
This post has been republished via RSS; it originally appeared at: Running SAP Applications on the Microsoft Platform articles.
First published on MSDN on Apr 10, 2018SAP systems moved onto Azure cloud now commonly include large multinational "single global instance" systems and are many times larger than the first customer systems deployed when the Azure platform was first certified for SAP workloads some years ago
Very Large Databases (VLDB) are now commonly moved to Azure. Database sizes over 20TB require some additional techniques and procedures to achieve a migration from on-premises to Azure within an acceptable downtime and a low risk.
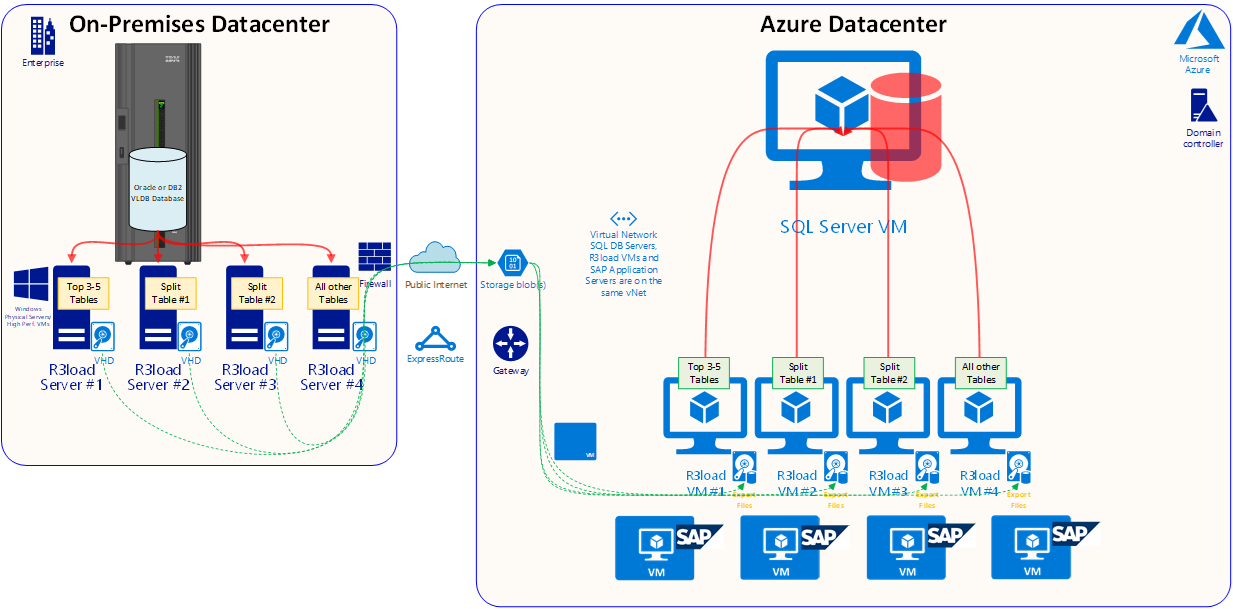
The diagram below shows a VLDB migration with SQL Server as the target DBMS. It is assumed the source systems are either Oracle or DB2
A future blog will cover migration to HANA (DMO) running on Azure. Many of the concepts explained in this blog are applicable to HANA Migrations
This blog does not replace the existing SAP System Copy guide and SAP Notes which should be reviewed and followed.
High Level Overview
A fully optimized VLDB migration should achieve around 2TB per hour migration throughput per hour or possibly more.
This means the data transfer component of a 20TB migration can be done in approximately 10 hours. Various postprocessing and validation steps would then need to be performed.
In general with adequate time for preparation and testing almost any customer system of any size can be moved to Azure.
VLDB Migrations require do considerable skill, attention to detail and analysis. For example the net impact of Table Splitting must be measured and analyzed. Splitting a large table into more than 50 parallel exports may considerably decrease the time taken to Export a table, but too many Table Splits may result in drastically increased Import times. Therefore the net impact of table splitting must be calculated and tested. An expert licensed OS/DB migration consultant will be familiar with the concepts and tools. This blog is intended to be a supplement to highlight some Azure specific content for VLDB migrations
This blog deals with Heterogeneous OS/DB Migration to Azure with SQL Server as the target database using tools such as R3load and Migmon. The steps performed here are not intended for Homogenous System Copies (a copy where the DBMS and Processor Architecture (Endian Order) stays the same). In general Homogeneous System Copies should have very low downtime regardless of DBMS size because log shipping can be used to synchronize a copy of the database in Azure.
A block diagram of a typical VLDB OS/DB migration and move to Azure is illustrated below. The key points illustrated below:
1.The current source OS/DB is often AIX, HPUX, Solaris or Linux and DB2 or Oracle
2. The target OS is either Windows, Suse 12.3, Redhat 7.x or Oracle Linux 7.x
3. The target DB is usually either SQL Server or Oracle 12.2
4. IBM pSeries, Solaris SPARC hardware and HP Superdome thread performance is drastically lower than low cost modern Intel commodity servers, therefore R3load is run on separate Intel servers
5. VMWare requires special tuning and configuration to achieve good, stable and predictable network performance. Typically physical servers are used as R3load server and not VMs
6. Commonly four export R3load servers are used, though there is no limit on the number of export servers. A typical configuration would be:
-Export Server #1 – dedicated to the largest 1-4 tables (depending on how skewed the data distribution is on the source database)
-Export Server #2 – dedicated to tables with table splits
-Export Server #3 – dedicated to tables with table splits
-Export Server #4 – all remaining tables
7. Export dump files are transferred from the local disk in the Intel based R3load server into Azure using AzCopy via public internet (this is typically faster than via ExpressRoute though not in all cases)
8. Control and sequencing of the Import is via the Signal File (SGN) that is automatically generated when all Export packages are completed. This allows for a semi-parallel Export/Import
9. Import to SQL Server or Oracle is structured similarly to the Export, leveraging four Import servers. These servers would be separate dedicated R3load servers with Accelerated Networking. It is recommended not to use the SAP application servers for this task
10. VLDB databases would typically use E64v3, m64 or m128 VMs with Premium Storage. The Transaction Log can be placed on the local SSD disk to speed up Transaction Log writes and remove the Transaction Log IOPS and IO bandwidth from the VM quota. After the migration the Transaction Log should be placed onto persisted disk
Source System Optimizations
The following guidance should be followed for the Source Export of VLDB systems:
1. Purge Technical Tables and Unnecessary Data – review SAP Note 2388483 - How-To: Data Management for Technical Tables
2. Separating the R3load processes from the DBMS server is an essential step to maximize export performance
3. R3load should run on fast new Intel CPU. Do not run R3load on UNIX servers as the performance is very poor. 2-socket commodity Intel servers with 128GB RAM cost little and will save days or weeks of tuning/optimization or consulting time
4. High Speed Network ideally 10Gb with minimal network hops between the source DB server and the Intel R3load servers
5. It is recommended to use physical servers for the R3load export servers – virtualized R3load servers at some customer sites did not demonstrated good performance or reliability at extremely high network throughput (Note: very experienced VMWare engineer can configure VMWare to perform well)
5. Sequence larger tables to the start of the Orderby.txt
6. Configure Semi-parallel Export/Import using Signal Files
6. Large exports will benefit from Unsorted Export on larger tables. It is important to review the net impact of Unsorted Exports as importing unsorted exports to databases that have a clustered index on the primary key will be slower
7. Configure Jumbo Frames between source DB server and Intel R3load servers. See "Network Optimization" section later
8. Adjust memory settings on the source database server to optimize for sequential read/export tasks 936441 - Oracle settings for R3load based system copy
Advanced Source System Optimizations
1. Oracle Row ID Table Splitting
SAP have released SAP Note 1043380 which contains a script that converts the WHERE clause in a WHR file to a ROW ID value. Alternatively the latest versions of SAPInst will automatically generate ROW ID split WHR files if SWPM is configured for Oracle to Oracle R3load migration. The STR and WHR files generated by SWPM are independent of OS/DB (as are all aspects of the OS/DB migration process).
The OSS note contains the statement "ROWID table splitting CANNOT be used if the target database is a non-Oracle database". Technically the R3load dump files are completely independent of database and operating system. There is one restriction however, restart of a package during import is not possible on SQL Server. In this scenario the entire table will need to be dropped and all packages for the table restarted. It is always recommended to kill R3load tasks for a specific split table, TRUNCATE the table and restart the entire import process if one split R3load aborts. The reason for this is that the recovery process built into R3load involves doing single row-by-row DELETE statements to remove the records loaded by the R3load process that aborts. This is extremely slow and will often cause blocking/locking situations on the database. Experience has shown it is faster to start the import of this specific table from the beginning, therefore the limitation mentioned in Note 1043380 is not a limitation at all
ROW ID has a disadvantage that calculation of the splits must be done during downtime – see SAP Note 1043380 .
2. Create multiple "clones" of the source database and export in parallel
One method to increase export performance is to export from multiple copies of the same database. Provided the underlying infrastructure such as server, network and storage is scalable this approach is linearly scalable. Exporting from two copies of the same database will be twice as fast, 4 copies will be 4 times as fast. Migration Monitor is configured to export on a select number of tables from each "clone" of the database. In the case below the export workload is distributed approximately 25% on each of the 4 DB servers.
-DB Server1 & Export Server #1 – dedicated to the largest 1-4 tables (depending on how skewed the data distribution is on the source database)
-DB Server2 & Export Server #2 – dedicated to tables with table splits
-DB Server3 & Export Server #3 – dedicated to tables with table splits
-DB Server4 & Export Server #4 – all remaining tables
Great care must be taken to ensure that the databases are exactly and precisely synchronized, otherwise data loss or data inconsistencies could occur. Provided the steps below are precisely followed, data integrity is provided.
This technique is simple and cheap with standard commodity Intel hardware but is also possible for customers running proprietary UNIX hardware. Substantial hardware resources are free towards the middle of an OS/DB migration project when Sandbox, Development, QAS, Training and DR systems have already moved to Azure. There is no strict requirement that the "clone" servers have identical hardware resources. So long as there is adequate CPU, RAM, disk and network performance the addition of each clone increases performance
If additional export performance is still required open an SAP incident in BC-DB-MSS for additional steps to boost export performance (very advanced consultants only)
Steps to implement a multiple parallel export:
1. Backup the primary database and restore onto "n" number of servers (where n = number of clones). In the case illustrated 3 is chosen making a total of 4 DB servers
2. Restore backup onto 3 servers
3. Establish log shipping from the Primary source DB server to 3 target "clone" servers
4. Monitor log shipping for several days and ensure log shipping is working reliably
5. At the start of downtime shutdown all SAP application servers except the PAS. Ensure all batch processing is stopped and all RFC traffic is stopped
6. In transaction SM02 enter text "Checkpoint PAS Running". This updates table TEMSG
7. Stop the Primary Application Server. SAP is now completely shutdown. No more write activity can occur in the source DB. Ensure that no non-SAP application is connected to the source DB (there never should be, but check for any non-SAP sessions at the DB level)
8. Run this query on the Primary DB server SELECT EMTEXT FROM <schema>.TEMSG;
9. Run the native DBMS level statement INSERT INTO <schema>.TEMSG "CHECKPOINT R3LOAD EXPORT STOP dd:mm:yy hh:mm:ss" (exact syntax depends on source DBMS. INSERT into EMTEXT)
10. Halt automatic transaction log backups. Manually run one final transaction log backup on the Primary DB server. Ensure the log backup is copied to the clone servers
11. Restore the final transaction log backup on all 3 nodes
12. Recover the database on the 3 "clone" nodes
13. Run the following SELECT statement on *all* 4 nodes SELECT EMTEXT FROM <schema>.TEMSG;
14. With a phone or camera photograph the screen results of the SELECT statement for each of the 4 DB servers (the Primary and the 3 clones). Be sure to carefully include each hostname in the photo – these photographs are proof that the clone DB and the primary are identical and contain the same data from the same point in time. Retain these photos and get customer to sign off the DB replication status
15. Start export_monitor.bat on each Intel R3load export server
16. Start the dump file copy to Azure process (either AzCopy or Robocopy)
17. Start import_monitor.bat on the R3load Azure VMs
Diagram showing existing Production DB server log shipping to "clone" databases. Each DB server has one or more Intel R3load servers

Network Upload Optimizations
Jumbo Frames are ethernet frames larger than the default 1500 bytes. Typical Jumbo Frame sizes are 9000 bytes. Increasing the frame size on the source DB server, all intermediate network devices such as switches and the Intel R3load servers reduces CPU consumption and increases network throughput. The Frame Size must be identical on all devices otherwise very resource intensive conversion will occur.
Additional networking features such as Receive Side Scaling (RSS) can be switched on or configured to distribute network processing across multiple processors Running R3load servers on VMWare has proven to make network tuning for Jumbo Frames and RSS more complex and is not recommended unless there very expert skill level available
R3load exports data from DBMS tables and compresses this raw format independent data in dump files. These dump files need to be uploaded into Azure and imported to the Target SQL Server database.
The performance of the copy and upload to Azure of these dump files is a critical component in the overall migration process.
There are two basic approaches for upload of R3load dump files:
1.Copy from on-premises R3load export servers to Azure blob storage via Public Internet with AzCopy
On each of the R3load servers run a copy of AzCopy with this command line:
AzCopy
/source
:C:\ExportServer_1\Dumpfiles
/dest
:https://<storage_account>/ExportServer_1/Dumpfiles
/destkey
:xxxxxx /S
/NC
:xx /blobtype:page

The value for /NC: determines how many parallel sessions are used to transfer files. In general AzCopy will perform best with a larger number of smaller files and /NC values between 24-48. If a customer has a powerful server and very fast internet this value can be increased. If this value is increased too high connection to the R3load export server will be lost due to network saturation. Monitor the network throughput in Windows Task Manager. Copy throughput of over 1Gigabit per second per R3load Export Server can be easily achieved. Copy throughput can be scaled up by having more R3load servers (4 are depicted in the diagram above)
A similar script will need to be run on the R3load Import servers in Azure to copy the files from Blob onto a file system that R3load can access.
2. Copy from on-premises R3load export servers to an Azure VM or blob storage via a dedicated ExpressRoute connection using AzCopy, Robocopy or similar tool
Robocopy C:\Export1\Dump1 \\az_imp1\Dump1 /MIR /XF *.SGN /R:20 /V /S /Z /J /MT:8 /MON:1 /TEE /UNILOG+:C:\Export1\Robo1.Log
The block diagram below illustrates 4 Intel R3load servers running R3load. In the background Robocopy is started uploading dump files. When entire split tables and packages are completed the SGN file is copied either manually or via a script. When the SGN file for a package arrives on the import R3load server this will trigger import for this package automatically

Note: Copying files over NFS or Windows SMB protocols is not as fast or robust as mechanisms such as AzCopy. It is recommended to test performance of both file upload techniques. It is recommended to notify Microsoft Support for VLDB migration projects as very high throughput network operations might be mis-identified as Denial of Service attacks.
Target System Optimizations
1. Use latest possible OS with latest patches
2. Use latest possible DB with latest patches
3. Use latest possible SAP Kernel with latest patches (eg. Upgrade from 7.45 kernel to 7.49 or 7.53)
4. Consider using the largest available Azure VM. The VM type can be lowered to a smaller VM after the Import process
5. Create multiple Transaction Log files with the first transaction log file on the local non-persistent SSD. Additional Transaction Log files can be created on P50 disks. VLDB migrations could require more than 5TB of Transaction Log space. It is strongly recommended to ensure there is always a large amount of Transaction Log space free at all times (20% is a safe figure). Extending Transaction Log files during an Import is not recommended and will impact performance
6. SQL Server Max Degree of Parallelism should usually be set to 1. Only certain index build operations will benefit from MAXDOP and then only for specific tables
7. Accelerated Networking is mandatory for DB and R3load servers
8. It is recommended to use m128 3.8TB as the DB server and E64v3 as the R3load servers (as at March 2018)
9. Limit the maximum memory a single SQL Server query can request with Resource Governor. This is required to prevent index build operations from requesting very large memory grants
10. Secondary indexes for very large tables can be removed from the STR file and built ONLINE with scripts after the main portion of the import has finished and post processing tasks such as configuring STMS are occurring
11. Customers using SQL Server TDE are recommended to pre-create the database and Transaction Log files, then enable TDE prior to starting the import. TDE will run for a similar amount of time on a DB that is full of data or empty. Enabling TDE on a VLDB can lead to blocking/locking issues and it is generally recommended to import into a TDE database. The overhead importing to a TDE database is relatively low
12. Review the latest OS/DB Migration FAQ
Recommended Migration Project Documents
VLDB OS/DB migrations require additional levels of technical skill and also additional documentation and procedures. The purpose of this documentation is to reduce downtime and eliminate the possibility of data loss. The minimum acceptable documentation would include the following topics:
1. Current SAP Application Name, version, patches, DB size, Top 100 tables by size, DB compression usage, current server hardware CPU, RAM and disk
2. Data Archiving/Purging activities completed and the space savings achieved
3. Details on any upgrade, Unicode conversion or support packs to be applied during the migration
4. Target SAP Application version, Support Pack Level, estimated target DB size (after compression), Top 100 tables by size, DB version and patch, OS version and patch, VM sku, VM configuration options such as disk cache, write accelerator, accelerated networking, type and quantity of disks, database file sizes and layout, DBMS configuration options such as memory, traceflags, resource governor
5. Security is typically a separate topic, but network security groups, firewall settings, Group Policy, DBMS encryption settings
6. HA/DR approach and technologies, in addition special steps to establish HA/DR after the initial import is finished
7. OS/DB migration design approach:
-How many Intel R3load export servers
-How many R3load import VMs
-How many R3load processes per VM
-Table splitting settings
-Package splitting settings
-export and import monitor settings
-list of secondary indexes to be removed from STR files and created manually
-list of pre-export tasks such as clearing updates
9. Analysis of last export/import cycle. Which settings were changed? What was the impact on the "flight plan"? Is the configuration change accepted or rejected? Which tuning & configuration is planned for next test cycle?
10. Recovery procedures and exception handling – procedures for rollback, how to handle exceptions/issues that have occurred during previous test cycles
It is typically the responsibility of the lead OS/DB migration consultant to prepare this documentation. Sometimes topics such as Security, HA/DR and networking are handled by other consultants. The quality of such documentation has proven to be a very good indicator of the skill level and capability of the project team and the risk level of the project to the customer.
Migration Monitoring
One of the most important components of a VLDB migration is the monitoring, logging and diagnostics that is configured during Development, Test and "dry run" migrations.
Customers are strongly advised to discuss with their OS/DB migration consultant implementation and usage of the steps in this section of the blog . Not to do so exposes a customer to a significant risk.
Deployment of the required monitoring and interpretation of the monitoring and diagnostic results after each test cycle is mandatory and essential for optimizing the migration and planning production cutover. The results gained in test migrations are also necessary to be able to judge whether the actual production migration is following the same patterns and time lines as the test migrations. Customers should request regular project review checkpoints with the SAP partner. Contact Microsoft for a list of consultants that have demonstrated the technical and organizational skills required for a successful project.
Without comprehensive monitoring and logging it would be almost impossible to achieve safe, repeatable, consistent and low downtime migrations with a guarantee of no data loss. If problems such as long runtimes of some packages were to occur, it is almost impossible for Microsoft and/or SAP to assist with spot consulting without monitoring data and migration design documentation
During the runtime of an OS/DB migration:
OS level parameters on DB and R3load hosts: CPU per thread, Kernel time per thread, Free Memory (GB), Page in/sec, Page out/sec, Disk IO reads/sec, Disk IO write/sec, Disk read KB/sec, Disk write KB/sec
DB level parameters on SQL Server target: BCP rows/sec, BCP KB/sec, Transaction Log %, Memory Grants, Memory Grants pending, Locks, Lock memory, locking/blocking
Network monitoring normally handled by network team. Exactly configuration of network monitoring depends on customer specific situation.
During the runtime of the DB import it is recommended to execute this SQL statement every few minutes and screenshot anything abnormal (such as high wait times)
select session_id, request_id,start_time,
status, command, wait_type, wait_resource, wait_time, last_wait_type, blocking_session_id from sys.dm_exec_requests
where session_id >49 orderby wait_time desc;
During all migration test cycles a "Flight Plan" showing the number of packages exported and imported (y-axis) should be plotted against time (x-axis). The purpose of this graph is to establish an expected rate of progress during the final production migration cutover. Deviation (either positive or negative) from the expected "Flight Plan" during test or the final production migration is easily detected using this method. Other parameters such as CPU, disk and R3load rows/sec can be overlaid on top of the "Flight Plan"
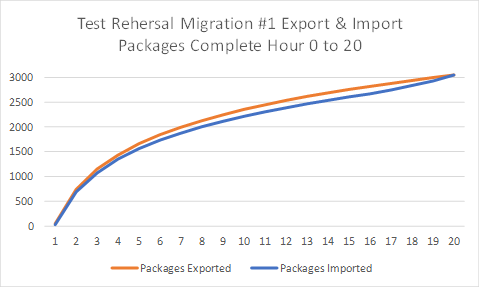
At the conclusion of the Export and Import the migration time reports must be collected (export_time.html and import_time.html) https://blogs.sap.com/2016/11/17/time-analyzer-reports-for-osdb-migrations/
VLDB Migration Do's & Don't
The guidelines contained in this blog are based on real customer projects and the learnings derived from these projects. This blog instructs customers to avoid certain scenarios because these have been unsuccessful in the past. An example is the recommendation not to use UNIX servers or virtualized servers as R3load export servers:
1. Very often the export performance is a gating factor on the overall downtime. Often the current hardware is more than 4-5 years old and is prohibitively expensive to upgrade
2. It is therefore important to get the maximum export performance that is practical to achieve
3. Previous projects have spent man-weeks or even man-months trying to tune R3load export performance on UNIX or virtualized platforms, before giving up and using Intel R3load servers
4. 2-socket commodity Intel servers are very inexpensive and immediately deliver substantial performance gains, in some cases many orders of magnitude greater than minor tuning improvements possible on UNIX or virtualized servers
5. Customers often have existing VM farms but most often these do not support modern offload or SRIOv technologies. Often the VMWare version is old, unpatched or not configured for very high network throughput and low latency. R3load export servers require very fast thread performance and extremely high network throughput. R3load export servers may run for 10-15 hours at nearly 100% CPU and network utilization. This is not the typical use case of most VMWare farms and most VMWare deployments were never designed to handle a workload such as R3load.
RECOMMENDATION: Do not invest time into optimizing R3load export performance on UNIX or virtualized platforms. Doing so will waste not only time but will cost much more than buying low cost Intel servers at the start of the project. VLDB migration customers are therefore requested to ensure the project team has fast modern R3load export servers available at the start of the project. This will lower the total cost and risk of the project.
Do:
1. Survey and Inventory the current SAP landscape. Identify the SAP Support Pack levels and determine if patching is required to support the target DBMS. In general the Operating Systems Compatibility is determined by the SAP Kernel and the DBMS Compatibility is determined by the SAP_BASIS patch level.
Build a list of SAP OSS Notes that need to be applied in the source system such as updates for SMIGR_CREATE_DDL. Consider upgrading the SAP Kernels in the source systems to avoid a large change during the migration to Azure (eg. If a system is running an old 7.41 kernel, update to the latest 7.45 on the source system to avoid a large change during the migration)
2. Develop the High Availability and Disaster Recovery solution. Build a PowerPoint that details the HA/DR concept. The diagram should break up the solution into the DB layer, ASCS layer and SAP application server layer. Separate solutions might be required for standalone solutions such as TREX or Livecache
3. Develop a Sizing & Configuration document that details the Azure VM types and storage configuration. How many Premium Disks, how many datafiles, how are datafiles distributed across disks, usage of storage spaces, NTFS Format size = 64kb. Also document Backup/Restore and DBMS configuration such as memory settings, Max Degree of Parallelism and traceflags
4. Network design document including VNet, Subnet, NSG and UDR configuration
5. Security and Hardening concept. Remove Internet Explorer, create a Active Directory Container for SAP Service Accounts and Servers and apply a Firewall Policy blocking all but a limited number of required ports
6. Create an OS/DB Migration Design document detailing the Package & Table splitting concept, number of R3loads, SQL Server traceflags, Sorted/Unsorted, Oracle RowID setting, SMIGR_CREATE_DDL settings, Perfmon counters (such as BCP Rows/sec & BCP throughput kb/sec, CPU, memory), RSS settings, Accelerated Networking settings, Log File configuration, BPE settings, TDE configuration
7. Create a "Flight Plan" graph showing progress of the R3load export/import on each test cycle. This allows the migration consultant to validate if tunings and changes improve r3load export or import performance. X axis = number of packages complete. Y axis = hours. This flight plan is also critical during the production migration so that the planned progress can be compared against the actual progress and any problem identified early.
8. Create performance testing plan. Identify the top ~20 online reports, batch jobs and interfaces. Document the input parameters (such as date range, sales office, plant, company code etc) and runtimes on the original source system. Compare to the runtime on Azure. If there are performance differences run SAT, ST05 and other SAP tools to identify inefficient statements
9. SAP BW on SQL Server. Check this blogsite regularly for new features for BW systems including Column Store
10. Audit deployment and configuration, ensure cluster timeouts, kernels, network settings, NTFS format size are all consistent with the design documents. Set perfmon counters on important servers to record basic health parameters every 90 seconds. Audit that the SAP Servers are in a separate AD Container and that the container has a Policy applied to it with Firewall configuration.
11. Do check that the lead OS/DB migration consultant is licensed! Request the consultant name, s-user and certification date. Open an OSS message to BC-INS-MIG and ask SAP to confirm the consultant is current and licensed.
12. If possible, have the entire project team associated with the VLDB migration project within one physical location and not geographically dispersed across several continents and time zones.
13. Make sure that there is a proper fallback plan is in place and that it is part of the overall schedule.
14. Do select fast thread count Intel CPU models for the R3load export servers. Do not use "Energy Saver" CPU models as they have much lower performance and do not use 4-socket servers. Intel Xeon E5 Platinum 8158 is a good example
Do not:
1. VLDB OS/DB migration requires an advanced technical skillset and very strong process, change control & documentation. Do not do "on the job training" with VLDB migrations
2. Do not subcontract one consulting organization to do the Export and subcontract another consulting organization to do the Import. Occasionally the Source system is outsourced and managed by one consulting organization or partner and a customer wishes to migrate to Azure and switch to another partner. Due to the tight coupling between Export and Import tuning and configuration it is very unlikely assigning these tasks to different organizations will produce a good result
3. Do not economize on Azure hardware resources during the migration and go live. Azure VMs are charged per minute and can be reduced in size very easily. During a VLDB migration leverage the most powerful VM available. Customers have successfully gone live on 200-250% oversized systems, then stabilized while running significantly oversized systems. After monitoring utilization for 4-6 weeks, VMs are reduced in size or shutdown to lower costs
Required Reading, Documentation and Tips
Below are some recommendations for those setting up this solution based on test deployments:
Check the SAP on Microsoft Azure blog regularly https://blogs.msdn.microsoft.com/saponsqlserver/
Read the latest SAP OS/DB Migration FAQ https://blogs.msdn.microsoft.com/saponsqlserver/tag/migration/
A useful blog on DMO is here https://blogs.sap.com/2017/10/05/your-sap-on-azure-part-2-dmo-with-system-move/
Information on DMO https://blogs.sap.com/2013/11/29/database-migration-option-dmo-of-sum-introduction/
Content from third party websites, SAP and other sources reproduced in accordance with Fair Use criticism, comment, news reporting, teaching, scholarship, and research