
This post has been republished via RSS; it originally appeared at: SQL Server Integration Services (SSIS) articles.
First published on MSDN on Oct 13, 2016In 2008, SSIS team posted a blog about loading 1TB data in 30 minutes, and after 8 years, hardware and software are rapidly improved, now we are doing similar experiment with only on two servers which can achieve same performance. In our experiment, we use the latest SSIS 2016 and we can load 1TB data in 30 minutes (1.5TB dataset in 43 minutes). In addition, we also tested data loading into table with column store index and provide the details in end this article
Design of this experiment is almost same with what we did in 2008 as shown in figure 1. We leverage DB partitions and run multiple SSIS instances to ingest data in parallel way
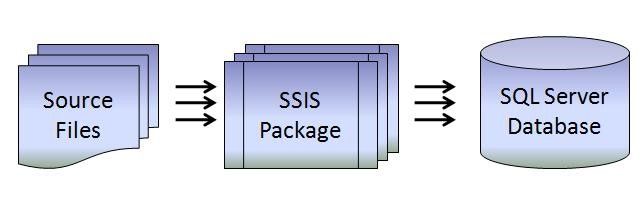
Figure 1
Each package will write to a different partition in the destination tables. More precisely, as illustrated in Figure 2, each package will write into a separate table for highest performance, and the tables will be “switched in” to partitions of the larger table. This will be described more fully in the section on database setup. There are a number of times when partitioning a table is a good practice, one of them being when multiple large insertions need to be performed concurrently

Figure 2
Since we only use two servers and the server configuration is different now, so we simplified settings for NUMA, network and disk configuration.
Test Environment
Two servers, these two servers have same hardware configuration. One of them is dedicated for SQL SERVER and another one is dedicated for SSIS instances. We use 10 GBE link between these two servers. Each server has 4 SSD drives, in SQL SERVER machine, SSD drives are used to store SQL SERVER file groups, and in SSIS instance machine, SSD drives are used to store flat source files.
Server physical configuration:
CPU: 2 sockets each with 12 cores Intel Xeon 2.60GHz
Two physical NUMA nodes
Memory: 128GB
OS: Windows Server 2012 R2 64-bit
Disk: Random read Speed 324 MB/s for each drive; Random write Speed 347 MB/s for each drive
Network: 10 GBE link
Database Setup
First we need to create main table and partitions within main table (as you see in figure 3). Main table is a heap table. Heap table is a table without a clustered index, data is stored without specifying an order, it requires less operation in SQL server side, so it’s can perform better performance for data loading purpose, please refer to https://msdn.microsoft.com/en-us/library/hh213609.aspx for details about heap table

Figure 3
Create Database:
The database is created on 48 file groups and these file groups are distributed to 4 SSDs disk in round-robin way; each file group have 50 GB size. The reason why we split 4 disks is trying to avoid disk throughput bottleneck
CREATE DATABASE sample ON
PRIMARY
( NAME = NYXTaxF0,
FILENAME = N'C:\SQL\NYXTaxFG0.mdf' ,
SIZE = 1GB, MAXSIZE = 1GB , FILEGROWTH = 10% ),
FILEGROUP FG1
( NAME = NYXTaxF1,
FILENAME = 'E:\SQL\NYXTaxFG1.mdf' ,
SIZE = 50GB , MAXSIZE = 50GB ),
FILEGROUP FG2
( NAME = NYXTaxF2,
FILENAME = 'F:\SQL\NYXTaxFG2.mdf' ,
SIZE = 50GB , MAXSIZE = 50GB ),
FILEGROUP FG3
( NAME = NYXTaxF3,
FILENAME = 'G:\SQL\NYXTaxFG3.mdf' ,
SIZE = 50GB , MAXSIZE = 50GB ),
FILEGROUP FG4
( NAME = NYXTaxF4,
FILENAME = 'H:\SQL\NYXTaxFG4.mdf' ,
SIZE = 50GB , MAXSIZE = 50GB ),
...
FILEGROUP FG45
( NAME = NYXTaxF45,
FILENAME = 'E:\SQL\NYXTaxFG45.mdf' ,
SIZE = 50GB , MAXSIZE = 50GB ),
FILEGROUP FG46
( NAME = NYXTaxF46,
FILENAME = 'F:\SQL\NYXTaxFG46.mdf' ,
SIZE = 50GB , MAXSIZE = 50GB ),
FILEGROUP FG47
( NAME = NYXTaxF47,
FILENAME = 'G:\SQL\NYXTaxFG47.mdf' ,
SIZE = 50GB , MAXSIZE = 50GB ),
FILEGROUP FG48
( NAME = NYXTaxF48,
FILENAME = 'H:\SQL\NYXTaxFG48.mdf' ,
SIZE = 50GB , MAXSIZE = 50GB )
LOG ON
( NAME = NYCTax_log,
FILENAME = 'C:\LOG\NYXTaxLog.1df' ,
SIZE = 50GB, MAXSIZE = 50GB)
GO
ALTER DATABASE sample set RECOVERY SIMPLE
ALTER DATABASE sample set AUTO_UPDATE_STATISTICS OFF
ALTER DATABASE sample set AUTO_CREATE_STATISTICS OFF
ALTER DATABASE sample set PAGE_VERIFY NONE
GO
Create DB table partition:
Define partition function and partition scheme. The range boundary is computed by row numbers of each flat file, so there are 48 partitions.
CREATE PARTITION FUNCTION pfnTax (BIGINT ) AS RANGE LEFT FOR VALUES(
250000000, 500000000, 750000000, 1000000000,
1250000000, 1500000000, 1750000000, 2000000000,
2250000000, 2500000000, 2750000000, 3000000000,
3250000000, 3500000000, 3750000000, 4000000000,
4250000000, 4500000000, 4750000000, 5000000000,
5250000000, 5500000000, 5750000000, 6000000000,
6250000000, 6500000000, 6750000000, 7000000000,
7250000000, 7500000000, 7750000000, 8000000000,
8250000000, 8500000000, 8750000000, 9000000000,
9250000000, 9500000000, 9750000000, 10000000000,
10250000000, 10500000000, 10750000000, 11000000000,
11250000000, 11500000000, 11750000000);
CREATE PARTITION SCHEME pscTax AS PARTITION pfnTax TO (FG1,FG2,FG3,FG4,FG5,FG6,FG7,FG8,FG9,FG10,FG11,FG12,FG13,FG14,FG15,FG16,FG17,FG18,FG19,FG20,FG21,FG22,FG23,FG24,FG25,FG26,FG27,FG28,FG29,FG30,FG31,FG32,FG33,FG34,FG35,FG36,FG37,FG38,FG39,FG40,FG41,FG42,FG43,FG44,FG45,FG46,FG47,FG48)
Create partitioned tables:
We need to create sub tables for 1:1 mapping for main table partitions (as you see in figure 4). Partitioned tables are also heap table.

Figure 4
CREATE TABLE LINEITEM ( L_ORDERKEY BIGINT NOT NULL,
L_PARTKEY INTEGER NOT NULL,
L_SUPPKEY INTEGER NOT NULL,
L_LINENUMBER INTEGER NOT NULL,
L_QUANTITY DECIMAL(15,2) NOT NULL,
L_EXTENDEDPRICE DECIMAL(15,2) NOT NULL,
L_DISCOUNT DECIMAL(15,2) NOT NULL,
L_TAX DECIMAL(15,2) NOT NULL,
L_RETURNFLAG CHAR(1) NOT NULL,
L_LINESTATUS CHAR(1) NOT NULL,
L_SHIPDATE DATE NOT NULL,
L_COMMITDATE DATE NOT NULL,
L_RECEIPTDATE DATE NOT NULL,
L_SHIPINSTRUCT CHAR(25) NOT NULL,
L_SHIPMODE CHAR(10) NOT NULL,
L_COMMENT VARCHAR(44) NOT NULL)
on pscTax(L_ORDERKEY)
declare @tblStr varchar(max)
declare @intpartition int
set @intpartition =1
while @intpartition < 49
begin
set @tblStr = '
CREATE TABLE LINEITEM_'+cast(@intpartition as varchar(10))+' ( L_ORDERKEY BIGINT NOT NULL,
L_PARTKEY INTEGER NOT NULL,
L_SUPPKEY INTEGER NOT NULL,
L_LINENUMBER INTEGER NOT NULL,
L_QUANTITY DECIMAL(15,2) NOT NULL,
L_EXTENDEDPRICE DECIMAL(15,2) NOT NULL,
L_DISCOUNT DECIMAL(15,2) NOT NULL,
L_TAX DECIMAL(15,2) NOT NULL,
L_RETURNFLAG CHAR(1) NOT NULL,
L_LINESTATUS CHAR(1) NOT NULL,
L_SHIPDATE DATE NOT NULL,
L_COMMITDATE DATE NOT NULL,
L_RECEIPTDATE DATE NOT NULL,
L_SHIPINSTRUCT CHAR(25) NOT NULL,
L_SHIPMODE CHAR(10) NOT NULL,
L_COMMENT VARCHAR(44) NOT NULL)
on FG'+cast(@intpartition as varchar(10))
exec(@tblStr)
set @intpartition = @intpartition + 1
end
Source data
We use TPC-H generator to generate data for this experiment (as you see in figure 5). We only choose LINEITEM table which is the most complex table in TPC-H table sets, and test data are generated in partition way, each flat file only contains data which will be ingested into dedicate table partition. For this experiment, we generate 48 flat files, each file is 32 GB. To utilize disk I/O, these flat files are distributed to on all disks.

Figure 5
Here is PowerShell script we used to generate data, we target to 2TB TPC-H data set which will generate 1.5TB LINEITEM table data.
$pstart = 1
$pend = 48
for(;$pstart -le $pend;$pstart++){
$args = "-T L -s 2000 -C 48 -S $pstart "
Write-Host $args
Start-Process dbgen.exe -ArgumentList $args
}
SSIS Package Design
Our SSIS 2016 package settings is similar with our 2008 test packages. As shown in figure 6, the dataflow just loads data from flat file and stores data to database.

Figure 6
In figure 7, we set our OLEDB destination to use BULK insert by choosing “fast load”, this method allows user to load data in batch mode which has much fast performance. In figure 8, we set AutoAdjustBufferSize to true so that you do not need to set default buffer size, for more information, please refer to https://msdn.microsoft.com/en-us/library/bb522534.aspx#BufferSize .
DefaultBufferMaxRows is set to different value between heap table test and column store index table test. For heap table, buffer row is 1024000, and for column store index table, buffer row is 1048576. You need to aware that row number of BULK insert will impact column store index table’s data loading performance. For more details, please check https://blogs.msdn.microsoft.com/sqlcat/2015/03/11/data-loading-performance-considerations-with-clustered-columnstore-indexes/ . When you try different buffer size value, you must measure data loading performance
For this experiment, we keep value of “Maximum insert commit size” same as value of “DefaultBufferMaxRows”, customer could have different settings on this value, please refer to https://technet.microsoft.com/en-us/library/dd425070(v=sql.100).aspx for more information.

Figure 7

Figure 8
Soft-NUMA Configuration for SQL SERVER
Modern processors have multiple to many cores per socket, each socket is represented as a single NUMA node, using software NUMA to split hardware NUMA nodes generally increase scalability and performance, please refer to https://msdn.microsoft.com/en-sg/library/ms345357.aspx for more information about NUMA. We try to manually set NUMA node numbers at first, and find SQL SERVER automatic NUMA setting is powerful enough for this experiment. In our test, manual 24 NUMA node settings has same performance with automatic NUMA settings.
Every NUMA nodes is mapped to dedicate TCP ports so we can map SSIS instances to SQL NUMA nodes by TCP ports. You can check https://msdn.microsoft.com/en-us/library/ms345346.aspx for NUMA TCP port mappings
Network settings
Two servers are connected by 10GBE link, we do not have special network settings.
NUMA settings for SSIS instances.
We use DTExec to run packages because SSIS integration catalog service do not aware NUMA settings yet. It’s very important to dispatch SSIS instances to different NUMA nodes, OS will tend to run these SSIS instances on same NUMA node which leave another NUMA node idle, so what we do can avoid CPU competition between SSIS instances.
We use batch script to start SSIS instances with NUMA configuration, sample of batch START command:
start /NODE !nodeNum! /AFFINITY !affinity! DTExec.exe /cons /project "!targetProjectFile!" /package Package.dtsx
/SET \Package.Variables[flatfilepath].Properties[Value];!path!
/SET \Package.Variables[port].Properties[Value];!port!
/SET \Package.Variables[logfile].Properties[Value];!logfile!
(hint: DTExec instances cannot open same project file at same time, so you need to copy and rename project file for many DTExec instances)
Switch partitions after data loading:
After data loading, we need to merge partitions table back to large table which could be done by switching partitions. Meanwhile, before we do partition switch, there must be constraints on these partition tables so that only qualifying data can be merged
ALTER TABLE LINEITEM_1 WITH CHECK ADD CONSTRAINT check_LINEITEM_1
CHECK (L_ORDERKEY >= 1 AND L_ORDERKEY <= 250000000)
ALTER TABLE LINEITEM_1 SWITCH TO LINEITEM PARTITION 1
...
Evaluation
In this experiment, we increase number of SSIS instances until we hit CPU bottleneck, when we ingest data into heap table, SSIS server will hit CPU bottleneck. Figure 9 shows time cost for different number of SSIS instances loading data into heap table.

Figure 9
(NOTE: at first, we try to keep SQL SERVER NUMA nodes number same as SSIS instance number, for example when we test 6 SSIS instances, NUMA node of SQL server is also 6, this helps to map 1 SSIS instance to 1 SQL server NUMA node. However, after test, it turns out SQL server automatic NUMA settings can achieve same performance as manual NUMA settings for different number of SSIS instances. For automatic NUMA settings, every NUMA nodes will be mapped to same number of SSIS instances.)
Table with Column Store Index
Now let’s look at column store index. Column store index is a powerful index feature after SQL server 2012, it stores and manages data by using column-based data storage and column-based query processing, Use the column store index will helps query performance and data compression, please refer to https://msdn.microsoft.com/en-us/library/gg492088.aspx for more details about column store index.
Create column store tables:
declare @tblStr varchar(max)
declare @intpartition int
CREATE TABLE LINEITEM ( L_ORDERKEY BIGINT NOT NULL,
L_PARTKEY INTEGER NOT NULL,
L_SUPPKEY INTEGER NOT NULL,
L_LINENUMBER INTEGER NOT NULL,
L_QUANTITY DECIMAL(15,2) NOT NULL,
L_EXTENDEDPRICE DECIMAL(15,2) NOT NULL,
L_DISCOUNT DECIMAL(15,2) NOT NULL,
L_TAX DECIMAL(15,2) NOT NULL,
L_RETURNFLAG CHAR(1) NOT NULL,
L_LINESTATUS CHAR(1) NOT NULL,
L_SHIPDATE DATE NOT NULL,
L_COMMITDATE DATE NOT NULL,
L_RECEIPTDATE DATE NOT NULL,
L_SHIPINSTRUCT CHAR(25) NOT NULL,
L_SHIPMODE CHAR(10) NOT NULL,
L_COMMENT VARCHAR(44) NOT NULL)
on pscTax(L_ORDERKEY)
CREATE CLUSTERED COLUMNSTORE INDEX cci_LINEITEM ON LINEITEM
set @intpartition =1
while @intpartition < 49
begin
set @tblStr = '
CREATE TABLE LINEITEM_'+cast(@intpartition as varchar(10))+' ( L_ORDERKEY BIGINT NOT NULL,
L_PARTKEY INTEGER NOT NULL,
L_SUPPKEY INTEGER NOT NULL,
L_LINENUMBER INTEGER NOT NULL,
L_QUANTITY DECIMAL(15,2) NOT NULL,
L_EXTENDEDPRICE DECIMAL(15,2) NOT NULL,
L_DISCOUNT DECIMAL(15,2) NOT NULL,
L_TAX DECIMAL(15,2) NOT NULL,
L_RETURNFLAG CHAR(1) NOT NULL,
L_LINESTATUS CHAR(1) NOT NULL,
L_SHIPDATE DATE NOT NULL,
L_COMMITDATE DATE NOT NULL,
L_RECEIPTDATE DATE NOT NULL,
L_SHIPINSTRUCT CHAR(25) NOT NULL,
L_SHIPMODE CHAR(10) NOT NULL,
L_COMMENT VARCHAR(44) NOT NULL)
on FG'+cast(@intpartition as varchar(10))
--print @tblStr
exec(@tblStr)
set @tblStr = 'CREATE CLUSTERED COLUMNSTORE INDEX cci_LINEITEM_'+cast(@intpartition as varchar(10))+' ON LINEITEM_'+cast(@intpartition as varchar(10));
exec(@tblStr)
set @intpartition = @intpartition + 1
end
Test Result:
We can load 1TB data in 67 minutes into table with column store index (1.5TB dataset in 100 minutes), and Loading data into table with CCI could save lots of disk space, in our test, it only takes 1/3 disk space of heap table.