
This post has been republished via RSS; it originally appeared at: AzureCAT articles.
First published on MSDN on Aug 30, 2018
In our second blog in this series, we'll continue to explore the Azure Data Architecture Guide ! Find the blog posts in this series here:
- Azure Data Architecture Guide – Blog #1: Introduction
- Azure Data Architecture Guide – Blog #2: On-demand big data analytics (this one)
- Azure Data Architecture Guide – Blog #3: Advanced analytics and deep learning
- Azure Data Architecture Guide – Blog #4: Hybrid data architecture
- Azure Data Architecture Guide – Blog #5: Clickstream analysis
- Azure Data Architecture Guide – Blog #6: Business intelligence
- Azure Data Architecture Guide – Blog #7: Intelligent applications
- Azure Data Architecture Guide – Blog #8: Data warehousing
- Azure Data Architecture Guide – Blog #9: Extract, transform, load (ETL)
The following example is a technology implementation we have seen directly in our customer engagements. The example can help lead you into the ADAG content to make the right technology choices for your business.
On-demand big data analytics
Create cloud-scale, enterprise-ready Hadoop clusters in a matter of minutes for batch and real-time data processing. With Azure, you can build your entire big data processing and analytics pipeline from massive data ingest to world-class business intelligence and reporting, using the technology that's right for you.
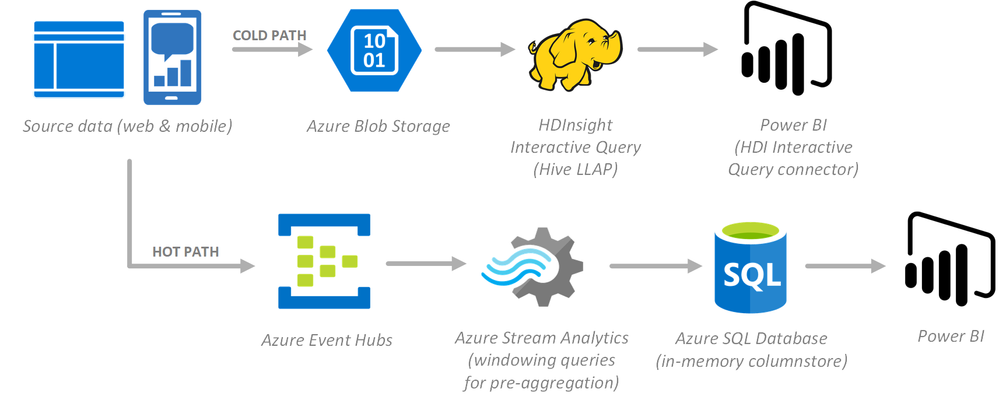
Highlighted services
- Azure Storage blobs
- Interactive Query (Hive LLAP) on HDInsight
- Power BI
- Azure Event Hubs
- Azure Stream Analytics
- Azure SQL Database
Related ADAG articles
- Big Data Architectures
- Scenarios:
- Technology Choices
Please peruse ADAG to find a clear path for you to architect your data solution on Azure:

AzureCAT Guidance
"Hands-on solutions, with our heads in the Cloud!"