
This post has been republished via RSS; it originally appeared at: Premier Field Engineering articles.
First published on MSDN on Nov 17, 2017
SQL Server 2017 was recently launched, having multiple new features. One of these included something called "Read-Scale Availability Groups". There was a good bit of discussion about this feature and one of the feedback items was that the details in Docs was very light. I hope to rectify the minimal amount of information through this blog post.
What is a Read-Scale Availability Group?
Read-Scale availability groups are ones where we don't want the availability group for high-availability, instead, we want to use it to create multiple copies of our databases that span across multiple servers allowing for the spreading of a large read-only workload. There are various scenarios where this might be extremely valuable and in previous versions of SQL Server it was possible, though there was a requirement of using Windows Server Failover Clustering (WSFC). Read-Scale availability groups do not require the WSFC component and does not give high-availability or disaster recovery, it only acts as a mechanism (availability groups) to facilitate the synchronization of the databases across multiple servers.
To reiterate, this is not used for high-availability but instead to scale your databases across multiple servers for read workloads.
How Do I Enable This Feature?
The setup is the same that you'd do for a regular availability group, with two distinctions:
- Windows Server Failover Clustering is not needed
- The Availability Group manager does not have or need a cluster context
- A new cluster_type option is present
- To use this, we want the cluster_type of "NONE"
What does this look like? The simple answer is, it looks like this: 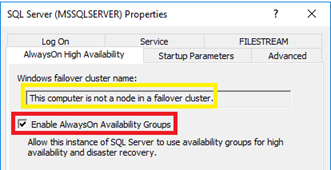
Notice that we're now able to enable the AlwaysOn Availability Groups feature without the need for a cluster.
Creating a Read-Scale Availability Group
Now that the feature is enabled, how do we create a Read-Scale Availability Group? If you're used to using the wizard, it'll be able to walk you through start to finish (requires Management Studio 17). If you like to use T-SQL, there is a new option called Cluster_Type which we'll want to set as NONE.
Here you can set this in the Wizard: 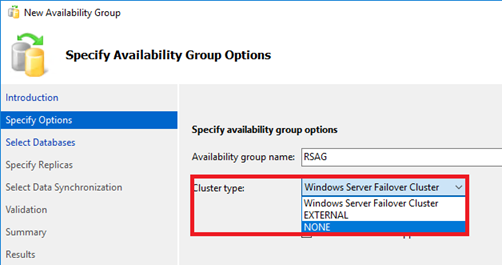
It is also possible using T-SQL: 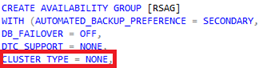
Can I use Read Only Routing?
The documentation does say that we can use Read Only Routing with Read-Scale Availability Groups which would be ideal given that we now have multiple readable copies of the database.
Normally, a listener is a network name cluster resource backed by a computer object in active directory (for an active directory attached cluster) – however we don't have a cluster. This was another change that was made, we can create a listener without the need of a cluster. This does not make the databases or services highly available, but it is a requirement for Read Only Routing. Other options include creating DNS Round Robin, hardware load balancer, and NLB for the read only replicas.
To start, setup read only routing as would be normal with setting the routing url and routing lists. Here is an example, in my environment: 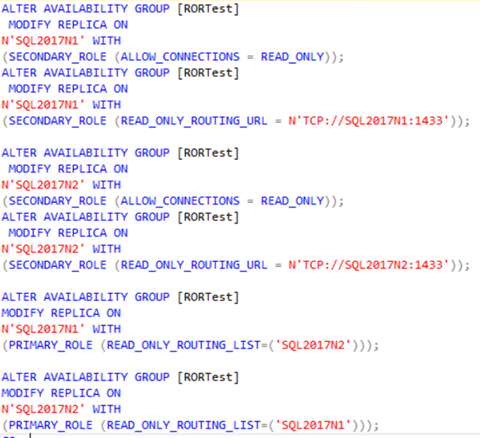
Then we get to the listener, which I will be using the local node's IP address and default port. The value of this may not even matter if it won't be registered in DNS based on what the use cases are. This could also be facilitated by using a load balancer in front of the read-scale availability groups and without the need to create a listener. 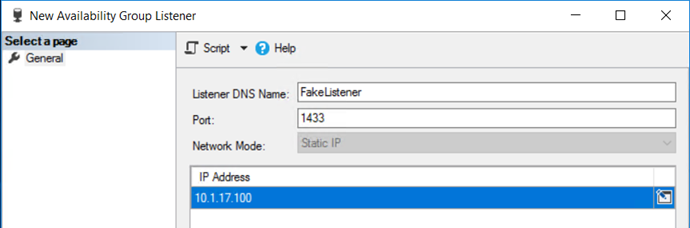
Here is what the listener looks like from the DMV, notice that the listener_id is a special value. 
Once the listener is setup we can connect the primary replica, using just the primary replica's name. Here you can see that the requirements for read only routing are still needed, and I have included them in my additional connection options in SSMS. I'm connecting to the primary node, which in this case is SQL2017N1, and am being read only routed to SQL2017N2 as shown in the output. 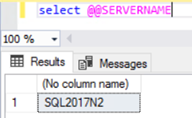
Please Note: When creating the listener, you'll need to use the IP Address of the primary node. Since this does not use WSFC, any failovers will need to have the listener dropped and re-created with the current primary node's IP address to properly read only route. I would highly suggest instead of using read only routing that a dns round robin or hardware load balancer setup be used for the secondary readable replicas in the availability group and always keeping the same primary. Read-Scale availability groups, to reiterate, are for scale out reading only and do not give any high availability options.
Resources
If you want code examples of setting up the certificates and endpoints as well as a video walk through, check out this post on Read-Scale Availability Group Setup by Ryan Adams.