
This post has been republished via RSS; it originally appeared at: Microsoft Research.
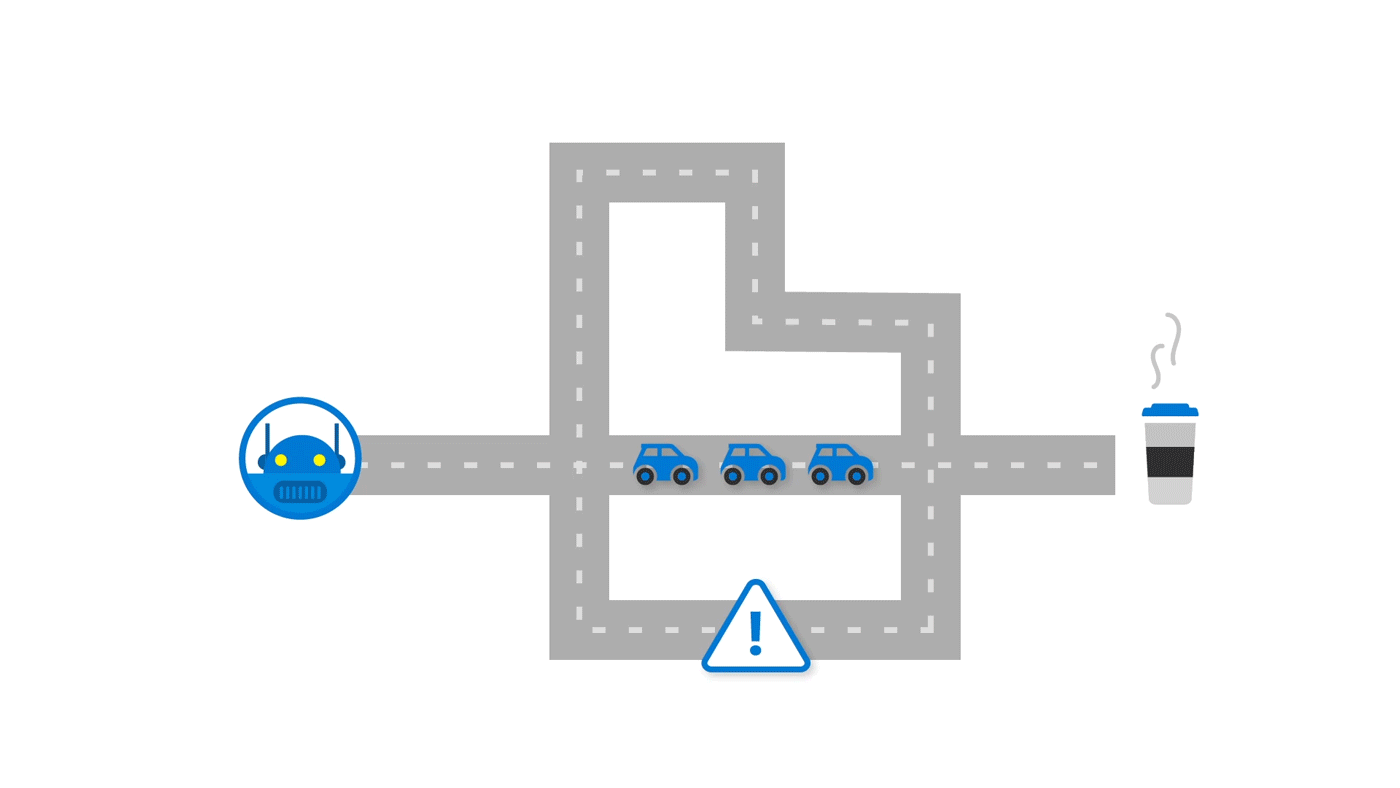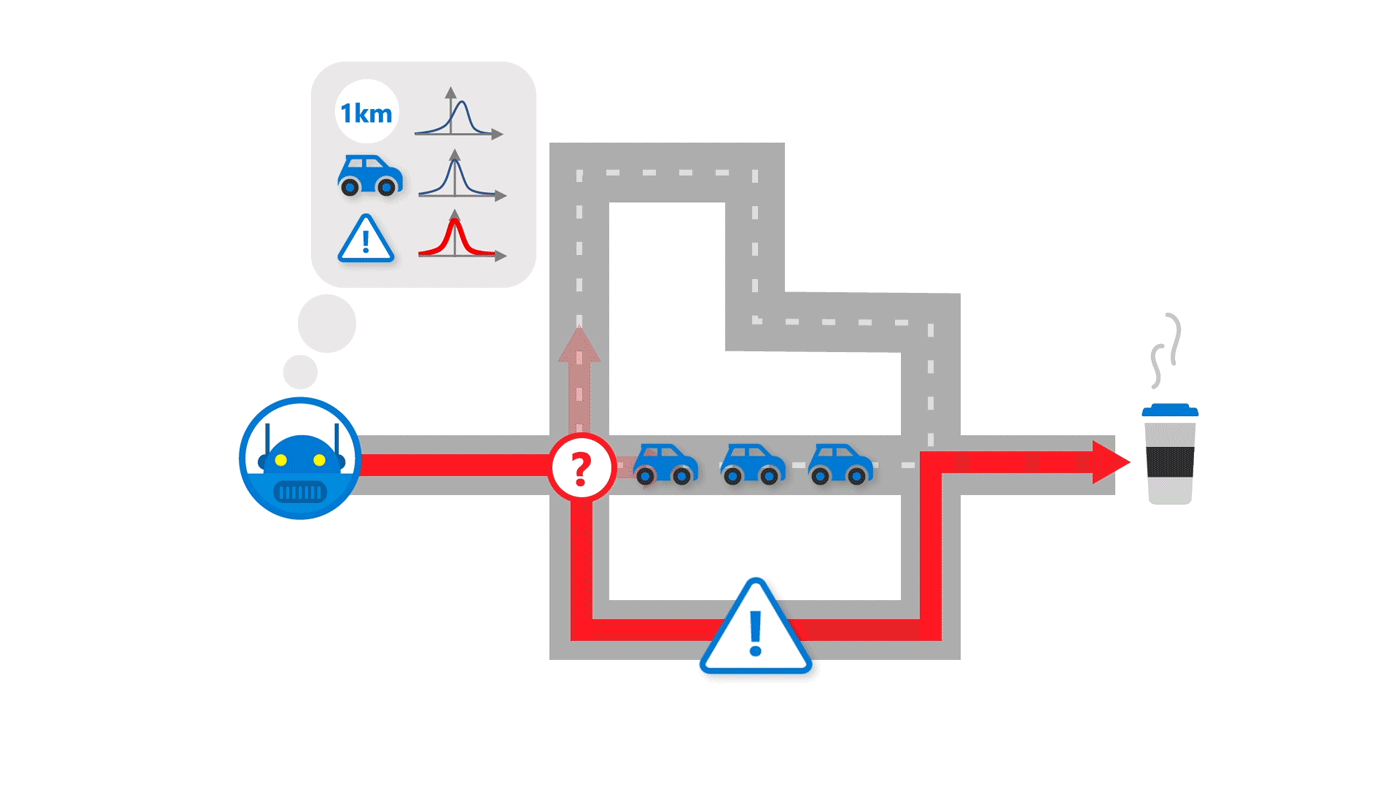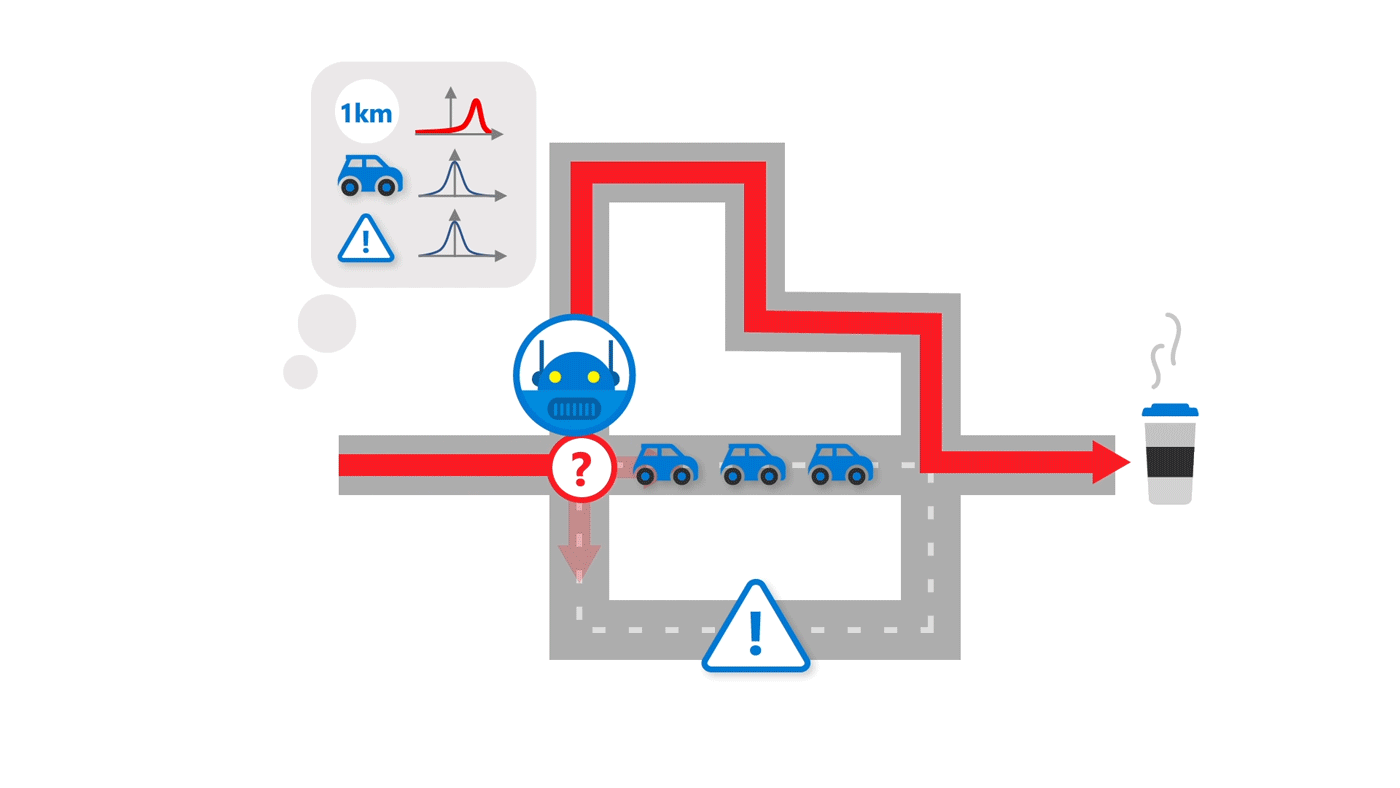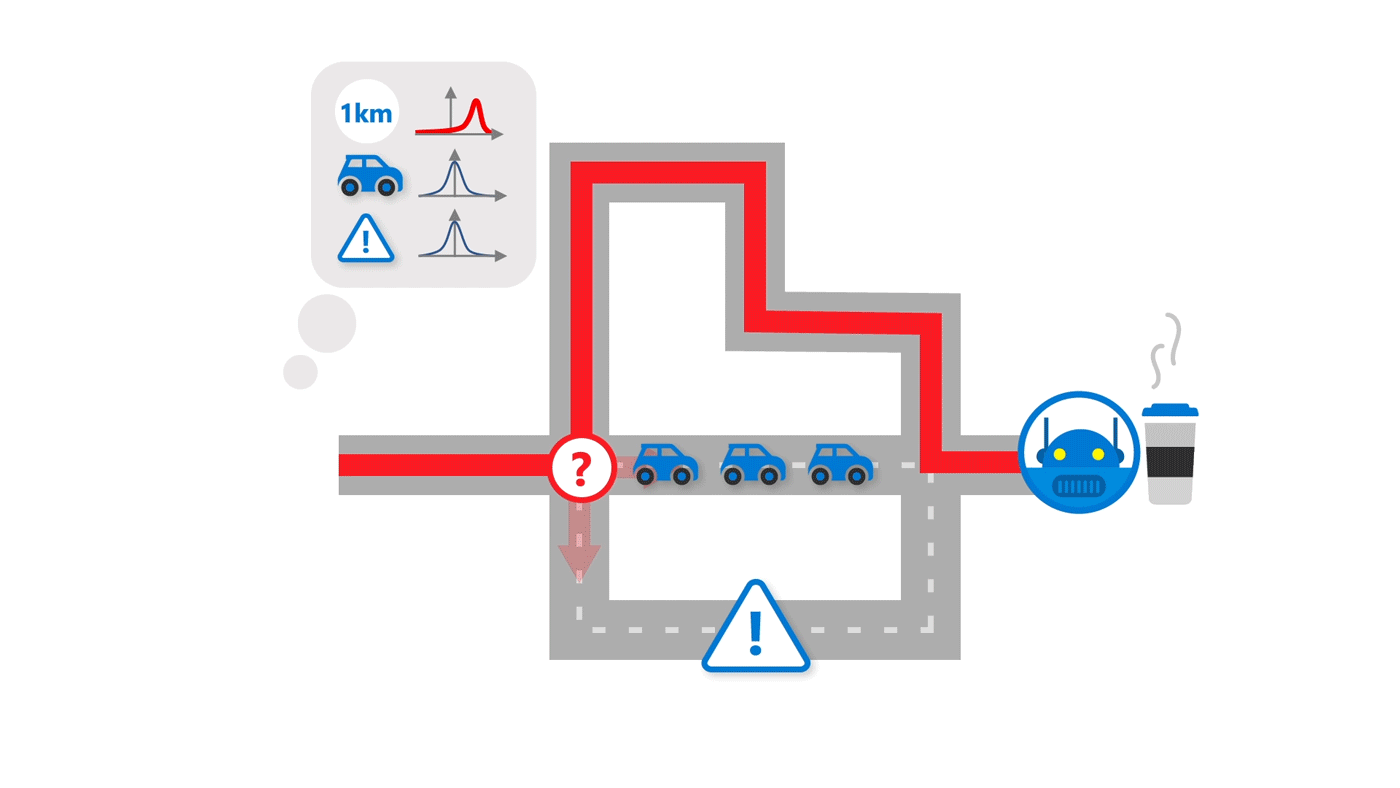
Imagine moving to a new city. You want to get from your new home to your new job. Unfamiliar with the area, you ask your co-workers for the best route, and as far as you can tell … they’re right! You get to work and back easily. But as you acclimate, you begin to wonder: Is there a more scenic route, perhaps, or a route that passes by a good coffee spot? The fundamental question then becomes do you stick with what you already know—a route largely without issues—or do you seek to learn more, potentially finding a better way. Rely on prior experience too much, and you miss out on a pretty drive or that much-needed quality cup of joe. Spend too much time investigating, and you risk delay, ruining a good thing. As humans, we learn to balance exploiting what we know and exploring what we don’t, an important skill researchers in reinforcement learning are trying to achieve when it comes to AI agents.
In our paper “Successor Uncertainties: Exploration and Uncertainty in Temporal Difference Learning,” which is being presented at the 33rd Conference on Neural Information Processing Systems (NeurIPS), we’ve taken a step toward enabling efficient exploration by proposing Successor Uncertainties (SU), a simple yet effective algorithm for implementing and achieving scalable model-free exploration with posterior sampling. SU is a randomized value function (RVF) algorithm, which means it directly models a posterior distribution over plausible state-action functions, allowing for deep exploration—that is, non-myopic exploration strategies. Compared with many other exploration schemes based on RVF and posterior sampling, SU is more effective in sparse reward environments, overcoming some theoretical shortcomings of previous approaches, and is cheaper computationally.
AI the explorer
An AI agent deployed in a new environment has to make a tradeoff between exploration—learning about behavior that leads to high cumulative rewards—and exploitation—leveraging knowledge about the environment that it has already acquired.
Simple exploration schemes like epsilon-greedy explore and learn new environments via minor, random modifications. In our example of commuting to work in a new city, that would be akin to taking a random couple of turns to go down a new street not too far off from the original route to see if there are any good coffee shops along that way. That approach isn’t as efficient, though, as let’s say taking a route in which you observe seven new streets and the types of businesses that exist there. The greater deviation allows you to obtain more information—information about seven never-before-seen streets—for future decision-making. This is referred to as deep exploration, and it requires an agent to take systematic actions over a longer time period. To do that, an AI agent has to consider what it doesn’t know and experiment with behavior that could be beneficial under its current knowledge. This can be formalized by an agent’s uncertainty about the cumulative reward it might achieve by following a certain behavior.
Considering the unknown
SU represents an agent’s uncertainty about the value of actions in a specific state of the environment and is constructed to satisfy posterior sampling policy matching, a property ensuring that acting greedily with respect to samples from SU leads to behavior consistent with the current agent’s knowledge of the transition frequencies and reward distribution. This enables the agent to focus its exploration on promising behavior.
Many previous methods using RVF and posterior sampling focus on propagation of uncertainty, which ensures that the agent’s uncertainties quantify not only the uncertainty about the immediate reward of an action, but also the uncertainty about the reward that could be achieved in the next step, the step after that, and so on. Based on these uncertainties, the agent can often efficiently experiment with behavior for which the long-term outcome is uncertain. Surprisingly, as we show in our paper, propagation of uncertainty does not guarantee efficient exploration via posterior sampling. While SU satisfies propagation of uncertainty, it also satisfies posterior sampling policy matching, making it explicitly focus on the exploration induced by the model through posterior sampling. In contrast with methods that only focus on propagation of uncertainty, SU performs well on sparse reward problems.
SU captures an agent’s uncertainty about achievable rewards by combining successor features, Bayesian linear regression, and neural network function approximation in a novel way to form expressive posterior distributions over state-action functions. Successor features enable us to estimate the expected features counts when following a particular behavior in a temporally consistent manner; Bayesian linear regression enables us to use those successor features to induce distributions over state-action functions; and function approximation makes our approach practical in challenging applications with large action spaces.

Successor Uncertainties was compared to several popular existing randomized value function methods on the Atari 2600 video games benchmark. The above bars show the difference in human normalized scores between SU and bootstrapped Deep Q-Networks (bootstrapped DQN; top), uncertainty Bellman equation (UBE; middle), and Deep Q-Networks (DQN; bottom) for each of the 49 Atari 2600 games. Blue indicates SU performed better; red indicates it performed worse. SU outperforms the baselines on 36/49, 43/49, and 42/49 games, respectively. Y-axis values have been clipped to [−2.5, 2.5].
Appealing theoretical properties and strong empirical performance
SU has appealing theoretical properties that translate into efficient exploration. This is demonstrated by remarkable performance on hard tabular exploration problems. SU also easily scales to real-world applications with large state spaces such as video games, in which we have to perform exploration purely from visual frames and in which reward signals can be very sparse. In particular, we demonstrate strong empirical performance on the benchmark of Atari 2600 video games.
SU is easy to implement within existing model-free reinforcement learning pipelines, and because exploring is more efficient with SU, reinforcement learning becomes more data efficient.
Our work on Successor Uncertainties is part of a larger body of research called Game Intelligence, which is geared toward developing algorithms for enabling new game experiences driven by intelligent agents. Game environments such as Minecraft, which has been unlocked for AI experimentation through our Project Malmo platform, are fantastic places to develop agents that can collaborate with players. Our long-term goal is to create such collaborative and socially aware game agents as a stepping stone toward better AI assistants. This work, and understanding how agents can explore more meaningfully and learn faster, is key in that endeavor.
The SU source code is available online, and we encourage you to give SU a try when tackling your next reinforcement learning problem.
The post The road less traveled: With Successor Uncertainties, RL agents become better informed explorers appeared first on Microsoft Research.