
This post has been republished via RSS; it originally appeared at: Microsoft Research.
You’re in a field. In front of you, there’s a white house. The door is boarded shut. The immediate challenge—investigate the house. The game—Zork I: The Great Underground Empire, a treasure-seeking adventure in which you’ll encounter monsters, a thief, and other interesting characters along the way.
As a player of this text-based game, you string together simple commands of only several words, like “walk to the house.” Once there, you type a series of commands, not all of them fruitful, to circle the house until you find a way in. There is a window ajar. You “open the window” and “enter the house,” the adventure truly beginning. To continue between rooms within the house and locations beyond and to interact with the objects you find, you rely on your ability to recall prior information like realizing the lantern you need to safely explore underground is in a previous location and commonsense knowledge to know what to do when you find it.
Interactive fiction (IF) games such as Zork provide great environments for reinforcement learning agents to hone their natural language understanding and generation. However, without the commonsense knowledge and effective recall human players possess, they’re faced with a task far more monumental than ours—choosing from billions of possible actions. For example, an agent generating a modest four-word command from a provided vocabulary of 700 words is effectively navigating a space of size 7004, or 240 billion possible actions.
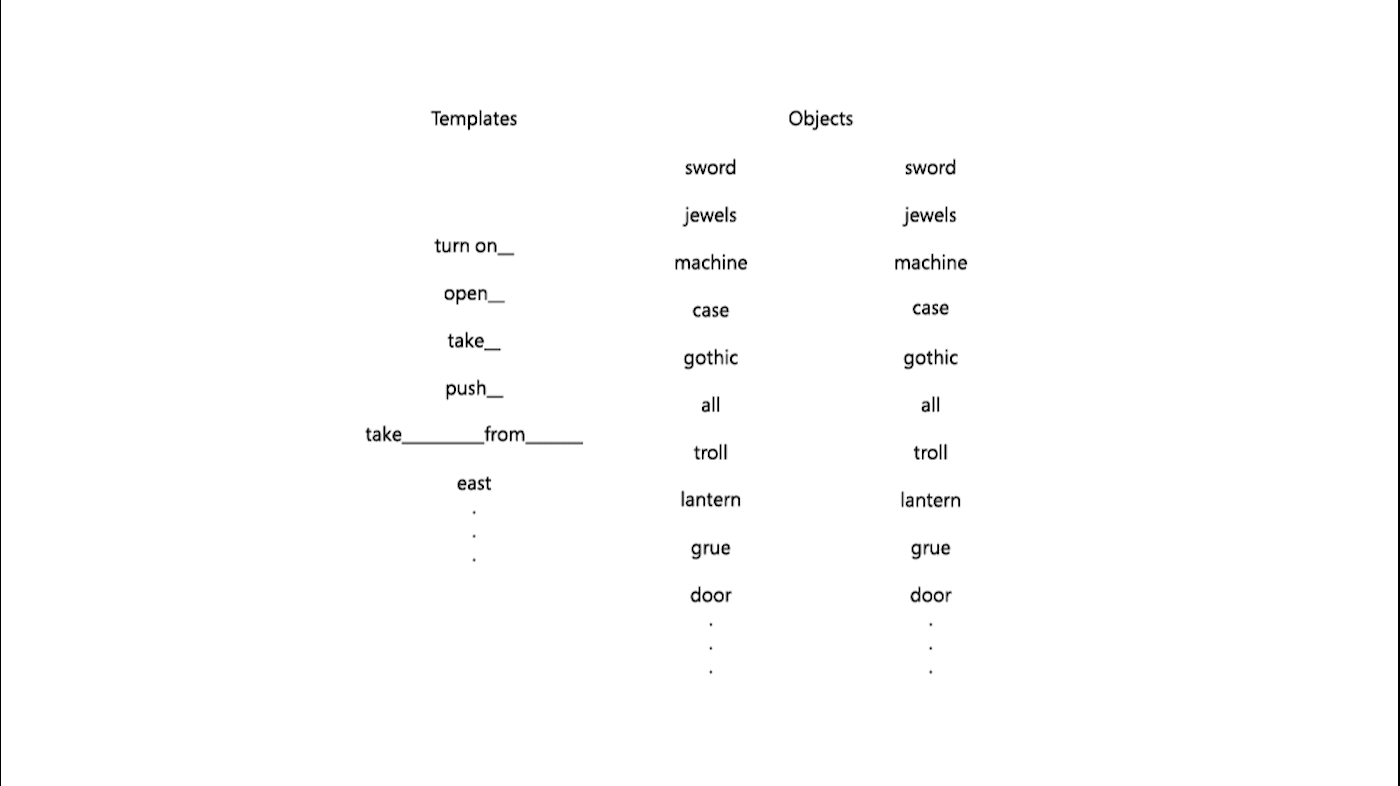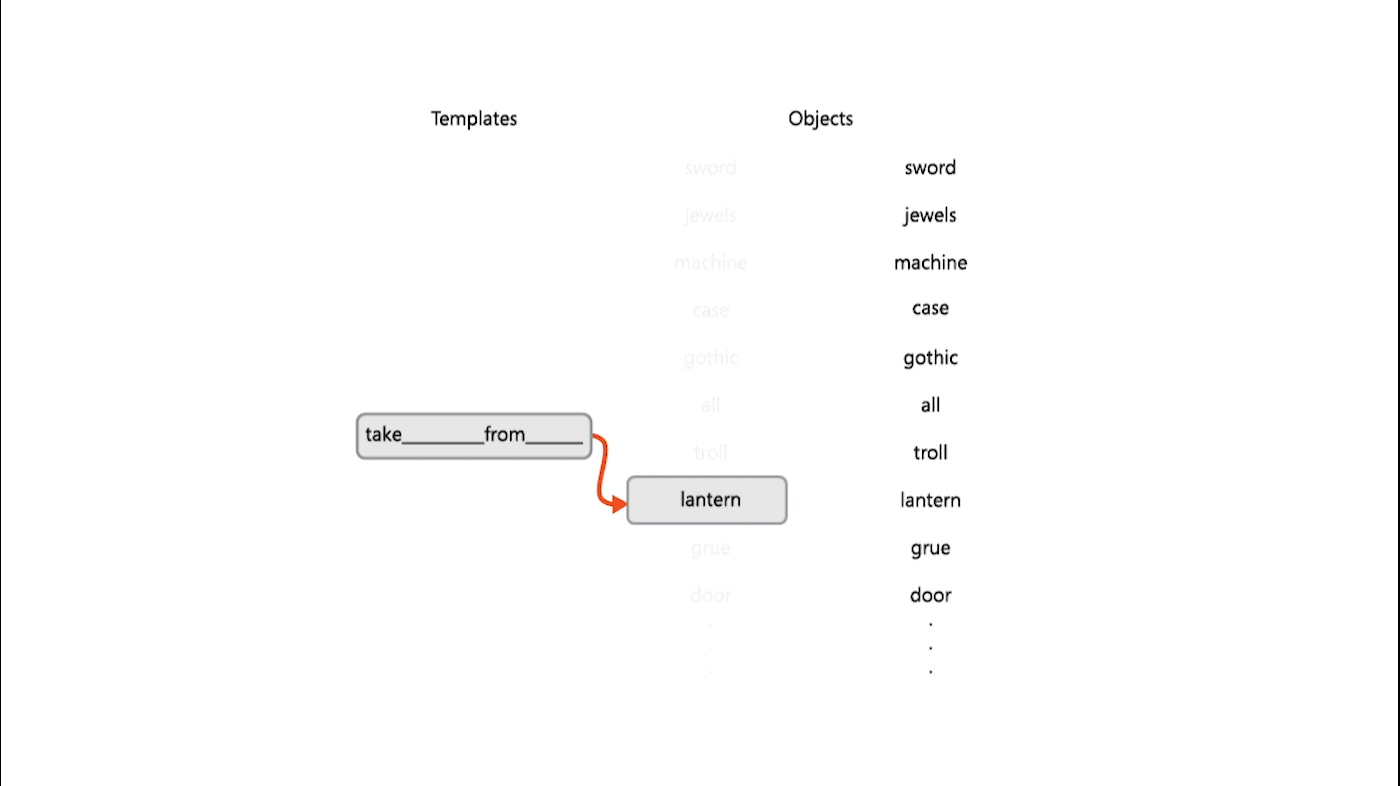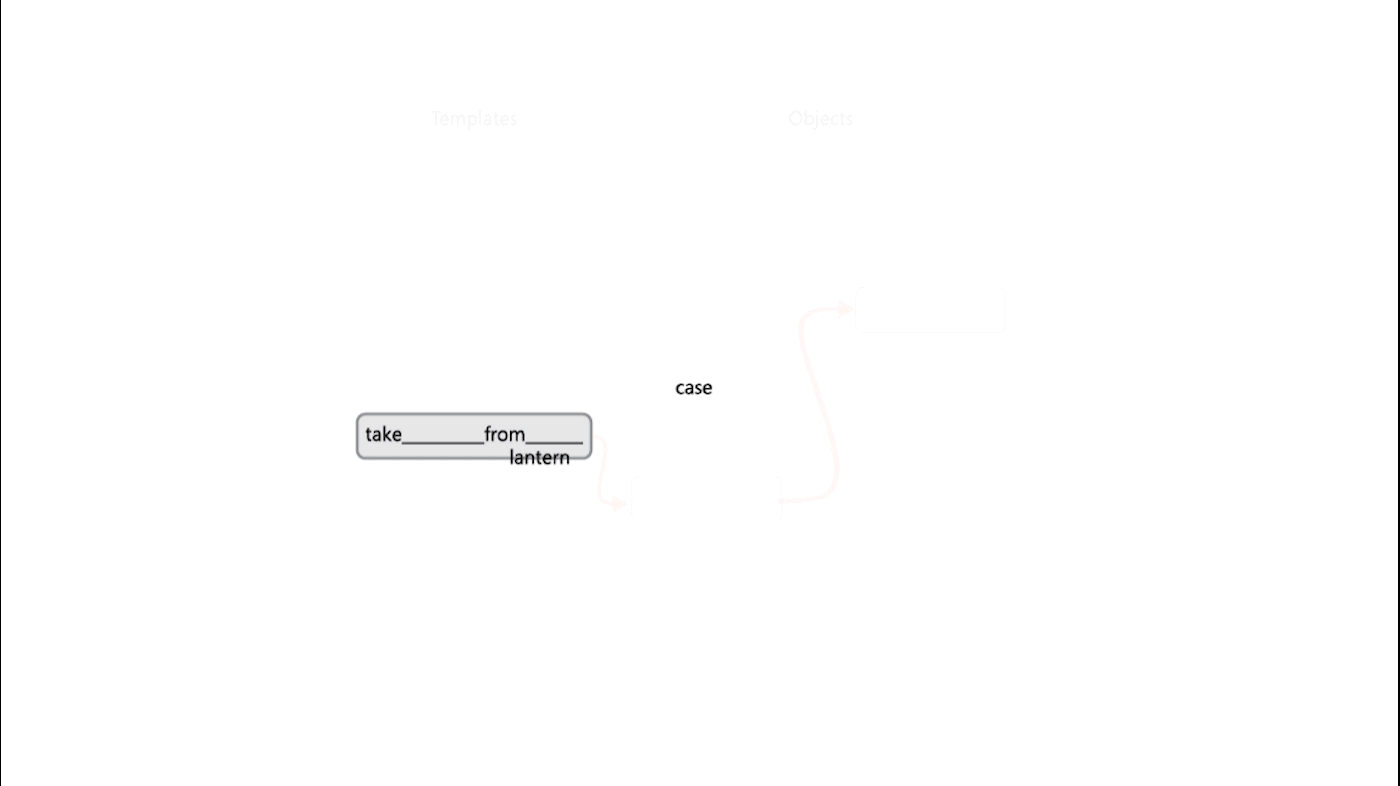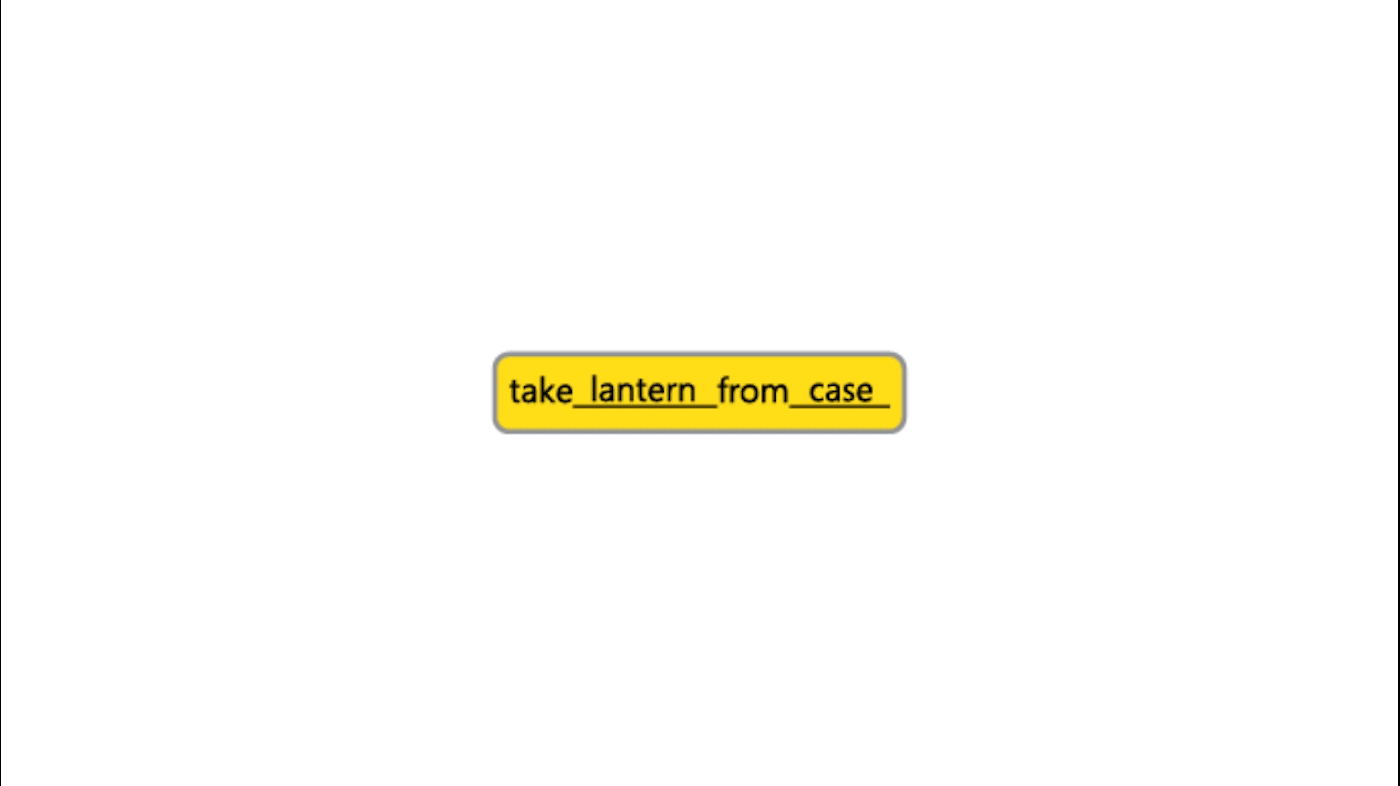
To address this challenge and help researchers take advantage of this valuable testing ground, we introduce Jericho, an open-source environment for agents to interface with IF games. Jericho supports template-based action generation in which an agent first selects the template of an action it wishes to execute and then selects words from the game’s vocabulary to fill in the blanks of the template, significantly reducing the action space and making the explore problem significantly more tractable. We’re presenting the paper, “Interactive Fiction Games: A Colossal Adventure,” at the 34th AAAI Conference on Artificial Intelligence.

Above is an excerpt from the interactive fiction (IF) game 9:05. IF games are text-based, providing a great opportunity for reinforcement learning agents to hone such skills as natural language understanding and generation, sequential decision-making, and reasoning. However, given large action spaces and other challenges, they have generally been difficult environments for RL agents to learn in. Jericho is a framework designed to make them more accessible.
Making IF games more approachable
Generating coherent language-based commands is a challenge for existing RL agents, as the space of possible commands grows combinatorially as shown by the example above. Existing agents commonly operate on action spaces with only tens or hundreds of possible actions and are largely unable to tractably explore action spaces presented by IF games without prohibitively long training times. Jericho helps address this challenge by revealing the list of action templates and vocabulary words that are recognized by the game, normally hidden from players in a non-human-readable format, for agents to choose from. The template example “take ___ from ___” could result in a successful action when combined with the vocabulary words lantern and case, for instance.
Providing templates and vocabulary can reduce the size of the action space by several orders of magnitude—from 240 billion possible actions to 98 million. Without game-specific vocabulary and templates, researchers might be inclined to provide their agents with an English dictionary from which to form commands—hence the exponentially large action space—or create a smaller vocabulary list, running the risk of unintentionally leaving out a game-specific key term, like lantern in Zork I. With Jericho’s vocabulary, you’re guaranteed to not miss crucial words.
In addition to template-based action generation, Jericho provides other features to make IF games more accessible to existing agents, including the following:
- World-object-tree representation: Because of the large number of locations, objects, and characters in many games and the possibility of puzzles requiring objects not present in the current location, agents need to develop ways to remember and reason about previous interactions. World-object-tree representations of the game state enumerate these elements.
- Fixed random seed to enforce determinism: By making games deterministic, where subsequent states are a direct result of a specific action taken by an agent, Jericho enables the use of targeted exploration algorithms like Go-Explore, which systematically build and expand a library of the visited states.
- Load/save functionality: This feature enables restoration of previous game states, enabling the use of planning algorithms like Monte-Carlo tree search.
- World-change detection and valid-action identification: This feature provides feedback on the success or failure of an agent’s last action to effect a change in the game state. Furthermore, Jericho can perform a search to identify valid actions, those that lead to changes in the game state.
Researchers can control the difficulty of the learning problem by picking and choosing which of Jericho’s features to employ.
Learning agents
We applied two learning agents to the games supported by the Jericho framework: Template-DQN (TDQN) and deep reinforcement relevance network (DRRN).
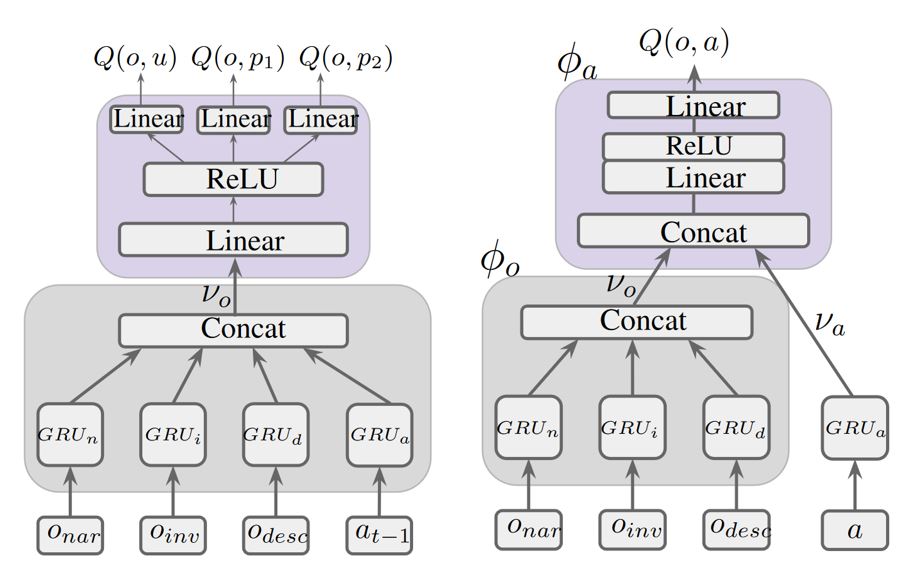
Two learning agents—TDQN (left) and DRRN (right)—were applied to the games supported by the Jericho framework. Leveraging Jericho features, they outperformed two baseline agents, demonstrating the framework can help make IF games more accessible to agents for improving language-based skills.
Both agents employ a common input representation, generated after each command and consisting of the current textual observation onar , inventory text oinv , and a description of the current location odesc (as given by a look command). The following is an example common input representation generated in Zork I following the command “open window”:
onar: With great effort, you open the window far enough to allow entry.
oinv: You are empty-handed.
odesc: You are behind the white house. A path leads into the forest to the east. In one corner of the house there is a small window which is slightly ajar.
While both agents (above) utilize common input representation, they differ in the methods of action selection. DRRN uses Jericho’s valid-action identification to estimate a Q-value for each of the valid actions a. It then either acts greedily by selecting the action with the highest Q-value or explores by sampling from the distribution of valid actions.
TDQN, based on the LSTM-DQN algorithm, generates separate Q-value outputs over the set of templates Q(o,u) and vocabulary words Q(o,p1) Q(o,p2). Thus, it must contend with the full template-based action space (98 million possible actions in Zork I). Jericho’s valid actions are also used during training as a supervised loss to help steer the agent toward commands that will yield state changes, but are not required for running the policy after training.
Both DRRN and TDQN use the load/save feature of Jericho to create the common input representation.
The results
We evaluated TDQN and DRRN across a diverse set of 32 games, including Zork I, with the aim of creating a reproducible benchmark to help the community track progress and move the state of the art. We compared the two learning agents to two non-learning baseline agents: a random agent that picks randomly from a set of 12 common IF actions at each step, and NAIL, a competition-winning heuristic-based IF agent. Neither agent used any of Jericho’s features.
We observed the following average completion rates; a completion rate of 100 percent means finishing the game with maximum score: the random algorithm, 1.8 percent; NAIL, 4.9 percent; TDQN, 6.1 percent; and DRRN, 10.7 percent. TDQN and DRRN accumulate significantly higher scores than the other agents, even when dealing with action spaces as large as 98 million. The success of these learning agents demonstrates Jericho is effective at reducing the difficulty of IF games and making them more accessible for RL agents to learn and improve language-based skills.
An exciting opportunity
Much improvement is needed before these algorithms and others can rival skilled humans at these games. We believe it will be necessary to incorporate better priors that convey human-like understandings of commonsense reasoning and knowledge representation to get there.
Without visuals grounding the language, IF games present an exciting opportunity to advance natural language understanding, natural language generation, and sequential decision-making in RL agents, which we see impacting such real-world applications as voice-activated personal assistants. To learn more about the work Microsoft Research is doing with IF games, check out TextWorld, a controlled framework for creating computer-generated IF games of varying levels of difficulty.
The post By making text-based games more accessible to RL agents, Jericho framework opens up exciting natural language challenges appeared first on Microsoft Research.