
This post has been republished via RSS; it originally appeared at: Microsoft Research.

As artificial intelligence continues its rapid progress, equaling or surpassing human performance on benchmarks in an increasing range of tasks, researchers in the field are directing more effort to the interaction between humans and AI in domains where both are active. Chess stands as a model system for studying how people can collaborate with AI, or learn from AI, just as chess has served as a leading indicator of many central questions in AI throughout the field’s history.
AI-powered chess engines have consistently bested human players since 2005, and the chess world has undergone further shifts since then, such as the introduction of the heuristics-based Stockfish engine in 2008 and the deep reinforcement learning-based AlphaZero engine in 2017. The impact of this evolution has been monumental: chess is now seeing record numbers of people playing the game even as AI itself continues to get better at playing. These shifts have created a unique testbed for studying the interactions between humans and AI: formidable AI chess-playing ability combined with a large, growing human interest in the game has resulted in a wide variety of playing styles and player skill levels.
There’s a lot of work out there that attempts to match AI chess play to varying human skill levels, but the result is often AI that makes decisions and plays moves differently than human players at that skill level. The goal for our research is to better bridge the gap between AI and human chess-playing abilities. The question for AI and its ability to learn is: can AI make the same fine-grained decisions that humans do at a specific skill level? This is a good starting point for aligning AI with human behavior in chess.
Our team of researchers at the University of Toronto, Microsoft Research, and Cornell University has begun investigating how to better match AI to different human skill levels and, beyond that, personalize an AI model to a specific player’s playing style. Our work comprises two papers, “Aligning Superhuman AI with Human Behavior: Chess as a Model System” and “Learning Personalized Behaviors of Human Behavior in Chess,” as well as a novel chess engine, called Maia, which is trained on games played by humans to more closely match human play. Our results show that, in fact, human decisions at different levels of skill can be predicted by AI, even at the individual level. This represents a step forward in modeling human decisions in chess, opening new possibilities for collaboration and learning between humans and AI.
AlphaZero changed how AI played the game by practicing against itself with only knowledge of the rules (“self-play”), unlike previous models that relied heavily on libraries of moves and past games to inform training. Our model, Maia, is a customized version of Leela Chess Zero (an open-source implementation of AlphaZero). We trained Maia on human games with the goal of playing the most human-like moves, instead of being trained on self-play games with the goal of playing the optimal moves. In order to characterize human chess-playing at different skill levels, we developed a suite of nine Maias, one for each Elo rating between 1100 and 1900. (Elo ratings are a system for evaluating players’ relative skill in games like chess.) As you’ll see below, Maia matches human play more closely than any chess engine ever created.
- CODE Maia Chess Explore our nine final maia models saved as Leela Chess neural networks, and the code to create more and reproduce our results.
If you’re curious, you can play against a few versions of Maia on Lichess, the popular open-source online chess platform. Our bots on Lichess are named maia1, maia5, and maia9, which we trained on human games at Elo rating 1100, 1500, and 1900, respectively. You can also download these bots and other resources from the GitHub repo.
Measuring human play
What does it mean for a chess engine to match human play? For our purposes, we settled on a simple metric: given a position that occurred in an actual human game, what is the probability that the engine plays the move that the human played in the game?
Making an engine that matches human play according to this definition is a difficult task. The vast majority of positions seen in real games only happen once, because the sheer number of possible positions is astronomical: after just four moves by each player, the number of potential positions enters the hundreds of billions. Moreover, people have a wide variety of styles, even at the same rough skill level. And even the same exact person might make a different move if they see the same position twice!
Creating a dataset
To rigorously compare engines in how well they match human play, we need a good test set to evaluate them with. We made a collection of nine test sets, one for each narrow rating range. Here’s how we made them:
- First, we made rating bins for each range of 100 rating points (such as 1200-1299, 1300-1399, and so on).
- In each bin, we put all games where both players are in the same rating range.
- We drew 10,000 games from each bin, ignoring games played at Bullet and HyperBullet speeds. At those speeds (one minute or less per player), players tend to play lower quality moves to not lose by running out of time.
- Within each game, we discarded the first 10 moves made by each player to ignore most memorized opening moves.
- We also discarded any move where the player had less than 30 seconds to complete the rest of the game (to avoid situations where players are making random moves).
After these restrictions we had nine test sets, one for each rating range, which contained roughly 500,000 positions each.

Microsoft research webinars
Differentiating our work from prior attempts
People have been trying to create chess engines that accurately match human play for decades. For one thing, they would make great sparring partners. But getting crushed like a bug every single game isn’t that fun, so the most popular attempts at engines that match human play have been some kind of attenuated version of a strong chess engine. Attenuated versions of an engine are created by limiting the engine’s ability in some way, such as reducing the amount of data it’s trained on or limiting how deeply it searches to find a move. For example, the “play with the computer” feature on Lichess is a series of Stockfish models that are limited in the number of moves they are allowed to look ahead. Chess.com, ICC, FICS, and other platforms all have similar engines. How well do these engines match human play?
Stockfish: We created several attenuated versions of Stockfish, one for each depth limit (for example, the depth 3 Stockfish can only look 3 moves ahead), and then we tested them on our test sets. In the plot below, we break out the accuracies by rating level so you can see if the engine thinks more like players of a specific skill level.
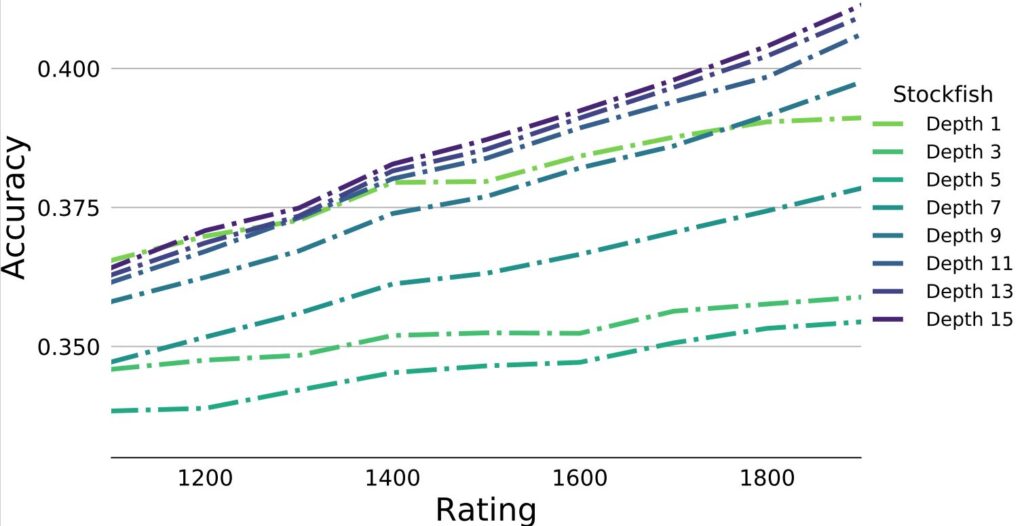
As you can see, it doesn’t work that well. Attenuated versions of Stockfish only match human moves about 35-40% of the time. And equally importantly, each curve is strictly increasing, meaning that even depth-1 Stockfish does a better job at matching 1900-rated human moves than it does at matching 1100-rated human moves. This means that attenuating Stockfish by restricting the depth it can search doesn’t capture human play at lower skill levels—instead, it looks like it’s playing regular Stockfish chess with a lot of noise mixed in.
Leela Chess Zero: Attenuating Stockfish doesn’t characterize human play at specific levels. What about Leela Chess Zero, an open-source implementation of AlphaZero, which learns chess through self-play games and deep reinforcement learning? Unlike Stockfish, Leela incorporates no human knowledge in its design. Despite this, however, the chess community was very excited by how Leela seemed to play more like human players.
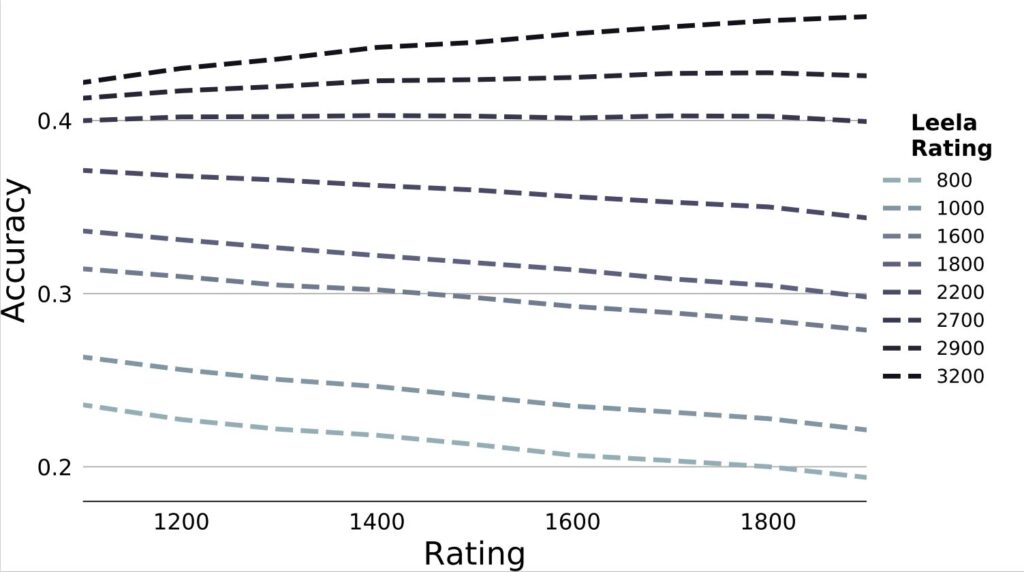
In the analysis above, we looked at a number of different Leela generations, with the ratings being their relative skill (commentators noted that early Leela generations played particularly similar to humans). People were right in that the best versions of Leela match human moves more often than Stockfish. But Leela still doesn’t capture human play at different skill levels: each version is always getting better or always getting worse as the human skill level increases. To characterize human play at a particular level, we need another approach.
Maia: A better solution for matching human skill levels
Maia is an engine designed to play like humans at a particular skill level. To achieve this, we adapted the AlphaZero/Leela Chess framework to learn from human games. We created nine different versions, one for each rating range from 1100-1199 to 1900-1999. We made nine training datasets in the same way that we made the test datasets (described above), with each training set containing 12 million games. We then trained a separate Maia model for each rating bin to create our nine Maias, from Maia 1100 to Maia 1900.
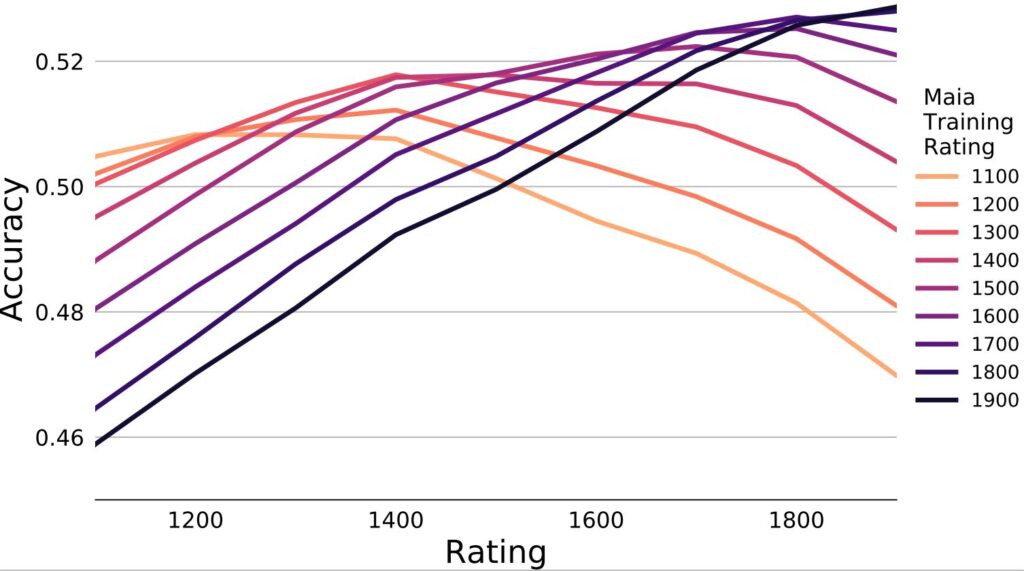
As you can see, the Maia results are qualitatively different from Stockfish and Leela. First off, the move matching performance is much higher: Maia’s lowest accuracy, when it is trained on 1900-rated players but predicts moves made by 1100-rated players, is 46%—as high as the best performance achieved by any Stockfish or Leela model on any human skill level we tested. Maia’s highest accuracy is over 52%. Over half the time, Maia 1900 predicts the exact move a 1900-rated human played in an actual game.
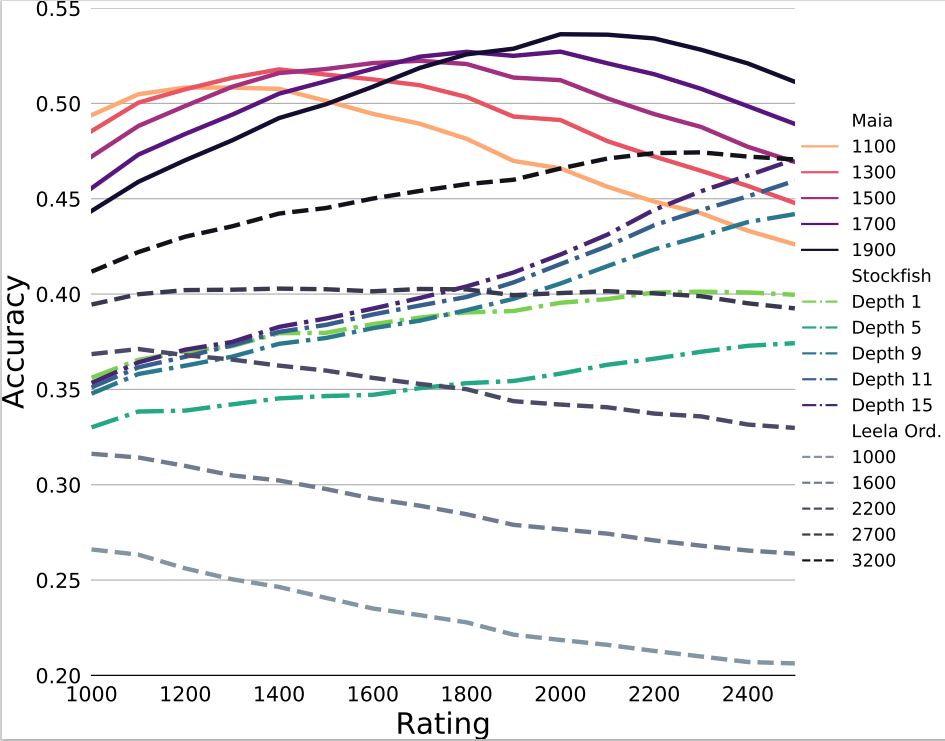
Importantly, every version of Maia uniquely captures a specific human skill level since every curve achieves its maximum accuracy at a different human rating. Even Maia 1100 achieves over 50% accuracy in predicting 1100-rated moves, and it’s much better at predicting 1100-rated players than 1900-rated players!
This means something deep about chess: there is such a thing as “1100-rated style.” And furthermore, it can be captured by a machine learning model. This was surprising to us: it would have been possible that human play is a mixture of good moves and random blunders, with 1100-rated players blundering more often and 1900-rated players blundering less often. Then it would have been impossible to capture 1100-rated style, because random blunders are impossible to predict. But since we can predict human play at different levels, there is a reliable, predictable, and maybe even algorithmically teachable difference between one human skill level and the next.
Maia’s predictions
You can find all of the juicy details in the paper, but one of the most exciting things about Maia is that it can predict mistakes. Even when a human makes an absolute howler—“hanging” a queen, in other words letting an opponent capture it for free, for example—Maia predicts the exact mistake made more than 25% of the time. This could be really valuable for average players trying to improve their game: Maia could look at your games and tell which blunders were predictable and which were random mistakes. If your mistakes are predictable, you know what to work on to hit the next level.
Modeling individual players’ styles with Maia
In current work, we are pushing the modeling of human play to the next level: can we actually predict the moves a particular human player would make?
It turns out that personalizing Maia gives us our biggest performance gains. Whereas base Maia predicts human moves around 50% of the time, some personalized models can predict an individual’s moves with accuracies up to 75%!
We achieve these results by fine-tuning Maia. Starting with a base Maia, say Maia 1900, we update the model by continuing training on an individual player’s games. Below, you can see that for predicting individual players’ moves, the personalized models all show large improvements over the non-personalized models. The gains are so large that the personalized models are almost non-overlapping with the non-personalized ones: the personalized model for the hardest-to-predict player still gets almost 60% accuracy, whereas even the non-personalized models don’t achieve this accuracy on even the easiest-to-predict players.
The personalized models are so accurate that given just a few games, we can tell which player played them! In this stylometry task—where the goal is to recognize an individual’s playing style—we train personalized models for 400 players of varying skill levels, and then have each model predict the moves from 4 games by each player. For 96% of the 4-game sets we tested, the personalized model that achieved the highest accuracy (that is, predicted the player’s actual moves most often) was the one that was trained on the player who played the games. With only 4 games of data, we can pick out who played the games from a set of 400 players. The personalized models are capturing individual chess-playing style in a highly accurate way.
Using AI to help improve human chess play
We designed Maia to be a chess engine that predicts human moves at a particular skill level, and it has progressed into a personalized engine that can identify the games of individual players. This is an exciting step forward in our understanding of human chess play, and it brings us closer to our goal of creating AI chess-teaching tools that help humans improve. Among the many capabilities of a good chess teacher, two of them are understanding how students at different skill levels play and recognizing the playing styles of their students. Maia has shown that these capabilities are realizable using AI.
The ability to create personalized chess engines from publicly available, individual player data opens an interesting discussion on the possible uses (and misuses) of this technology. We initiate this discussion in our papers, but there is a long road ahead in understanding the full potential and implications of this line of research. As in countless times before, Chess will be one model AI system that sets the stage for this discussion.
Acknowledgments
Many thanks to Lichess.org for providing the human games that we trained on, and hosting our Maia models that you can play against. Ashton Anderson was supported in part by an NSERC grant, a Microsoft Research gift, and a CFI grant. Jon Kleinberg was supported in part by a Simons Investigator Award, a Vannevar Bush Faculty Fellowship, a MURI grant, and a MacArthur Foundation grant.
The post The human side of AI for chess appeared first on Microsoft Research.