
This post has been republished via RSS; it originally appeared at: Microsoft Research.
Humans perceive the world through observing a large number of visual scenes around us and then effectively generalizing—in other words, interpreting and identifying scenes they haven’t encountered before—without heavily relying on labeled annotations for every single scene. One of the core aspirations in artificial intelligence is to develop algorithms and techniques that endow computers with a strong generalization ability to learn only from raw pixel data to make sense of the visual world, which aligns more closely with how humans process visual information.
Currently, self-supervised pretraining (SSP) is rising as an emerging research field, showing great success in approaching this problem. The goal of SSP is to learn general-purpose intermediate representations, with the expectation that the representations carry rich semantic or structural meanings and can be beneficial to a variety of practical downstream tasks.
SSP methods rely heavily on data augmentation to create different views of an image using image transformations, such as random crop (with flip and resize), color distortion, and Gaussian blur. However, image transformations are agnostic to the pretraining objectives, and it remains unknown how to augment views specifically based on the pretraining tasks themselves or how they affect the generalization of the learned models.
In this blog post, we first review SSP as a problem of predicting pseudo-labels—labels derived from the given data itself rather than with the help of human annotations. Based on this problem, we describe how to generate hard examples (HEXA), a family of augmented views whose pseudo-labels are difficult to predict. This leads to a novel SSP framework, and we develop two novel algorithms that create state-of-the-art performance on well-established vision tasks based on this framework. Please check out our paper, “Self-supervised Pre-training with Hard Examples Improves Visual Representations,” which elaborates on the details presented in this blog post.
Self-supervision: A pseudo-label view
The self-supervised task (also known as pretext task) leverages and exploits a variety of different weak signals existing intrinsically in images as pseudo-labels, maximizing the agreement between pseudo-labels and the learned representations. (These weak signals often come with the data for free.) For example, we might rotate images at random and train a model to predict how each input image is rotated.
The rotation prediction task is made-up, so the actual accuracy is unimportant, like the treatment of auxiliary tasks where we are concerned mostly with downstream task recognition accuracy. We expect the model to learn high-quality representations for real-world tasks, such as constructing an object recognition classifier with very few labeled samples. Most state-of-the-art SSP methods focus on designing novel pretext objectives, broadly categorized into two types:
- Type 1: contrastive learning. As a recently popular concept, contrastive learning is a framework that learns representations by maximizing agreement between differently augmented views of the same image via a contrastive loss in the latent space. In the instance discrimination pretext task, a binary pseudo-label is constructed: a positive pair is formed if both views are data-augmented versions of the same image, and if this is not the case, a negative pair is formed. MoCo (or MoCo-v2) and SimCLR are two known studies in this line, differing in how negative samples are maintained. OpenAI’s CLIP is also based on contrastive learning, but it’s built for image-text pairs collected from the web.
- Type 2: prototype learning. As probably one of the oldest unsupervised learning methods, prototype learning introduces a “prototype” as the centroid for a cluster formed by similar image views. The latent representations are fed into a clustering algorithm to produce the cluster assignments, which are subsequently used as “pseudo-labels” to supervise model update for representation learning. DeepCluster (or DeepCluster-v2) is a representative prototype learning work, alternating between two steps: feature clustering using K-means and feature learning by predicting these pseudo-labels.
Some recent works, such as Swapping Assignments between Views (SwAV) and Prototypical Contrastive Learning (PCL), combine these two types.
Spotlight: Academic programs

Working with the academic community
Hard examples as pretraining data
Data augmentation (DA) plays a vital role in SSP. Most existing methods synthesize views through random image transformations, without explicitly considering how difficult it is for the generated pseudo-labels to be predicted correctly by the model being pretrained. By contrast, we focus on studying hard examples, which are defined as augmented views whose pseudo-labels are difficult to predict. In Figure 1, we visually illustrate how hard examples are constructed from image transformations, detailing the derivation process below. Specifically, we consider two DA schemes of generating hard examples: adversarial examples and cut-mixed examples.

Adversarial examples. The adversarial examples are produced by adding perturbations on transformation-augmented views to fool the predicted pseudo-labels of a trained model by the most possible. By definition, adversarial examples tend to be “harder” than the original view for model prediction. Though adversarial examples in Figure 1c look visually indistinguishable with original views in Figure 1b, their corresponding pseudo-labels have been revised significantly, depending on how many perturbations are added.
Cut-mixed examples. Patches are cut and pasted among images to create a new example, where the ground truth pseudo-labels are also mixed proportionally to the area of the patches. For example, by mixing a dog image and a cat image in Figure 1a, the cut-mixed examples are “dog-cat” images shown in Figure 1d. One might imagine that cut-mixed examples are confusing for models (as the same goes for humans) since their contents are mixed from two sources.
In addition to standard image transformations, we add the adversarial and cut-mixed examples in the pretraining pipeline.
HEXA algorithms
With hard examples introduced as a new data augmentation scheme for SSP, we develop two novel algorithms to showcase how to construct them for different types of pretraining methods:
- HEXAMoCo. Based on MoCo-v2, the adversarial examples are produced for queries to flip the binary pseudo-label, the cut-mixed examples are performed between queries (the binary labels are mixed proportionally as well), and they leave keys unchanged.
- HEXADcluster. Based on DeepCluster-v2, the adversarial examples are produced for image views to fool the model to predict a wrong cluster index, while the cut-mixed examples are performed between different views. (The cluster indices are mixed proportionally as well.)
Both algorithms share a common goal: harder examples lie closer to the decision boundary, providing stronger learning signals for the models as illustrated in Figure 2 below.
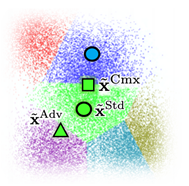
Figure 2: A visual Illustration example of augmented view space. Each circle ● indicates a transformation-augmented view. The adversarial example (triangle▲) fools the SSP model into making a prediction mistake, and the cut-mixed example (square ) is created between two standard augmentations.
) is created between two standard augmentations.
State-of-the-art performance
Our empirical study for SSP is performed on the ImageNet dataset. All experiments are conducted with ResNet-50 and pretrained in 200 or 800 epochs. The competitive state-of-the-art methods are collected from MoCo-v2, DeepCluster-v2, SwAV, BYOL, InfoMin, PCL, PIRL, SimCLR, BigBiGAN, CMC, CPC, Jigsaw, and Instance Discrimination.
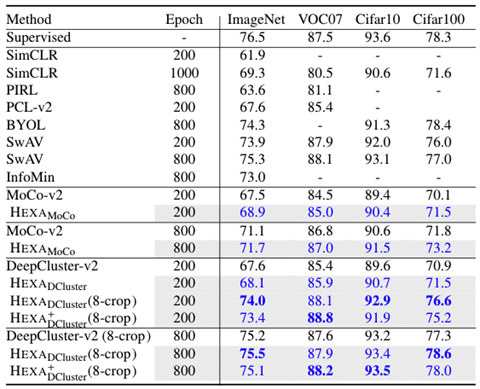
Linear evaluation. To evaluate learned representations, we first follow the widely used linear evaluation protocol, where a linear classifier is trained on top of the frozen base network and the validation accuracy is used to measure the quality of the representations. Table 1 shows the results.
It is interesting that DeepCluster-v2 is slightly better than MoCo-v2, indicating that the traditional prototype methods can be as effective as the popular contrastive methods with the same pretraining epochs and data augmentation strategies. Notably, HEXA variants consistently outperform their contrastive and prototype baselines, showing that the proposed hard examples can effectively improve the learned visual representations in SSP.
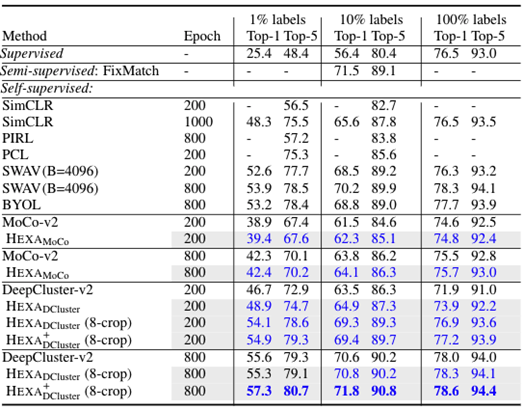
Fine-tuning evaluation. We now fine-tune the pretrained model to downstream vision tasks, such as image classification. Depending on the availability of task-specific data, we use either semi-supervised learning or supervised learning for fine-tuning. Specifically, we select a subset (1% or 10%) or use the full set (100%) of ImageNet training data and fine-tune the entire model on these datasets. Besides self-supervised methods, we also compared our method with methods specifically designed for semi-supervised learning, including VAT, S4L, UDA, FixMatch.
Table 2 reports the Top-1 and Top-5 accuracy on the ImageNet validation set. HEXA improves its counterparts, MoCo-v2 and DeepCluster-v2, in all cases. By fine-tuning for 20 epochs, HEXA reaches 78.6% Top-1 accuracy, outperforming the supervised approach (76.5%) while using the same ResNet-50 architecture by a large margin (2.1% absolute recognition accuracy).
Scaling up HEXA to achieve few-shot learning
With HEXA, we have seen the power of constructing hard examples as pretraining data in improving self-supervised image representation learning. One interesting direction of future work stems from HEXA showcasing that both adversarial and cut-mixed hard examples improve pretraining. This idea can be generalized to incorporate more types of hard examples, such as mix-up examples. Our results on fine-tuning the full ImageNet dataset also show that combining self-supervised learning and standard supervised learning is a very promising approach to improve learned vision backbone.
Another future research direction is to scale up this approach to billions of images, such as the scale in Big Transfer. Both SSP and OpenAI CLIP collectively contribute to the same goal: general visual representations with “few-shot” or even “zero-shot” learning capacities. The two methods are orthogonal: SSP conducts unsupervised learning on image-image pairs, while CLIP conducts supervised learning on image-text pairs that are freely available on the web. A better visual representation can be learned—one that leverages both powers. HEXA can be explored in this joint-learning setting to improve the performance.
Acknowledgments
This research was conducted by Chunyuan Li, Xiujun Li, Lei Zhang, Baolin Peng, Mingyuan Zhou, and Jianfeng Gao. Additional thanks go to the entire Philly team inside Microsoft who provided us with the computing platform to do this research. The implementation in our experiments depends on open-source GitHub repositories; we acknowledge all the authors who made their code public, which tremendously accelerates our project progress.
The post HEXA: Self-supervised pretraining with hard examples improves visual representations appeared first on Microsoft Research.