
This post has been republished via RSS; it originally appeared at: Microsoft Research.
The increasing use of personal assistants and messaging applications has spurred interest in building task-oriented dialog systems (or task bots) that can communicate with users through natural language to accomplish a wide range of tasks, such as restaurant booking, weather query, flight booking, or IT helpdesk support. The wide variety of tasks and domains has created the need for a flexible task-oriented dialog development platform that can support many different use cases while remaining straightforward for developers to use and maintain.
Most popular commercial tools for dialog development employ modular systems. They are designed mainly to help develop systems manually, that is, by writing code, crafting rules and making templates. Unfortunately, even with these tools, building dialog systems remains a label-intensive, time-consuming task, requiring rich domain knowledge, reasonable coding skill, and expert experience. The cost of building dialog systems at scale can be prohibitively expensive, with some production systems hosting as many as a thousand bots to serve a myriad of skills.
In this blog post, we introduce SOLOIST (TaSk-Oriented DiaLOg wIth A Single Pre-Trained Model) to enable building task bots at scale with transfer learning and machine teaching. The technology uses a single neural auto-regressive model and learns to ground its responses in user goals and real-world knowledge to achieve state-of-the-art performance on well-established dialog tasks. This marks the beginning of a shift in developing task-oriented dialog bots, from a task-by-task modular approach to pretraining a large dialog model followed by fine-tuning for specific tasks.
- CODE & DATASET SOLOIST
Microsoft has released the SOLOIST model and the source code to the public. For further details please refer to the research paper, “SOLOIST: Building Task Bots at Scale with Transfer Learning and Machine Teaching,” and check out the code on the GitHub repository. In addition, SOLOIST is being integrated into the Microsoft Power Virtual Agents (PVA), empowering dialog authors to easily build intelligent chatbots for a wide range of dialog tasks.
An auto-aggressive model for end-to-end dialog systems
![(a) A typical task-oriented dialog system pipeline. Top row has 6 mustard squares, and bottom row show arrows between four numbered processes. The first two read “dialog history” and “intent & slot” and correspond with 1) natural language understanding NLU. The next reads “belief state” and corresponds with 2) Dialog State Tracking DST. “DB state” corresponds with Dialog Policy Learning POL. “Dialog act” and “response” correspond with 4) Natural language generation.
(b) Example snippets for the items compounding the input of SOLOIST model. Highlights four categories from (a). Dialog history: User says “I would like to find an expensive restaurant that serves Chinese food.” System says “Sure, which area do you prefer?” Users says “How about in the north part of town.” Belief state: Restaurant { pricerange = expensive, food = Chinese, area = north } DB Stat: Restaurant 1 match. Response Delexicalized Response: The [restaurant_name] is great [value_food] restaurant. Would you like to book a table there? System response: The Peony Kitchen is a great Chinese food restaurant. Would you like to book a table there?
(c) The proposed SOLOIST model architecture and training objectives. Dialog history, Belief state, DB state, and Response make up the pipeline. Task 1, belief state prediction, corresponds with belief state. Task 2 and Task 3, grounded response generation and contrastive objective correspond with response. A user is shown thinking a goal, which points from the dialog history to the user (response), and then back to dialog history (input). Belief state points down to an image of a computer server (Belief state query) and then back to DB State (DB state results). The server points to readouts labeled “entity.”](https://www.microsoft.com/en-us/research/uploads/prod/2021/06/Figure-1_SOLOIST_Updatedwithcap.jpg)
The modular dialog system in Figure 1 (a) constitutes a data processing pipeline that produces a sequence, through concatenating the input-output pair of each module along the generation process. Each consecutive pair in this sequence plays the role of annotated data for the corresponding module. Ideally, when the entire sequence is available, the data generation process of a dialog system (that is, natural language understanding, dialog state tracking, policy, natural language generation) can be formulated as a single auto-regressive model. As is shown in Figure 1 (c), SOLOIST is designed to achieve this ideal.
SOLOIST is a stateful decision-making model for task completion, with the capabilities of tracking dialog states, selecting best system actions, and so on. Thus, SOLOIST is pretrained using task-oriented dialog sessions annotated with grounding information, that is, user goals, dialog belief states, database (DB) states, and system responses.
This lies in contrast to the state-of-the-art auto-regressive language model, GPT-2, although there are similarities. SOLOIST inherits GPT-2’s capability for producing human-like responses. While GPT-2 lacks grounding to generate responses useful for completing specific tasks, SOLOIST goes beyond responding to people with realistic and coherent responses on topics of their choosing—it is pretrained to generate responses grounded in user goals and real-world knowledge for task completion.
Specifically, each dialog turn in our training data is represented in SOLOIST as:
\(x=(s,b,c,r)\)
Where \(s\) is the dialog history up to the current dialog turn, \(b\) is the dialog belief state acquired from human annotation, \(c\) is the DB state automatically retrieved from a database using \(b\), and \(r\) is the delexicalized dialog response, from which the system response in natural language can be generated using some automatic post-processing. Each item in \(x\) is by itself a sequence of tokens, as illustrated by the examples in Figure 1 (b). Thus, it is natural to treat the concatenation of them as a long sequence for model training, shown in Figure 1 (c).
Leveraging pretraining, fine-tuning, and machine teaching to improve real-world performance
SOLOIST learns through three stages. These stages include:
- Language model pretraining. SOLOIST pretrains on large-scale web text data to gain the capability of responding more conversationally. We leverage off-the-shelf pretrained language models like GPT-2.
- Task-grounded pretraining. SOLOIST pretrains on publicly available heterogeneous dialog corpora with labels of belief states and DB states. We use a multi-task objective for learning parameters. Tasks include Belief Prediction, Grounded Response Generation, and Contrastive Objectives. These contain three types of negative samples: negative belief, where only the belief state item is replaced; negative response, where only the response item is replaced; and negative belief plus response, where both the belief state and response items are replaced. See Figure 1 (c).
- Fine-tuning and machine teaching. When deploying SOLOIST to a new task, we collect task-specific \(x\) in the same format as that used for pretraining. When \(x\) is available, the conventional fine-tuning procedure is utilized—we use the same multi-task objective to adapt the model to complete the new task using labeled task-specific dialogs.
Spotlight: Academic programs

Working with the academic community
Using machine teaching in the final stage has a number of advantages. In real applications, annotated task-specific data is often unavailable, noisy, or incomplete beforehand. One may deploy the dialog system and acquire high-quality task-specific labels (for example, belief state and system response) for each dialog turn using machine teaching.
Machine teaching is an active learning paradigm that focuses on leveraging the knowledge and expertise of domain experts as “teachers.” This paradigm puts a strong emphasis on tools and techniques that enable teachers—particularly non-data scientists and non-machine-learning experts—to visualize data, find potential problems, and provide corrections or additional training inputs to improve the system’s performance.
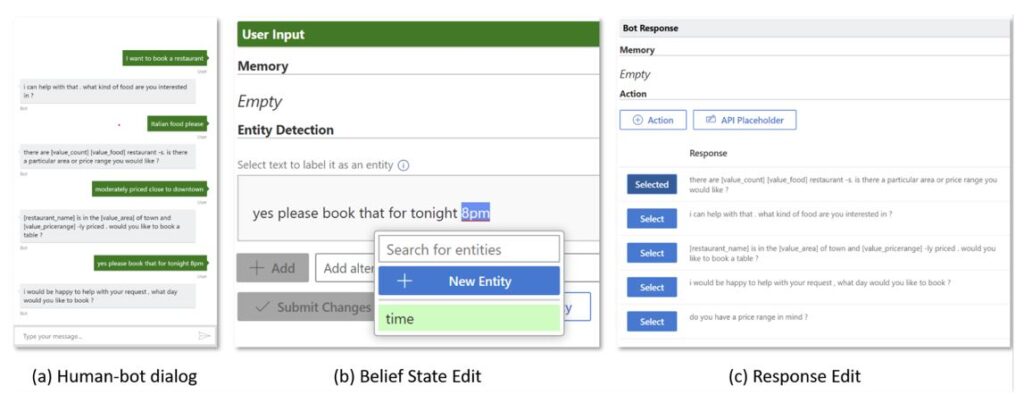
Fine-tuning is completed using Conversation Learner (CL), a machine teaching tool, in the following steps:
- Dialog authors deploy the pretrained SOLOIST model for a specific task
- Users (or human subjects recruited for system fine-tuning) interact with the system and generate human-bot dialog logs.
- Dialog authors revise a dozen training samples by selecting representative failed dialogs from the logs, correcting their belief and/or responses so that the system can complete these dialogs successfully, as illustrated in Figure 2. The corrected task-specific dialog turns are used to fine-tune the model. This video clip below demonstrates the complete process.
Finally, our SOLOIST model is pretrained on a large-scale homogenous dialog corpus including approximately one million examples with belief state annotation.
State-of-the-art performance
The empirical study for SOLOIST is based on performance on the MultiWOZ dataset, Banking77, and Restaurant8k. The competitive state-of-the-art methods are a collection from Sequicity, Domain Aware Multi-Decoder (DAMD), HRED-TS, and Structured Fusion. Inform, Success, and BLEU scores are reported. The first two metrics relate to the dialogue task completion—whether the system has provided an appropriate entity (Inform) and then answered all the requested attributes (Success). BLEU evaluates how natural the generated responses are compared to that generated by human agents. A combined score (Combined) is also reported using Combined = (Inform + Success) * 0.5 + BLEU as an overall quality measure.
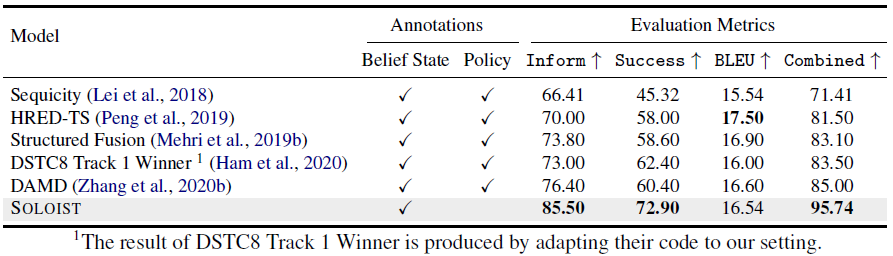
End-to-end evaluation. The result is shown in Table 1. SOLOIST achieves the best performance in terms of Inform, Success, and Combined, lifting the previous state of the art by a significant margin (about a 10-point improvement in Combined over DAMD). SOLOIST also outperforms the method of DSTC8 Track 1 Winner, where GPT-2 is fine-tuned and applied for end-to-end dialog modeling. Compared to the classical modular dialog systems (such as DAMD), SOLOIST uses a much simpler architecture and requires much lower labeling effort.

Few-shot fine-tuning evaluation. It is desirable for task bots to effectively generalize to new tasks with few task-specific training samples. Thus, the few-shot fine-tuning setting is a more realistic setting for evaluating dialog systems. We sample the dialog tasks that contain only one domain from the MultiWOZ dataset. Attraction, Train, Hotel, and Restaurant domains are used. For each domain, we randomly sample 50 dialog sessions for training and validation and 200 dialog sessions for testing. The result is listed in Table 2.
On all the domains, SOLOIST obtains substantially better performance in all the metrics. Removing task-grounded pretraining significantly hurts the performance of SOLOIST, although SOLOIST without task-grounded pretraining still consistently outperforms DAMD in all the domains. The result verifies the importance of task-grounded pretraining on annotated dialog corpora, allowing SOLOIST to learn how to track dialog and database states to accomplish a task.

SOLOIST plus Teach indicates continual training with five dialogs recommended by CL with human teacher corrections. SOLOIST plus Extra indicates continual training using five randomly sampled dialogs with full annotations.
Machine teaching results. We first sample 10 dialogs from each domain to fine-tune SOLOIST. The result is presented in the first row of Table 3. We then deploy the model to interact with human users via CL. The third row of Table 3 shows the result of machine teaching, where a human teacher has manually corrected five dialogs, which are recommended by CL using a ranking heuristic based on perplexity. The corrections are utilized to continually fine-tune the deployed system.
Table 3 shows that SOLOIST plus Teach consistently improves Combined by a large margin compared with that without human teaching. SOLOIST plus Extra is used as an ablation baseline, where five randomly selected dialogs with full annotations from experts are added as extra examples to fine-tune the model. This shows lower performance than machine teaching.
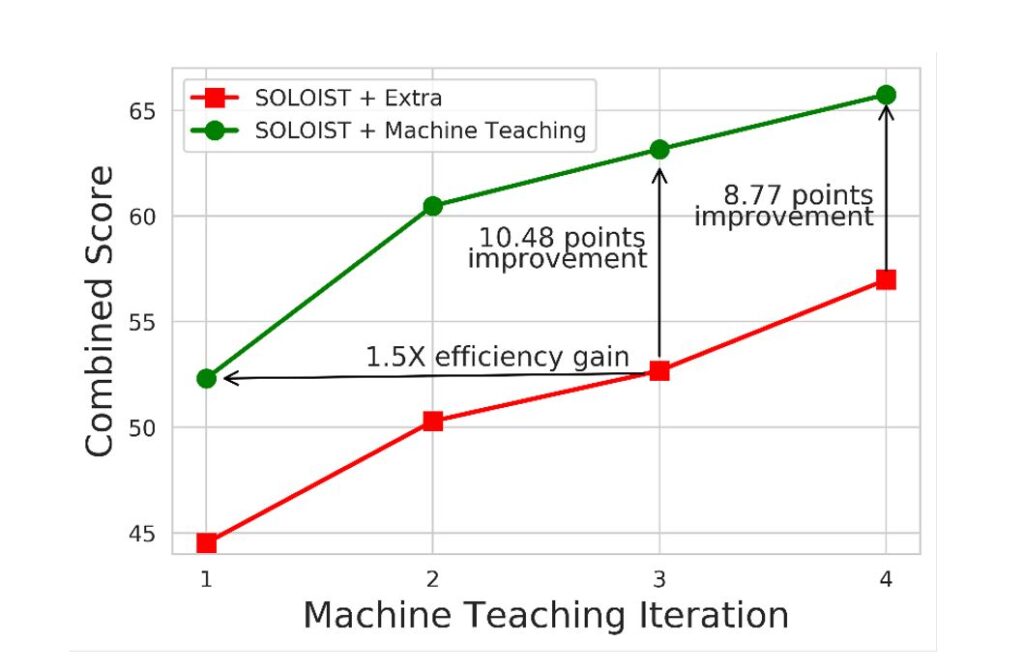
Figure 3 demonstrates the performance of SOLOIST in the Restaurant domain by repeating the previously mentioned machine teaching process in multiple iterations. We observe that in the second iteration of machine teaching, SOLOIST plus Teach improves Combined by more than 8 points, while SOLOIST plus Extra achieves 5 points higher. The result demonstrates the effectiveness of our two-step fine-tuning scheme to deploy SOLOIST for a new task. In terms of machine teaching cost, taking the Restaurant domain as an example, we assume that one slot-value pair of belief state correction counts as one edit and a response correction counts as ten edits. The total numbers of edits for SOLOIST plus Teach and SOLOIST plus Extra are 61 and 396, respectively, suggesting that machine teaching reduces the labeling cost by 6 times.
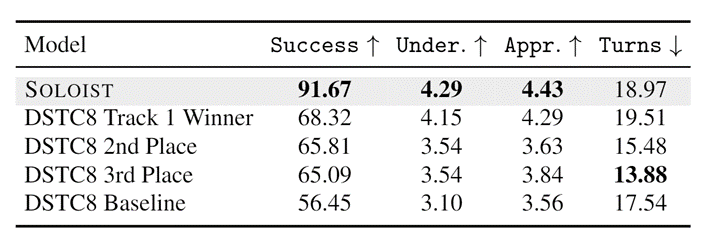
Human evaluation. We conduct human evaluation to assess the quality of SOLOIST when interacting with human users. Following the evaluation protocol in the DSTC8 Track 1 Challenge, we host the best-performing SOLOIST on the validation set in MultiWOZ domain (in the back end as bot services), and we crowdsource the work to Amazon Mechanical Turk. For each dialog session, we present the Turks a goal with instructions. Then, Turks are required to converse with SOLOIST to achieve the goal and judge the overall dialog experience at the end of a session using four metrics:
- Success, which evaluates task completion.
- Under. (language understanding score), which ranges from 1 (bad) to 5 (good) and indicates the extent to which the system understands user inputs.
- Appr. (response appropriateness score), which scales from 1 (bad) to 5 (good) and denotes whether the response is appropriate and human-like.
- Turns, which is the average number of turns in a dialog over all successful dialog sessions. Turks are further required to write down a justification of giving a specific rating. In total, 120 dialog sessions are gathered for analysis.
Table 4 shows the human assessment results on MultiWOZ. The results are consistent with the automatic evaluation. SOLOIST achieves substantially better performance than other systems over all the metrics. Moreover, SOLOIST outperforms the DSTC8 Track 1 Winner by a much larger margin both in Success (+20 points) and in human evaluation when compared with automatic evaluation (+10 points in Table 1). We attribute this to the fact that Turks use more diverse language to interact with the target bots in interactive human evaluation than that in the pre-collected MultiWOZ dataset, and the use of heterogeneous dialog data for task-grounded pretraining makes SOLOIST a more robust task bot than the others. In many test cases against SOLOIST, Turks comment that they feel like they are talking to a real person.
Looking forward: Advancing task-grounded pretraining and fine-tuning via machine learning
SOLOIST has demonstrated the superior capability of building task bots with transfer learning and machine teaching. We hope that SOLOIST can inspire dialog researchers and developers to comprehensively explore the new paradigm for building task bots based on task-grounded pretraining and fine-tuning via machine teaching. We also hope it will lead to improving the recipe we present in this paper: formulating task-oriented dialog as a single auto-regressive language model, pretraining a task-grounded response generation model on heterogeneous dialog corpora, and adapting the pretrained model to new tasks through fine-tuning using a handful of task-specific examples via machine teaching.
Acknowledgements
This research was conducted by Baolin Peng, Chunyuan Li, Jinchao Li, Shahin Shayandeh, Lars Liden and Jianfeng Gao. We appreciate the help from the entire Project Philly team in providing the computing platform for our research.
The post SOLOIST: Pairing transfer learning and machine teaching to advance task bots at scale appeared first on Microsoft Research.