
This post has been republished via RSS; it originally appeared at: Microsoft Developer Blogs.
We are pleased to announce the release of our experimental extension in Visual Studio Code, Gather! Gather is a notebook cleaning tool that analyzes and determines the necessary code dependencies within a notebook and performs code cleanup, automating this difficult, annoying, and time-consuming task.Why Should I Use Gather?
Gather analyzes notebooks and helps users extract only the relevant code segments needed to re-create a particular cell output. This saves you time and effort in manually cleaning up your notebooks and figuring out which cells and more specifically code is important. Some examples of where it can be useful are when you need to clean your notebooks or scripts after data exploration, or when you just want to turn your experimentation into production code. We'd love to hear how you’d use Gather in your workflow! If you have any additional ideas or suggestions for this tool, please let us know in the Gather survey.How Can I Try Gather?
After downloading the Gather Extension, make sure you have the latest version of the Python Extension as well! Gather will not work without, at least, the latest version (2020.7.947746). Once you have both of those downloaded and updated, open up a Jupyter Notebook. After running all your cells in the notebook, you should see the Gather icon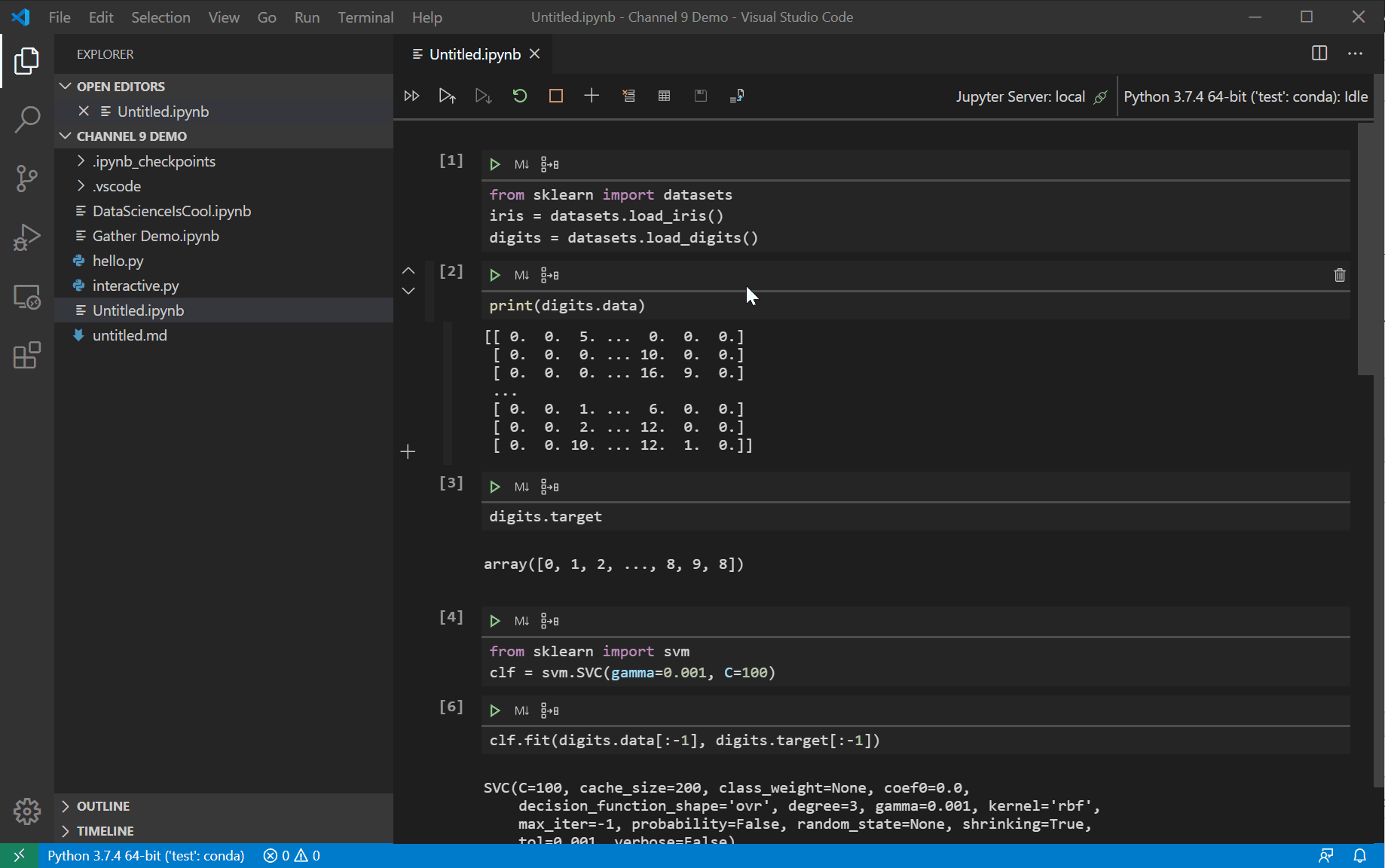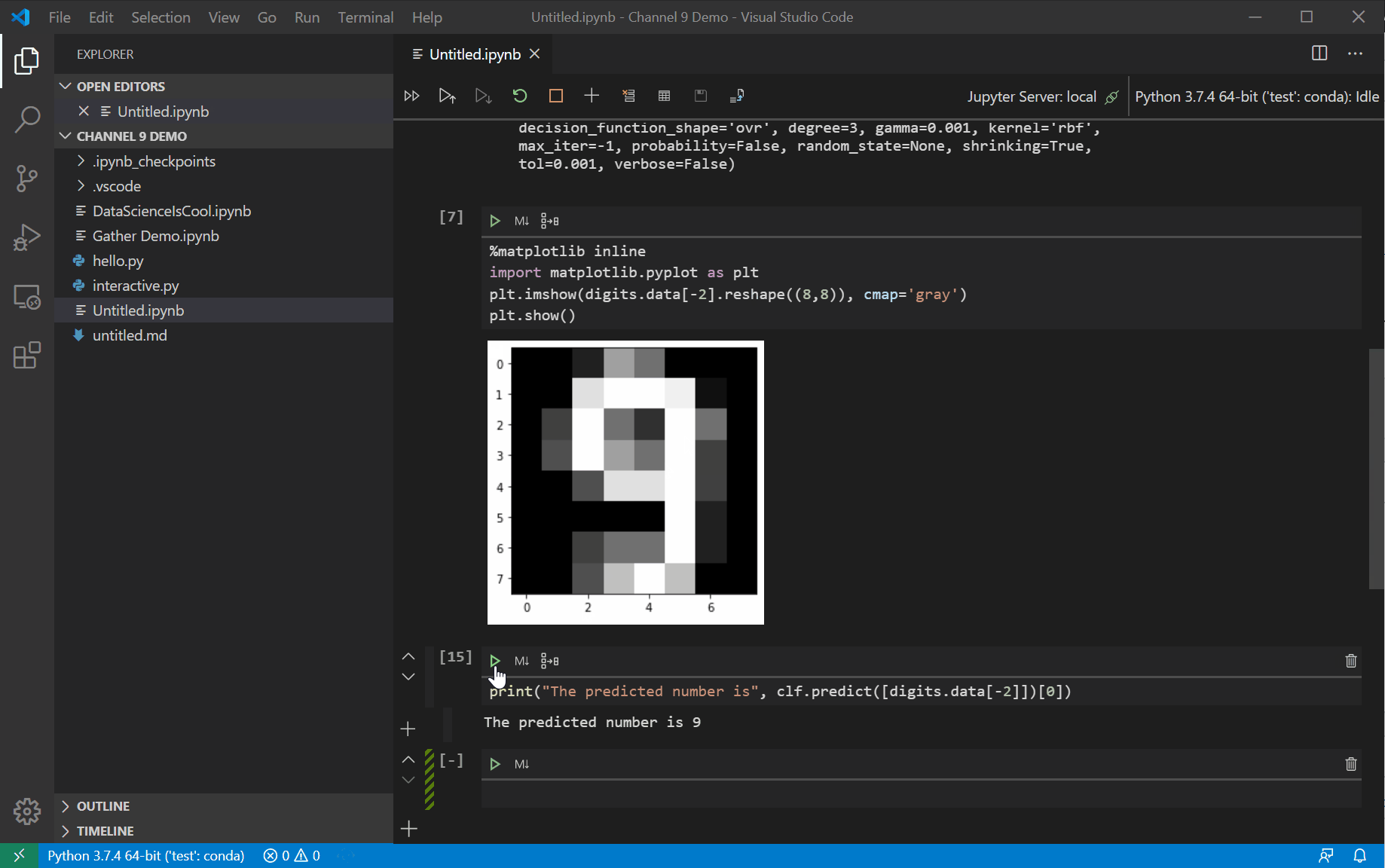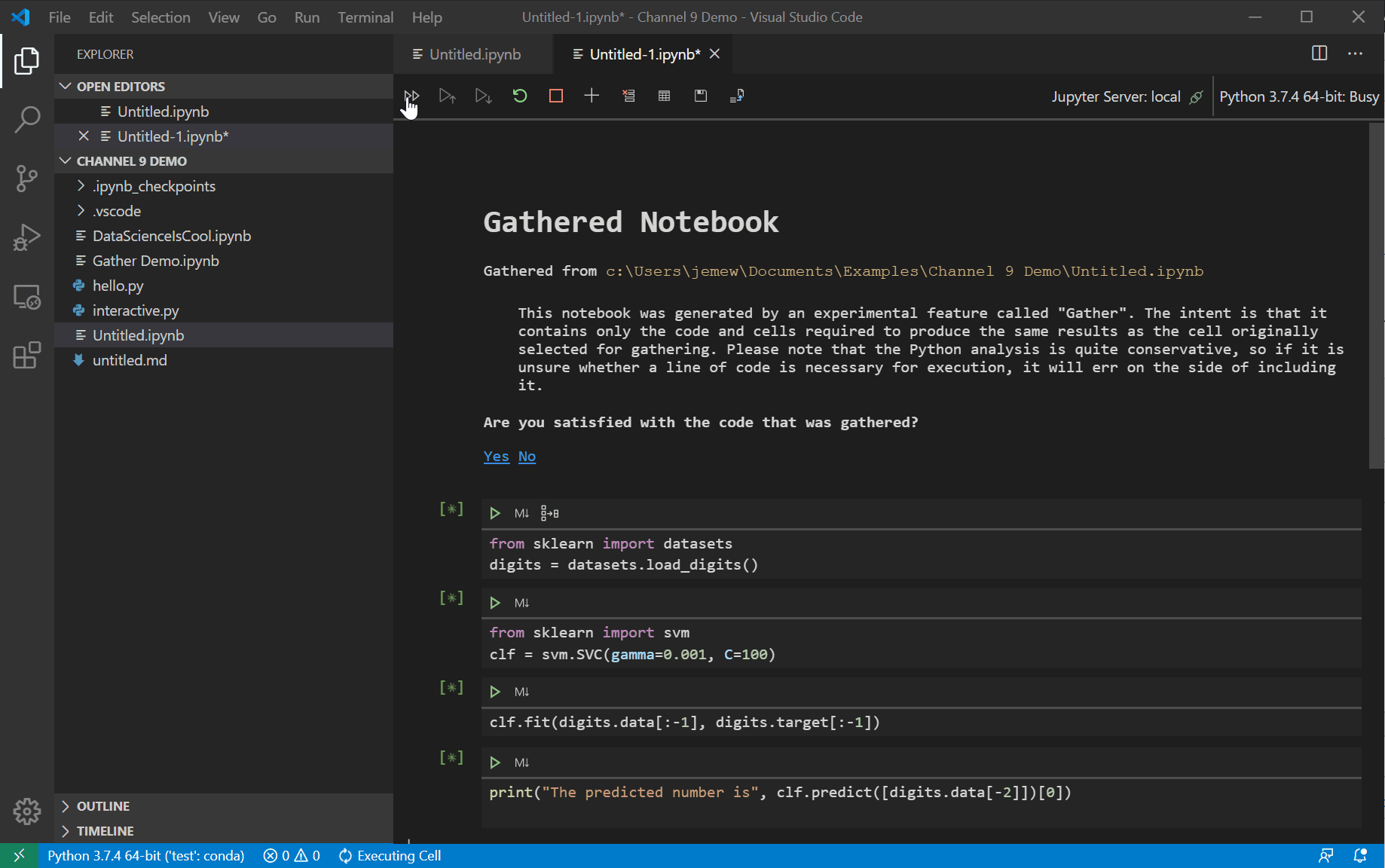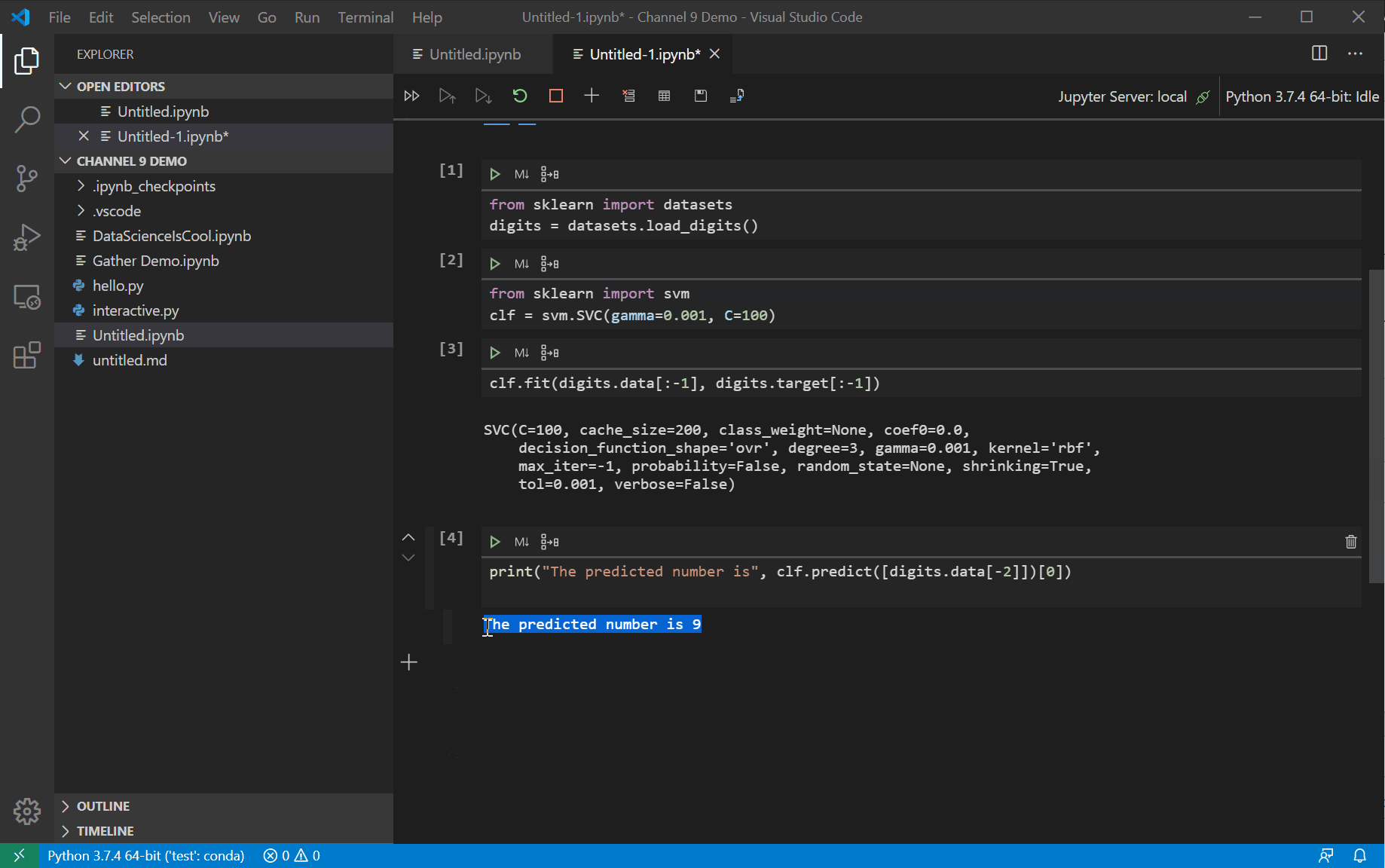 Running Gather on a cell that predicts handwritten numbers trained on the MNIST dataset.[/caption]
Running Gather on a cell that predicts handwritten numbers trained on the MNIST dataset.[/caption]
How Does Gather Work?
Gather is a new technology developed by researchers from the Microsoft Research division as a way to help data scientists manage programming messes in notebooks. It works by continuously analyzing and keeping track of your notebook execution as you execute cells without any performance penalty. When you run Gather on a cell, it will go through that dependency graph and analyze which lines of code in your notebook are needed to produce that output as well as the order those lines were run in. After it has determined the dependent code required, it will create a new notebook or Python file (customizable with the VS Code setting “Data Science: Gather To Script”) with just that code. Gather uses a set of files called "specs" that are used to identify whether each function provided in a Python package modifies kernel state. Currently, the packages that are fully supported are:- matplotlib
- numpy
- pandas
- random
- sklearn
- a set of built-in Python functions/keywords