID INT NULL
, aggResults TINYINT NOTNULL
, otherDetails NCHAR(100) NULL
)
CREATEINDEX SurveyReults_CustomerID ON dbo.SurveyResults(CustomerID)
GO
CREATETABLE dbo.SurveyDetails
(
surveyID INT NOTNULL
, questionNbr TINYINT NOTNULL
, customerID INT NOTNULL
, rating TINYINT NOTNULL
, surveyDate DATETIME NOTNULL
, verbatim NCHAR(500) NULL
)
GO
/*
Populate these tables to form the first part of the query
*/
CREATETABLE #firstNamePart
(
namePart NVARCHAR(14)
)
GO
CREATETABLE #secondNamePart
(
namePart NVARCHAR(14)
)
INSERTINTO #firstNamePart VALUES (N'Some')
INSERTINTO #firstNamePart VALUES (N'Another')
INSERTINTO #firstNamePart VALUES (N'Different')
INSERTINTO #firstNamePart VALUES (N'Contoso')
INSERTINTO #firstNamePart VALUES (N'Similar')
INSERTINTO #firstNamePart VALUES (N'Dissimilar')
INSERTINTO #firstNamePart VALUES (N'My')
INSERTINTO #firstNamePart VALUES (N'Your')
INSERTINTO #firstNamePart VALUES (N'Their')
INSERTINTO #firstNamePart VALUES (N'Somebody''s')
INSERTINTO #firstNamePart VALUES (N'This')
INSERTINTO #firstNamePart VALUES (N'That')
INSERTINTO #firstNamePart VALUES (N'Varied')
INSERTINTO #secondNamePart VALUES (N'Inc.')
INSERTINTO #secondNamePart VALUES (N'LLC')
INSERTINTO #secondNamePart VALUES (N'Hobby')
INSERTINTO #secondNamePart VALUES (N'Unlimited')
INSERTINTO #secondNamePart VALUES (N'Limited')
INSERTINTO #secondNamePart VALUES (N'Musings')
INSERTINTO #secondNamePart VALUES (N'Manufacturing')
INSERTINTO #secondNamePart VALUES (N'Exploration')
INSERTINTO #secondNamePart VALUES (N'Enterprise')
INSERTINTO #secondNamePart VALUES (N'Services')
INSERTINTO #secondNamePart VALUES (N'Attempts')
INSERTINTO #secondNamePart VALUES (N'Dreams')
INSERTINTO #secondNamePart VALUES (N'Ideas')
-- populate customer
INSERTINTO dbo.Customers(customerName, otherStuff)
SELECT a.namePart +N' '+ b.namePart,N'otherStuff'
FROM #firstNamePart a CROSSJOIN #secondNamePart b
INSERTINTO dbo.Customers(customerName, otherStuff)
SELECT a.namePart +N' '+ b.namePart,N'otherStuff'
FROM #firstNamePart a CROSSJOIN #secondNamePart b
GO
DROPTABLE #firstNamePart
DROPTABLE #secondNamePart
GO
-- populate the internetOrders and storeOrders tables:
DECLARE @customerID INT -- as we go through
DECLARE @orderTotal MONEY
DECLARE @orderDate DATETIME
DECLARE @numRecords SMALLINT
DECLARE @ct SMALLINT
DECLARE crs CURSORFORSELECT customerID from dbo.Customers
OPEN crs
FETCHNEXTFROM crs INTO @customerID
WHILE@@FETCH_STATUS= 0
BEGIN
-- internet orders
SET @numRecords =RAND()* 10000
SET @ct = 0
WHILE @ct < @numRecords
BEGIN
SET @orderTotal =RAND()* 10000
SET @orderDate =DATEADD(dd,RAND()* 1500,'2008-01-01 00:00:00.000')
INSERTINTO dbo.InternetOrders(customerID, orderTotal, orderDate, otherDetails)
VALUES (@customerID, @orderTotal, @orderDate,'Other Details')
SET @ct = @ct + 1
END
-- set up store orders
SET @numRecords =RAND()* 1000
SET @ct = 0
WHILE @ct < @numRecords
BEGIN
SET @orderTotal =RAND()* 10000
SET @orderDate =DATEADD(dd,RAND()* 1500,'2008-01-01 00:00:00.000')
INSERTINTO dbo.StoreOrders(customerID, orderTotal, orderDate, otherDetails)
VALUES (@customerID, @orderTotal, @orderDate,'Other Details')
SET @ct = @ct + 1
END
INSERTINTO dbo.SurveyResults(customerID, aggResults, otherDetails)
VALUES (@customerID, @customerID % 5,N'Other Details')
FETCHNEXTFROM crs INTO @customerID
END
CLOSE CRS
DEALLOCATE CRS
/*
Populate the quote tables with sample data by duplicating the sales data
Also populate TransactionType3 and TransactionType4
*/
INSERTINTO dbo.InternetQuotes(customerID, quoteDate, quoteTotal, otherDetails)
SELECT customerID, orderDate, orderTotal, otherDetails
FROM dbo.InternetOrders
INSERTINTO dbo.StoreQuotes(customerID, quoteDate, quoteTotal, otherDetails)
SELECT customerID, orderDate, orderTotal, otherDetails
FROM dbo.storeOrders
INSERTINTO dbo.TransactionType3(customerID, orderDate, orderTotal, otherDetails)
SELECT customerID, orderDate, orderTotal, otherDetails
FROM dbo.InternetOrders
INSERTINTO dbo.TransactionType4(customerID, orderDate, orderTotal, otherDetails)
SELECT customerID, orderDate, orderTotal, otherDetails
FROM dbo.storeOrders
INSERTINTO dbo.TransactionType5(customerID, orderDate, orderTotal, otherDetails)
SELECT customerID, orderDate, orderTotal, otherDetails
FROM dbo.InternetOrders
INSERTINTO dbo.TransactionType6(customerID, orderDate, orderTotal, otherDetails)
SELECT customerID, orderDate, orderTotal, otherDetails
FROM dbo.storeOrders
GO
/*
Populate SurveyDetails with sample data for 50 questions
*/
DECLARE @questionNbr TINYINT
DECLARE @surveyID INT
SET @questionNbr = 1
WHILE @questionNbr < 51
BEGIN
INSERTINTO dbo.SurveyDetails(surveyID, questionNbr, customerID, rating, surveyDate, verbatim)
SELECT 1, @questionNbr, customerID, customerID % 5,'2008-01-01',N'Feedback from the customer'
FROM dbo.Customers
INSERTINTO dbo.SurveyDetails(surveyID, questionNbr, customerID, rating, surveyDate, verbatim)
SELECT 2, @questionNbr, customerID, customerID % 5,'2008-01-01',N'Feedback from the customer'
FROM dbo.Customers
SET @questionNbr = @questionNbr + 1
END
GO
/*
Update all statistics to be sure they are all in the best possible shape
*/
UPDATESTATISTICS dbo.Customers WITHFULLSCAN
UPDATESTATISTICS dbo.InternetOrders WITHFULLSCAN
UPDATESTATISTICS dbo.storeOrders WITHFULLSCAN
UPDATESTATISTICS dbo.InternetQuotes WITHFULLSCAN
UPDATESTATISTICS dbo.StoreQuotes WITHFULLSCAN
UPDATESTATISTICS dbo.TransactionType3 WITHFULLSCAN
UPDATESTATISTICS dbo.TransactionType4 WITHFULLSCAN
UPDATESTATISTICS dbo.TransactionType5 WITHFULLSCAN
UPDATESTATISTICS dbo.TransactionType6 WITHFULLSCAN
UPDATESTATISTICS dbo.SurveyResults WITHFULLSCAN
Appendix D: Aggregation Example Queries
The full query, Query 1, retrieves the results in one step. The second query retrieves the results by using a temporary table as an intermediate stage for the data. This allows for statistics to be calculated on the intermediate result set and allows for a recompile to select the best strategy for joining to obtain the final result set.
Query 1
SELECT T1.customerName, R.ContactID, R.AggResults
, D.surveyId, D.questionNbr, D.rating, D.verbatim
FROM
(
SELECT Tab1.customerID, Tab1.customerName, Tab1.StoreOrderTotal, Tab1.InternetOrderTotal
, Tab1.TotalOrders, Tab2.InternetQuoteTotal, Tab2.StoreQuoteTotal, Tab2.TotalQuote
FROM
(
SELECT A.customerID, a.customerName, a.orderTotal as InternetOrderTotal, b.orderTotal as StoreOrderTotal,
TotalOrders = a.orderTotal + b.orderTotal
FROM
(
SELECT c.customerID, c.customerName,
SUM(i.orderTotal)as orderTotal
FROM dbo.Customers c JOIN dbo.InternetOrders i ON c.customerID = i.customerID
WHERE i.orderDate BETWEEN'2010-01-01'and'2010-12-31 23:59:59.999'
GROUPBY c.customerID, c.customerName
HAVINGSUM(i.orderTotal)> 10000.00
) A
JOIN
(
SELECT c.customerID, c.customerName,
SUM(s.orderTotal)as orderTotal
FROM dbo.Customers c JOIN dbo.StoreOrders s ON c.customerID = s.customerID
WHERE s.orderDate BETWEEN'2010-01-01'and'2010-12-31 23:59:59.999'
GROUPBY c.customerID, c.customerName
HAVINGSUM(s.orderTotal)> 10000.00
) B on A.customerID = B.customerID
WHERE a.orderTotal + b.orderTotal > 100000.00
) Tab1 JOIN
(
SELECT A.customerID, a.customerName, a.quoteTotal as InternetQuoteTotal, b.quoteTotal as StoreQuoteTotal,
TotalQuote = a.quoteTotal + b.quoteTotal
FROM
(
SELECT c.customerID, c.customerName,
SUM(i.quoteTotal)as quoteTotal
FROM dbo.Customers c JOIN dbo.InternetQuotes i ON c.customerID = i.customerID
WHERE i.quoteDate BETWEEN'2010-01-01'and'2010-12-31 23:59:59.999'
GROUPBY c.customerID, c.customerName
HAVINGSUM(i.quoteTotal)> 10000.00
) A
JOIN
(
SELECT c.customerID, c.customerName,
SUM(s.quoteTotal)as quoteTotal
FROM dbo.Customers c JOIN dbo.StoreQuotes s ON c.customerID = s.customerID
WHERE s.quoteDate BETWEEN'2010-01-01'and'2010-12-31 23:59:59.999'
GROUPBY c.customerID, c.customerName
HAVINGSUM(s.quoteTotal)> 10000.00
) B on A.customerID = B.customerID
WHERE a.quoteTotal + b.quoteTotal > 100000.00
) Tab2 ON Tab1.customerID = Tab2.customerID
) T1 JOIN
(
SELECT Tab1.customerID, Tab1.customerName, Tab1.StoreOrderTotal, Tab1.InternetOrderTotal
, Tab1.TotalOrders, Tab2.InternetQuoteTotal, Tab2.StoreQuoteTotal, Tab2.TotalQuote
FROM
(
SELECT A.customerID, a.customerName, a.orderTotal as InternetOrderTotal, b.orderTotal as StoreOrderTotal,
TotalOrders = a.orderTotal + b.orderTotal
FROM
(
SELECT c.customerID, c.customerName,
SUM(i.orderTotal)as orderTotal
FROM dbo.Customers c JOIN dbo.TransactionType3 i ON c.customerID = i.customerID
WHERE i.orderDate BETWEEN'2010-01-01'and'2010-12-31 23:59:59.999'
GROUPBY c.customerID, c.customerName
HAVINGSUM(i.orderTotal)> 10000.00
) A
JOIN
(
SELECT c.customerID, c.customerName,
SUM(s.orderTotal)as orderTotal
FROM dbo.Customers c JOIN dbo.TransactionType4 s ON c.customerID = s.customerID
WHERE s.orderDate BETWEEN'2010-01-01'and'2010-12-31 23:59:59.999'
GROUPBY c.customerID, c.customerName
HAVINGSUM(s.orderTotal)> 10000.00
) B on A.customerID = B.customerID
WHERE a.orderTotal + b.orderTotal > 100000.00
) Tab1 JOIN
(
SELECT A.customerID, a.customerName, a.quoteTotal as InternetQuoteTotal, b.quoteTotal as StoreQuoteTotal,
TotalQuote = a.quoteTotal + b.quoteTotal
FROM
(
SELECT c.customerID, c.customerName,
SUM(i.orderTotal)as quoteTotal
FROM dbo.Customers c JOIN dbo.TransactionType5 i ON c.customerID = i.customerID
WHERE i.orderDate BETWEEN'2010-01-01'and'2010-12-31 23:59:59.999'
GROUPBY c.customerID, c.customerName
HAVINGSUM(i.orderTotal)> 10000.00
) A
JOIN
(
SELECT c.customerID, c.customerName,
SUM(s.orderTotal)as quoteTotal
FROM dbo.Customers c JOIN dbo.TransactionType6 s ON c.customerID = s.customerID
WHERE s.orderDate BETWEEN'2010-01-01'and'2010-12-31 23:59:59.999'
GROUPBY c.customerID, c.customerName
HAVINGSUM(s.orderTotal)> 10000.00
) B on A.customerID = B.customerID
WHERE a.quoteTotal + b.quoteTotal > 100000.00
) Tab2 ON Tab1.customerID = Tab2.customerID
) T2 ON T1.customerID = T2.customerID
LEFTOUTERJOIN dbo.SurveyResults R on T1.customerID = R.customerID
LEFTOUTERJOIN dbo.SurveyDetails D on T1.customerID = D.customerID
WHERE T1.TotalOrders > 10000.00 AND T2.TotalQuote > 100000.00
Query 2
SELECT T1.customerID, T1.customerName
INTO #temp
FROM
(
SELECT Tab1.customerID, Tab1.customerName, Tab1.StoreOrderTotal, Tab1.InternetOrderTotal
, Tab1.TotalOrders, Tab2.InternetQuoteTotal, Tab2.StoreQuoteTotal, Tab2.TotalQuote
FROM
(
SELECT A.customerID, a.customerName, a.orderTotal as InternetOrderTotal, b.orderTotal as StoreOrderTotal,
TotalOrders = a.orderTotal + b.orderTotal
FROM
(
SELECT c.customerID, c.customerName,
SUM(i.orderTotal)as orderTotal
FROM dbo.Customers c JOIN dbo.InternetOrders i ON c.customerID = i.customerID
WHERE i.orderDate BETWEEN'2010-01-01'and'2010-12-31 23:59:59.999'
GROUPBY c.customerID, c.customerName
HAVINGSUM(i.orderTotal)> 10000.00
) A
JOIN
(
SELECT c.customerID, c.customerName,
SUM(s.orderTotal)as orderTotal
FROM dbo.Customers c JOIN dbo.StoreOrders s ON c.customerID = s.customerID
WHERE s.orderDate BETWEEN'2010-01-01'and'2010-12-31 23:59:59.999'
GROUPBY c.customerID, c.customerName
HAVINGSUM(s.orderTotal)> 10000.00
) B on A.customerID = B.customerID
WHERE a.orderTotal + b.orderTotal > 100000.00
) Tab1 JOIN
(
SELECT A.customerID, a.customerName, a.quoteTotal as InternetQuoteTotal, b.quoteTotal as StoreQuoteTotal,
TotalQuote = a.quoteTotal + b.quoteTotal
FROM
(
SELECT c.customerID, c.customerName,
SUM(i.quoteTotal)as quoteTotal
FROM dbo.Customers c JOIN dbo.InternetQuotes i ON c.customerID = i.customerID
WHERE i.quoteDate BETWEEN'2010-01-01'and'2010-12-31 23:59:59.999'
GROUPBY c.customerID, c.customerName
HAVINGSUM(i.quoteTotal)> 10000.00
) A
JOIN
(
SELECT c.customerID, c.customerName,
SUM(s.quoteTotal)as quoteTotal
FROM dbo.Customers c JOIN dbo.StoreQuotes s ON c.customerID = s.customerID
WHERE s.quoteDate BETWEEN'2010-01-01'and'2010-12-31 23:59:59.999'
GROUPBY c.customerID, c.customerName
HAVINGSUM(s.quoteTotal)> 10000.00
) B on A.customerID = B.customerID
WHERE a.quoteTotal + b.quoteTotal > 100000.00
) Tab2 ON Tab1.customerID = Tab2.customerID
) T1 JOIN
(
SELECT Tab1.customerID, Tab1.customerName, Tab1.StoreOrderTotal, Tab1.InternetOrderTotal
, Tab1.TotalOrders, Tab2.InternetQuoteTotal, Tab2.StoreQuoteTotal, Tab2.TotalQuote
FROM
(
SELECT A.customerID, a.customerName, a.orderTotal as InternetOrderTotal, b.orderTotal as StoreOrderTotal,
TotalOrders = a.orderTotal + b.orderTotal
FROM
(
SELECT c.customerID, c.customerName,
SUM(i.orderTotal)as orderTotal
FROM dbo.Customers c JOIN dbo.TransactionType3 i ON c.customerID = i.customerID
WHERE i.orderDate BETWEEN'2010-01-01'and'2010-12-31 23:59:59.999'
GROUPBY c.customerID, c.customerName
HAVINGSUM(i.orderTotal)> 10000.00
) A
JOIN
(
SELECT c.customerID, c.customerName,
SUM(s.orderTotal)as orderTotal
FROM dbo.Customers c JOIN dbo.TransactionType4 s ON c.customerID = s.customerID
WHERE s.orderDate BETWEEN'2010-01-01'and'2010-12-31 23:59:59.999'
GROUPBY c.customerID, c.customerName
HAVINGSUM(s.orderTotal)> 10000.00
) B on A.customerID = B.customerID
WHERE a.orderTotal + b.orderTotal > 100000.00
) Tab1 JOIN
(
SELECT A.customerID, a.customerName, a.quoteTotal as InternetQuoteTotal, b.quoteTotal as StoreQuoteTotal,
TotalQuote = a.quoteTotal + b.quoteTotal
FROM
(
SELECT c.customerID, c.customerName,
SUM(i.orderTotal)as quoteTotal
FROM dbo.Customers c JOIN dbo.TransactionType5 i ON c.customerID = i.customerID
WHERE i.orderDate BETWEEN'2010-01-01'and'2010-12-31 23:59:59.999'
GROUPBY c.customerID, c.customerName
HAVINGSUM(i.orderTotal)> 10000.00
) A
JOIN
(
SELECT c.customerID, c.customerName,
SUM(s.orderTotal)as quoteTotal
FROM dbo.Customers c JOIN dbo.TransactionType6 s ON c.customerID = s.customerID
WHERE s.orderDate BETWEEN'2010-01-01'and'2010-12-31 23:59:59.999'
GROUPBY c.customerID, c.customerName
HAVINGSUM(s.orderTotal)> 10000.00
) B on A.customerID = B.customerID
WHERE a.quoteTotal + b.quoteTotal > 100000.00
) Tab2 ON Tab1.customerID = Tab2.customerID
) T2 ON T1.customerID = T2.customerID
WHERE T1.TotalOrders > 10000.00 AND T2.TotalQuote > 100000.00
SELECT T1.customerName, R.ContactID, R.AggResults, D.surveyId, d.QuestionNbr, D.Rating, D.verbatim FROM #temp T1
LEFTOUTERJOIN dbo.SurveyResults R on T1.customerID = R.customerID
LEFTOUTERJOIN dbo.SurveyDetails D on T1.customerID = D.customerID
droptable #temp
Additional References
For more information, see the following references:
·
SET STATISTICS IO (Transact-SQL)
http://msdn.microsoft.com/en-us/library/ms184361.aspx?lc=1033
·
SET STATISTICS TIME (Transact-SQL)
http://msdn.microsoft.com/en-us/library/ms190287.aspx
·
Table and Index Organization
http://msdn.microsoft.com/en-us/library/ms189051.aspx
·
DBCC SHOW_STATISTICS (Transact-SQL)
http://msdn.microsoft.com/en-us/library/ms174384.aspx
·
Query Tuning Recommendations
http://msdn.microsoft.com/en-us/library/ms188722.aspx
·
Nested Loop Joins
http://msdn.microsoft.com/en-us/library/ms191318(v=SQL.105).aspx