
This post has been republished via RSS; it originally appeared at: Microsoft Research.
Last month, the DeepSpeed Team announced ZeRO-Infinity, a step forward in training models with tens of trillions of parameters. In addition to creating optimizations for scale, our team strives to introduce features that also improve speed, cost, and usability. As the DeepSpeed optimization library evolves, we are listening to the growing DeepSpeed community to learn how users are engaging with the library and to take on new frontiers to expand the capabilities of DeepSpeed. One important aspect of large AI models is inference—using a trained AI model to make predictions against new data. But inference, especially for large-scale models, like many aspects of deep learning, is not without its hurdles.
Two of the main challenges with inference include latency and cost. Large-scale models are extremely computationally expensive and often too slow to respond in many practical scenarios. Moreover, these models with tens or hundreds of billions of parameters, trained with aggregated memory from multiple GPUs, simply become too large to fit on a single GPU’s device memory for inference. For example, a single NVIDIA V100 Tensor Core GPU with 32 GB of memory can only fit up to a 10-billion-parameter model for inference, and the latency is limited by single GPU performance. To accommodate even bigger models, and to achieve faster and cheaper inference, we have added DeepSpeed Inference—with high-performance multi-GPU inferencing capabilities.
DeepSpeed Inference at a glance: As requested by many users, DeepSpeed rolls out high-performance inference support for large Transformer-based models with billions of parameters, like those at the scale of Turing-NLG 17B and Open AI GPT-3 175B. Our new technologies for optimizing inference cost and latency include:
- Inference-adapted parallelism allows users to efficiently serve large models by adapting to the best parallelism strategies for multi-GPU inference, accounting for both inference latency and cost.
- Inference-optimized CUDA kernels boost per-GPU efficiency by fully utilizing the GPU resources through deep fusion and novel kernel scheduling.
- Effective quantize-aware training allows users to easily quantize models that can efficiently execute with low-precision, such as 8-bit integer (INT8) instead of 32-bit floating point (FP32), leading to both memory savings and latency reduction without hurting accuracy.
Together, DeepSpeed Inference shows 1.9–4.4x latency speedups and 3.4–6.2x throughput gain and cost reduction when compared with existing work.
Affordable, fast, and accurate training: Beyond inference, another key ask from DeepSpeed users is to reduce training time of large-scale models without adding additional hardware. In this release, we introduce new compressed-training strategies to support fast and low-cost training while simultaneously delivering high accuracy. We also provide a new profiling tool to identify training performance bottlenecks. These three technologies include:
- Compressed training exploits coarse-grained sparsity in Transformer layers via Progressive Layer Dropping during training to obtain reduced training cost, which yields 2.8x faster convergence speed without hurting accuracy.
- 1-bit LAMB enables communication-efficient large-scale training with 4.6x communication volume reduction, which accelerates training of large-scale models even in clusters with low-bandwidth interconnects.
- DeepSpeed Profiler performance tool shows model complexity and training efficiency to help users identify performance bottlenecks.
Multi-GPU inference with DeepSpeed for large-scale Transformer models
While DeepSpeed supports training advanced large-scale models, using these trained models in the desired application scenarios is still challenging due to three major limitations in existing inference solutions: 1) lack of support for multi-GPU inference to fit large models and meet latency requirements, 2) limited GPU kernel performance when running inference with small batch sizes, and 3) difficulties in exploiting quantization, which includes both quantizing the model to reduce the model size and latency as well as supporting high-performance inference of quantized models without specialized hardware.
To handle these challenges, we introduce DeepSpeed Inference, which seamlessly adds high-performance inference support to large models trained in DeepSpeed with three key features: inference-adapted parallelism for multi-GPU inference, inference-optimized kernels tuned for small batch sizes, and flexible support for quantize-aware training and inference kernels for quantized models.
Inference-adapted parallelism
Large models can require more memory than what is available on a single GPU. Therefore, multi-GPU parallelism is a necessary first step to enable inference for these large models. In addition, by splitting the inference workload across multiple GPUs, multi-GPU inference can also reduce inference latency to meet the stringent latency requirements of production workloads. However, the selection of parallelism degree needs to be judicious. Multi-GPU parallelism introduces cross-GPU communication, and it can also reduce per-GPU computation granularity. Both factors impact inference efficiency, resulting in diminishing latency reduction when parallelism degree is too large—eventually increasing latency instead of decreasing it. Therefore, to meet latency requirements while reducing parallelism overhead, it is necessary to tune the parallelism degree and identify the optimal value for a given model architecture and hardware platform. We call this ability inference-adapted parallelism.
DeepSpeed offers seamless support for inference-adapted parallelism. Once a Transformer-based model is trained (for example, through DeepSpeed or HuggingFace), the model checkpoint can be loaded with DeepSpeed in inference mode where the user can specify the parallelism degree. Based on that, DeepSpeed Inference automatically partitions the model across the specified number of GPUs and inserts necessary communication required to run multi-GPU inference for the Transformer model—no model code change is required from the user. The user can tune the model performance to meet their latency and efficiency requirements by simply changing the parallelism degree.
DeepSpeed Inference currently supports tensor slicing–based multi-GPU parallelism for Transformer-based models, both within and across nodes, and we plan to add support for pipeline parallelism soon.
Inference-optimized kernels
There are two major challenges in achieving good efficiency during inference due to small batch size: 1) kernel invocation time and main memory latency become major bottlenecks due to limited work in each kernel; and 2) the default GeMM (General Matrix Multiplication) library is not well tuned for extremely small batch sizes, resulting in sub-optimal performance. DeepSpeed Inference offers inference kernels for Transformer blocks with two innovative optimizations that address these challenges to achieve significant latency reduction and throughput improvement.
Deep fusion: DeepSpeed Inference can fuse multiple operators into a single kernel to reduce the number of kernel invocations and latency of main memory access across kernels. While kernel-fusion is a common technique that has been used in the PyTorch JIT compiler, Tensorflow XLA, and others, the deep fusion in DeepSpeed is different. Unlike existing fusion techniques that primarily fuse element-wise operations, deep fusion in DeepSpeed can fuse element-wise operations, matrix multiplications, transpositions, and reductions all into a single kernel, significantly reducing number of kernel invocations as well as main memory access to reduce main memory access latency.
Inference-customized GeMM: Small batch sizes result in skinny GeMM operations where the activations are a skinny matrix, while the parameters are much larger matrices compared to the activations, and the total computation per parameter is limited by the batch size. As a result, the performance of GeMM is dominated by the time it takes to read the parameters from main memory rather than the computation time itself. Therefore, to achieve the best performance, DeepSpeed Inference kernels are fine-tuned to maximize the memory bandwidth utilization for loading the parameters. This specialization allows DeepSpeed Inference kernels to achieve up to 20 percent better performance than NVIDIA cuBLAS for inference workloads with batch sizes 1–10.
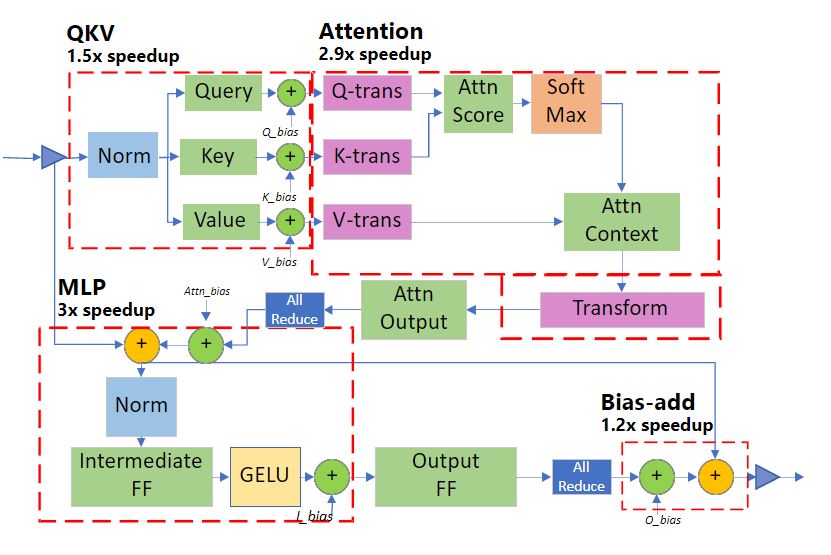
Generic and specialized Transformer kernels
DeepSpeed Inference consists of two sets of Transformer kernels that incorporate the aforementioned optimizations:
- Generic Transformer replaces individual PyTorch operators within Transformer such as LayerNorm, Softmax, and bias-add with highly optimized DeepSpeed versions created using deep fusion.
- Specialized Transformer takes deep fusion one step further by creating fused schedules that not only fuse micro-operators within a PyTorch macro-operator (such as Softmax), but also fuse multiple macro-operators (such as Softmax and LayerNorm together with transpose op, and even GeMM). The fusion structure of our specialized Transformer kernel is shown in Figure 1.
Flexible quantization support
To further reduce the inference cost for large-scale models, we created the DeepSpeed Quantization Toolkit, which involves two parts:
Mixture of Quantization (MoQ) is a novel quantize-aware training method designed under the observation that inference time for large Transformer-based models with small batch sizes is primarily dominated by the parameter loading time from main memory. It is therefore sufficient to quantize just the parameters to achieve inference performance improvements, while the activation can be computed and stored in FP16. With this insight, MoQ uses the existing FP16 mixed-precision training pipeline in DeepSpeed to support seamless quantization of parameters during training. It does so by simply converting the FP32 parameter value to lower precision (INT4, INT8, and so on). It then stores them as FP16 parameters (FP16 datatype but with values mapping to lower precision) during the weight update.
This approach has three advantages: 1) it does not require any code change from users, 2) it does not require using actual low-precision datatypes or specialized kernels during training, and 3) it allows us to dynamically adjust the number of quantization bits as the training progresses, offering the ability to use flexible quantization schedules and policies. For example, MoQ can leverage second-order information during training, like those shown in Q-BERT, to adaptively adjust the quantization schedule and target bits for each model layer.
With unquantized activations, flexible quantization schedule, and adaptive targets using second-order information, MoQ is much more robust in terms of accuracy when compared to conventional quantization approaches for the same compression ratio.
High-performance INT8 inference kernels are extensions of generic and specialized Transformer kernels discussed earlier, designed to work together with INT8 parameters trained using MoQ. These kernels offer the same set of optimizations as the FP16 versions, but instead of loading FP16 parameters from main memory, they load INT8 parameters. Once the parameters are loaded to registers or shared memory, they are converted on-the-fly to FP16 before they are used in inference computation. Loading INT8 instead of FP16 reduces the data movement from main memory by half, resulting in up to 2x improvement in inference performance.
Ease of use: A seamless pipeline from training to inference
DeepSpeed provides a seamless pipeline to leverage these optimizations, prepare trained models, and deploy the models for fast and cost-efficient inference as shown in Figure 2.

# DeepSpeed MoQ
import deepspeed
if args.MoQ:
model, ... = deepspeed.initialize(
args=args,
model=model,
config_params=MoQ_config,
...)
# Run training with MoQ
# Initialize the model with DeepSpeed-Inference
# using inference-kernels and configuring the parallelism setting
import deepspeed.module_inject as module_inject
injection_policy={original_layer_implementation:
module_inject.replace_policy....}
model = deepspeed.init_inference(model,
mp_size=parallel_degree,
mpu=mpu,
checkpoint=[checkpoint_list],
dtype=args.dtype,
injection_policy=injection_policy,
)Figure 2: The DeepSpeed Inference pipeline and the inference API pseudocode for the different stages of the pipeline. MoQ can be used to quantize model checkpoints as an optional preprocessing phase before inference, where the quantization configurations, including desired quantization bits and schedule, are provided via a JSON file (MoQ_config). Before serving the model, we adapt the parallelism and inject either the floating-point or quantized inference kernels.
Latency speedups on open-source models with publicly available checkpoints
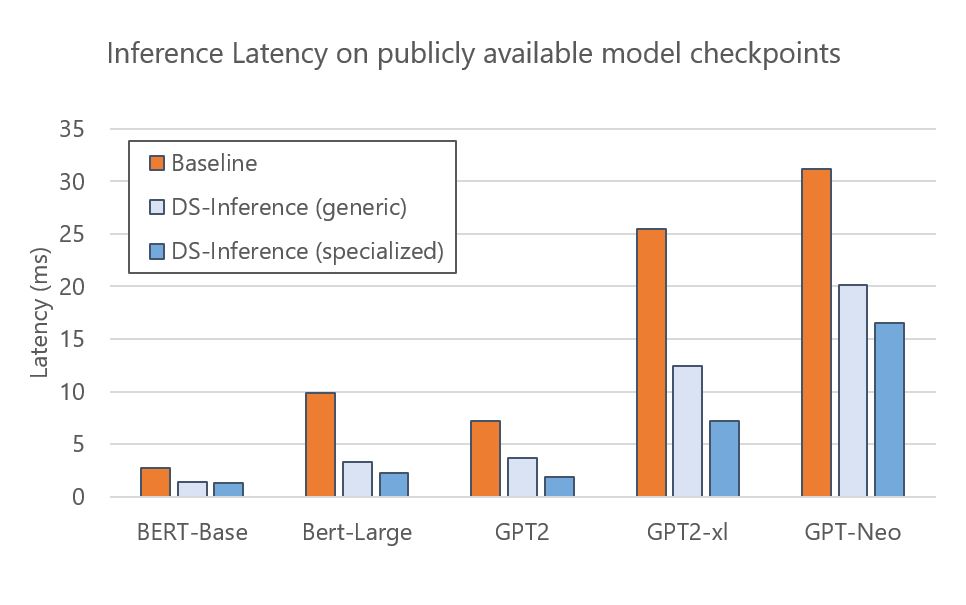
DeepSpeed Inference speeds up a wide range of open-source models: BERT, GPT-2, and GPT-Neo are some examples. Figure 3 presents the execution time of DeepSpeed Inference on a single NVIDIA V100 Tensor Core GPU with generic and specialized Transformer kernels respectively. The results show that the generic kernels provide 1.6–3x speedups to these models over the PyTorch baseline. We can further reduce latency through the specialized kernels, achieving 1.9–4.4x speedups. Since the checkpoints of these models are publicly available, DeepSpeed users can leverage inference benefits of these models directly and easily by following our tutorial.
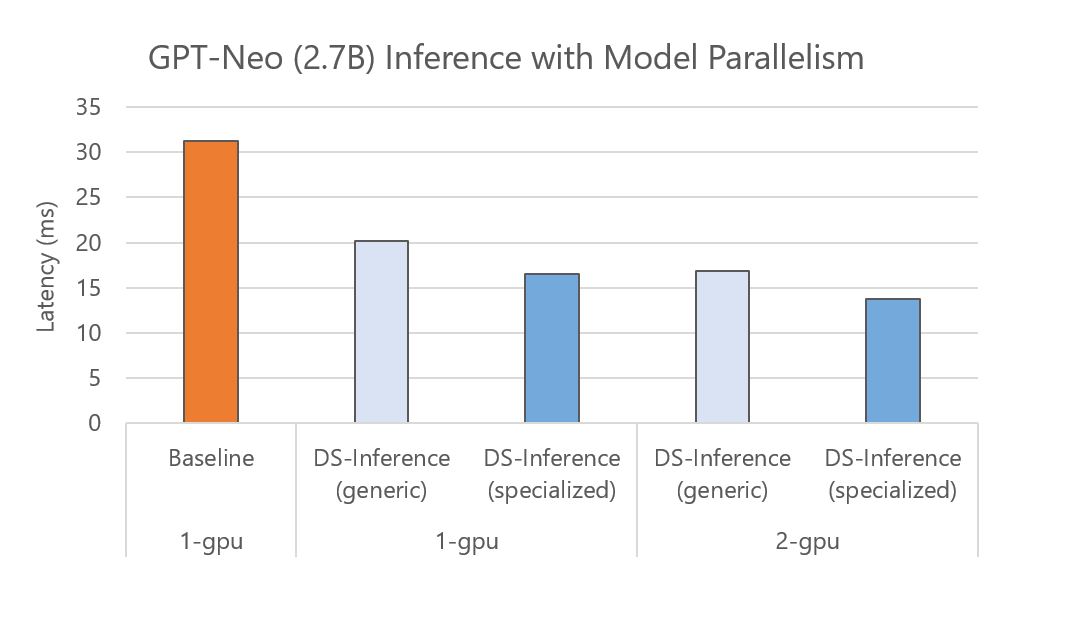
DeepSpeed Inference also supports fast inference through automated tensor-slicing model parallelism across multiple GPUs. In particular, for a trained model checkpoint, DeepSpeed can load that checkpoint and automatically partition model parameters across multiple GPUs for parallel execution. Figure 4 shows the execution time of GPT-Neo (2.7B) for baseline and DeepSpeed Inference (DS-Inference) on one GPU and two GPUs with two-way model parallelism. On one side, DeepSpeed Inference speeds up the performance by 1.6x and 1.9x on a single GPU by employing the generic and specialized Transformer kernels, respectively. On the other side, we can further decrease the latency by using automated tensor slicing to partition the model across two GPUs. Altogether, we achieve 2.3x speedup by combining the impact of the customized-inference kernels with the model-parallel inference execution.
Spotlight: Webinar series

Microsoft research webinars
Boosting throughput and reducing inference cost for large Transformer models
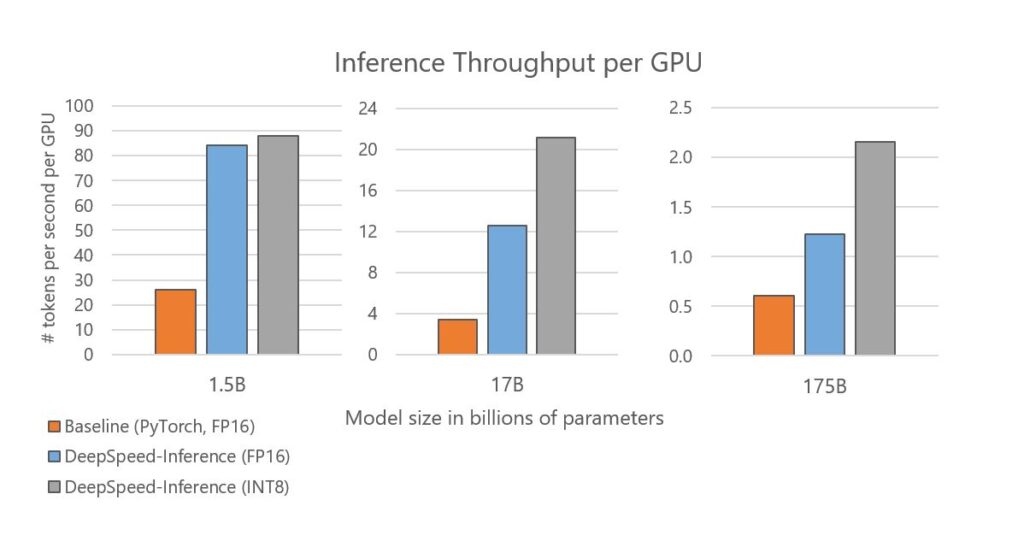
Beyond optimizing latency, DeepSpeed Inference also boosts throughput and reduces inference cost, and its benefit is even greater for large models with tens of billions and hundreds of billions of parameters. Figure 5 shows the inference throughput per GPU for the three model sizes constructed by varying the number of Transformer layers and hidden sizes to match the existing network architecture: GPT-2 (1.5B), Turing-NLG (17B), and GPT-3 (175B). DeepSpeed Inference improves per-GPU throughput by 2–3.7x when using the same precision of FP16 as the baseline. We further observe an improved throughput after enabling quantization. Notably, we achieve a throughput improvement of 3.4x for GPT-2, 6.2x for Turing-NLG, and 3.5x for a model that is similar in characteristics and size to GPT-3, which directly translates to a 3.4–6.2x reduction of inference cost on serving these large models. In addition, we achieve these throughput and cost improvements while optimizing latency simultaneously. Using the Turing-NLG 17B model as an example, Figure 7 below shows that DeepSpeed Inference also reduces latency—it incurs lower latency even when using one or two GPUs, compared with the baseline that uses four GPUs.
Inference cost reduction is also accomplished by reducing the number of GPUs for hosting large models as shown in Figure 6. The optimized GPU resources come from using inference-adapted parallelism, which allows users to adapt the model and pipeline parallelism degree from the trained model checkpoints, and shrinking model memory footprint by half with INT8 quantization. As shown in Figure 6, DeepSpeed Inference uses 2x less GPUs to run inference for the 17B model size by adapting the parallelism. Together with INT8 quantization, DeepSpeed uses 4x and 2x fewer GPUs for 17B and 175B model sizes respectively.
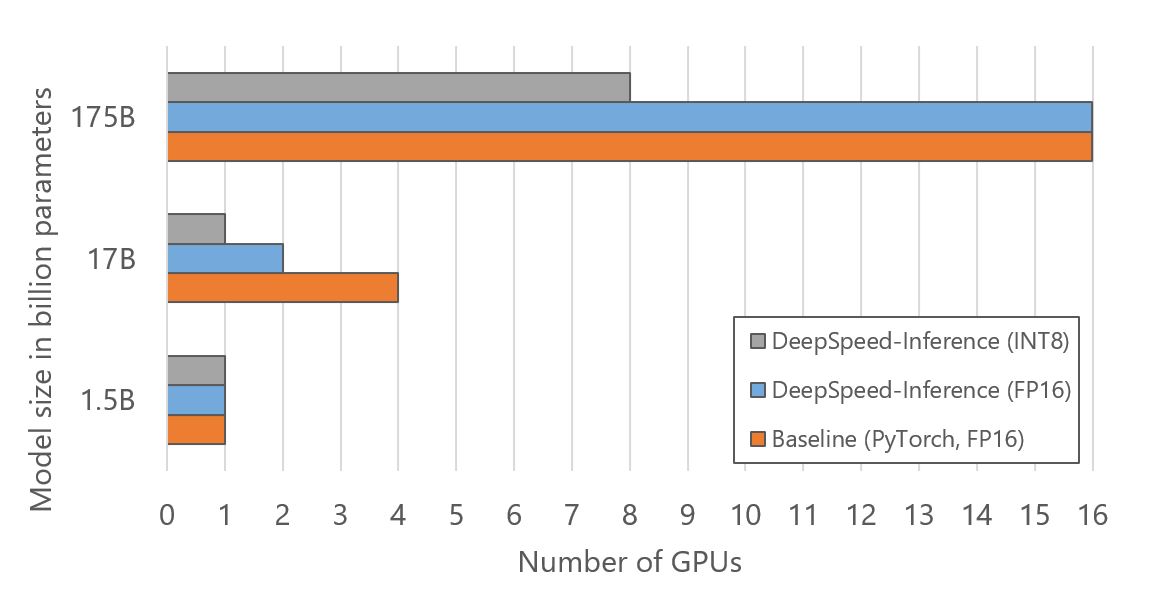
Impact of DeepSpeed quantization on reducing inference cost and improving quantized model accuracy
Latency and cost reduction: Quantization can be combined with inference-adapted parallelism and optimized kernels to reduce latency while saving costs. Figure 7 below shows the latency of Turing NLG, a 17-billion-parameter model. Compared with PyTorch, DeepSpeed achieves 2.3x faster inference speed using the same number of GPUs. DeepSpeed reduces the number of GPUs for serving this model to 2 in FP16 with 1.9x faster latency. With MoQ and inference-adapted parallelism, DeepSpeed is able to serve this model on a single GPU in INT8 with 1.7x latency reduction and 6.2x cost savings.

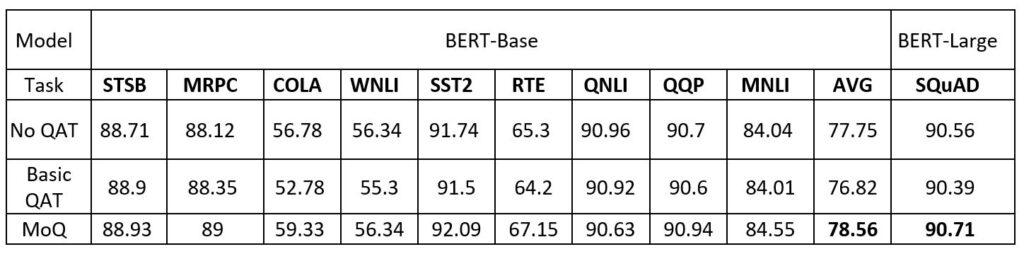
High quantization accuracy: Our MoQ approach compresses models with high accuracy. To evaluate its effectiveness, we conduct experiments on GLUE benchmark using BERT-Base and SQuAD using BERT-Large. Table 1 compares the accuracy results among baseline with FP16 parameters without quantization (No QAT); Basic QAT, which simply reduces the precision to INT8 from the beginning of the quantize-aware training; and MoQ, which dynamically reduces precision through a predefined schedule (we add the schedule configs in the MoQ tutorial). By using Basic QAT, the accuracy of 8-bit quantization is often inferior to the baseline and suffers from a drop of 0.93 (77.75 vs. 76.82) points in average accuracy (AVG). In contrast, MoQ powers 8-bit quantization to obtain comparable and sometimes higher accuracy than the baseline, demonstrating the effectiveness of MoQ.
DeepSpeed Inference release plan
DeepSpeed Inference is at its early stage, and we plan to release it gradually as features become ready. As the first step, we are releasing the core DeepSpeed Inference pipeline consisting of inference-adapted parallelism, inference-optimized generic Transformer kernels, and quantize-aware training integration in the next few days. Over time, we plan to extend our offerings with the specialized Transformer kernels as well as other inference related optimizations.
We hope you will try out DeepSpeed Inference. Please find the code and tutorials in the DeepSpeed GitHub, and let us know what you think. We highly value your feedback for our continued development.
Affordable, fast, and accurate training of large-scale models
Compressed training with Progressive Layer Dropping: 2.5x faster training, no accuracy loss
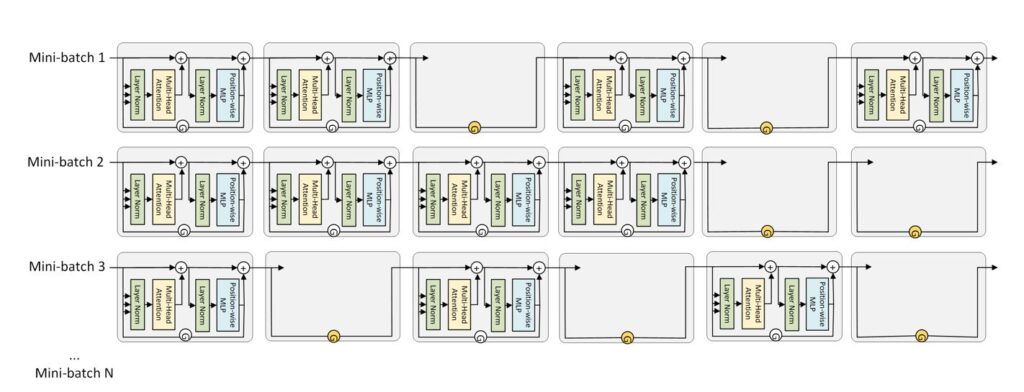
DeepSpeed now offers compressed training, which accelerates training of Transformer networks by sparsely updating model weights while achieving comparable accuracy of dense training. We achieve this with Progressive Layer Dropping, an algorithm that dynamically switches off Transformer layers during each iteration based on a progressive schedule that accounts for model sensitivity along both the temporal and depth dimensions (as shown in Figure 8).
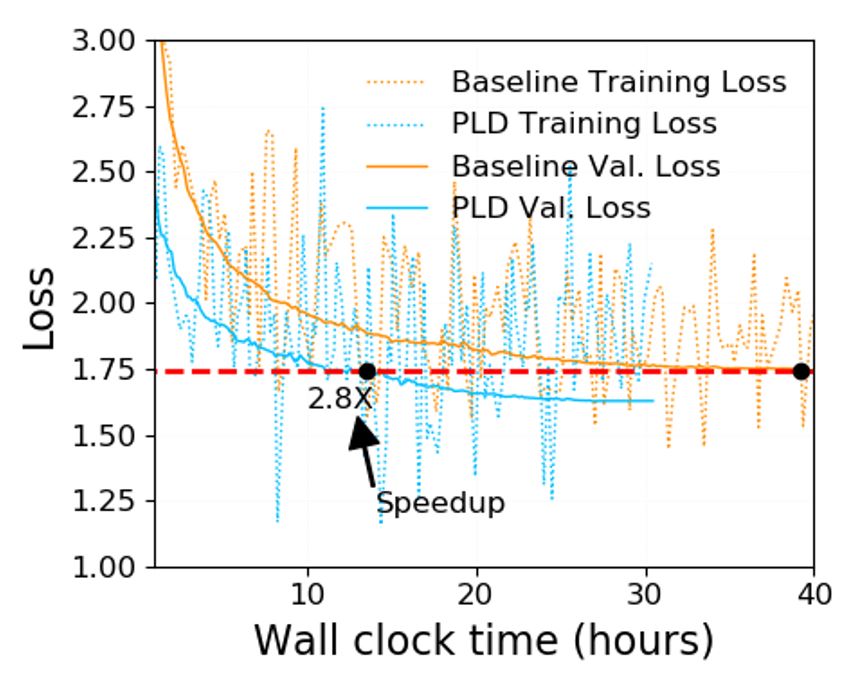
Progressive Layer Dropping reduces time per sample by an average of 24 percent—as it leverages dynamic sparsity during training to process and update only a fraction of model weights with each batch of inputs. Moreover, when combined with the Pre-LN Transformer architecture, Progressive Layer Dropping facilitates training with more aggressive learning rates, achieving the same pretraining validity with 53 percent fewer training samples. The combination of these two factors yields 2.8x speedup in end-to-end wall-clock training time. Finally, models pretrained with Progressive Layer Dropping are equipped with strong knowledge transferability, achieving a comparable GLUE score than the baseline but with a much faster speed. For more information on Progressive Layer Dropping, please read our tutorial and paper for technical details.
1-bit LAMB: 4.6x communication volume reduction and up to 2.8x end-to-end speedup
Communication is a major bottleneck for training large models (like BERT and GPT-3) with hundreds or even thousands of GPUs. This is especially true on commodity systems with limited-bandwidth TCP interconnect networks. The two approaches that address this include:
- Communication compression. Last September, we announced 1-bit Adam, a communication compression algorithm that reduces communication volume by up to 5x while achieving similar convergence efficiency to Adam.
- Large batch size training. In contrast to reducing volume, another approach to reducing communication is to decrease number/frequency of communications through large-batch optimization (such as the LAMB algorithm).
However, we find that simply using one of the techniques is not sufficient to solve the communication challenge, especially on low-bandwidth Ethernet networks. Combining large-batch optimization and communication compression sounds promising, but we find that existing compression strategies cannot be directly applied to LAMB due to its unique adaptive layer-wise learning rates.
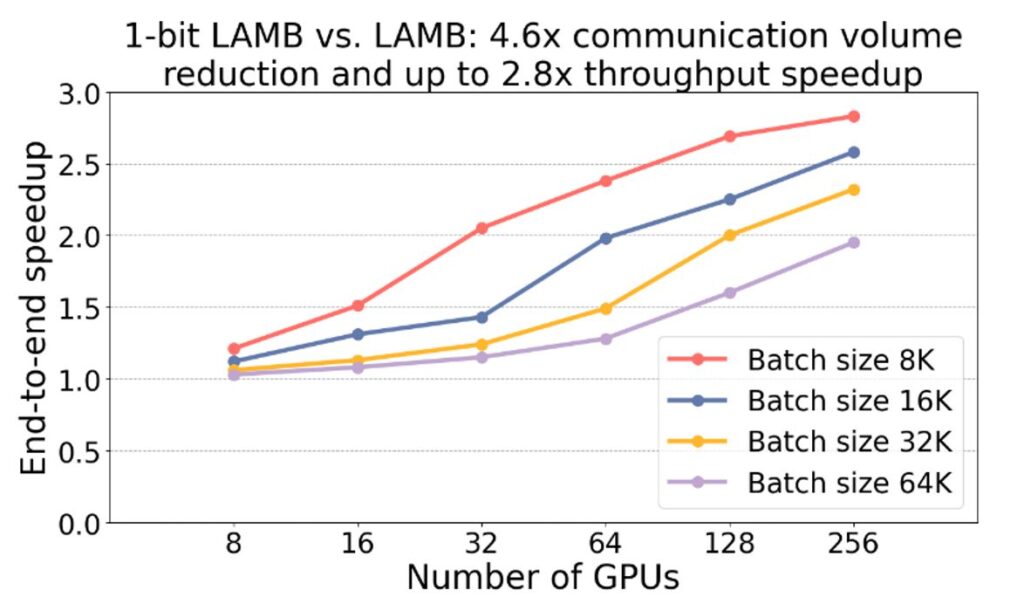
To this end, we present a new communication-efficient algorithm, 1-bit LAMB, which introduces a novel way to support compressed communication in the context of large-batch optimization with adaptive layer-wise learning rates. We also introduce new system implementations for compressed communication (for both 1-bit LAMB and 1-bit Adam) using the NVIDIA Collective Communications Library (NCCL) backend of PyTorch Distributed. This provides better performance and usability compared to our prior Message Passing Interface–based implementation. For BERT-Large pretraining tasks with batch sizes from 8K to 64K, our evaluations on up to 256 GPUs demonstrate that 1-bit LAMB with NCCL backend achieves 4.6x communication volume reduction, up to 2.8x training throughput speedup while retaining the same downstream task accuracy as LAMB under the same number of training samples. To learn more about how to use 1-bit LAMB, please read our tutorial, and for technical details read our paper.
Performance bottleneck analysis with DeepSpeed Flops Profiler
Effective use of hardware resources is critical for good performance, but performance inefficiency for large-scale model training and inference is often hard to spot and attribute to specific module components. DeepSpeed Flops Profiler helps users easily measure both the model training/inference speed (latency, throughput) and efficiency (floating point operations per second, also called FLOPS) of a model and its submodules, exposing inefficiencies in existing implementations.
Identifying performance gaps: The first step towards analyzing the performance of large-scale deep learning models is to identify whether there exist any performance inefficiencies that require further optimizations. As an example, the NVIDIA Tesla V100 GPU provides a total of 640 Tensor Cores and offers a theoretical peak performance of 125 TFLOPS/sec (tera-floating point operations per second). But is the training or inference workload efficiently using those cores? To answer this question, DeepSpeed Flops Profiler automatically calculates the number of parameters and tracks the execution time of each submodule. It also provides aggregated TFLOPS/s of a model, which can help to identify if a performance gap exists (for example, <10 percent peak performance) in a given current model execution and whether further optimizations are needed.
Identifying performance bottlenecks: DeepSpeed Flops Profiler tracks detailed submodule runtime information and presents that fine-grained information in a way that helps programmers eliminate them. For example, by providing the fine-grained FLOPS/sec information for individual tensor operators or sublayers, programmers can make decisions on whether multiple operators should be fused together to reduce overhead from kernel invocation or a specific operator should be optimized through custom optimization.
DeepSpeed Flops Profiler can be easily enabled through the DeepSpeed configuration file. Please refer to our tutorial for more details. We are also under active development to add more features to the profiler. Stay connected for more exciting features to be added soon.
About the DeepSpeed Team:
We are a group of system researchers and engineers— Samyam Rajbhandari, Reza Yazdani Aminabadi, Elton Zheng, Minjia Zhang, Conglong Li, Cheng Li, Ammar Ahmad Awan, Jeff Rasley, Olatunji Ruwase, Shaden Smith, Arash Ashari, Niranjan Uma Naresh, Jeffrey Zhu, Yuxiong He (team lead)—who are enthusiastic about performance optimization of large-scale systems. We have recently focused on deep learning systems, optimizing deep learning’s speed to train, speed to convergence, and speed to develop!
If this type of work interests you, the DeepSpeed team is hiring both researchers and engineers! Please visit our careers page.
The post DeepSpeed: Accelerating large-scale model inference and training via system optimizations and compression appeared first on Microsoft Research.