
This post has been republished via RSS; it originally appeared at: Microsoft Research.

AI agents capable of understanding natural language, communicating, and accomplishing tasks hold the promise of revolutionizing the way we interact with computers in our everyday lives. Text-based games, such as the Zork series, act as testbeds for development of novel learning agents capable of understanding and interacting exclusively through language. Beyond requiring the use of imagination and myriad concepts of everyday life to solve, these fictional world–based narratives are also a safe sandbox for AI testing that avoids the expense of collecting user data and the risk of users having a bad experience interacting with agents that are still learning.
In this blog post, we share two papers that explore reinforcement learning methods to improve semantic understanding in text agents, a key process by which AI understands and reacts to text-based input. We’re also releasing source code for these agents to encourage the community to continue to improve semantic understanding in text-based games.
- CODE Blindfold Text Game
Ever since text-based games were proposed as a benchmark for language understanding agents, a key challenge in these games has been the enormous action space. Games like Zork 1 can have up to 98 million possible actions in each state—the majority of which are nonsensical, ungrammatical, or inapplicable. In order to make text-based games more approachable to reinforcement learning (RL) agents, the Jericho framework provides several handicaps such as valid-action identification, which uses the game engine to identify a minimal set of 10–100 textual actions applicable in the current game state. Other handicaps involve the ability to extract the recognized vocabulary for a game and to save and restore previously visited states. Certain RL agents depend on the valid-action handicap, like deep reinforcement relevance network (DRRN), which learns to choose the action within the set of valid actions at each timestep that maximizes expected game scores.

Despite its usefulness from an RL tractability standpoint, the valid-action handicap, through the use of privileged game insights, can expose hidden information about the environment to the agent. For example, In Figure 1, the valid-action take off watch inadvertently leaks the existence of a watch that was not revealed in the observation text.
Our recent paper, “Reading and Acting while Blindfolded: The need for semantics in text game agents,” shows that when using Jericho-provided handicaps, such as the identification of valid-actions, it’s possible for text agents to achieve competitive scores while using textual representations entirely devoid of semantics. The paper has been accepted to the Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL 2021).
Hash-based representation reveals that handicap agents bypass semantic understanding
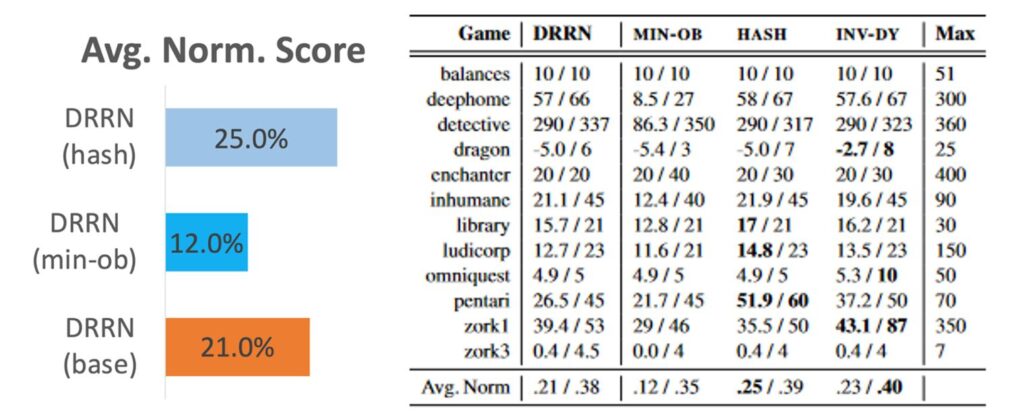
To probe the extent of semantic understanding of the DRRN agent, we replace the observation text and valid-action texts with consistent, yet semantically meaningless text strings derived by hashing the current state and actions. Figure 2 compares the standard textual representation of observations and actions with two ablations. MIN-OB (b) shortens observation text to only include the name of the current location without description of the objects or characters therein. HASH (c) entirely replaces the text of the observation and actions with the output of a hash-based representation.

Specifically, we use Python’s hash function to map each text string to a unique hash value, which ensures even if one word is changed in text, the representation will be completely different. From the perspective of playing this game, representations (b) and (c) would pose significant challenges to a human due to the lack of semantic information.
Subsequently, a DRRN text agent was trained from scratch using RL to estimate the quality of each candidate action. Surprisingly, the agent on the hashed-representation was able to achieve comparable scores with the control agents using the original text-based observations and actions (see Figure 3), and it even outperforms the baseline (DRRN-base) in 3 out of the 12 games. This finding suggests that current text agents are likely circumventing the development of semantic understanding, particularly when trained on single games using the valid-action handicap.
In light of this finding, we highlight two recent methods that we believe encourage agents to build stronger semantic understanding throughout the learning process:
Regularizing semantics via inverse dynamics decoding
Standard RL centers around the idea of learning a policy mapping from observations to actions that maximizes cumulative long-term discounted rewards. We contend that such an objective only encourages robust semantic understanding to the extent that’s required to pick out the most rewarding actions from a list of candidates.
We propose the use of an auxiliary training task that focuses on developing stronger semantic understanding— the inverse dynamics task challenges the agent to predict the action that spans two adjacent state observations. Consider the following observations: You stand at the foot of a tall tree and You sit atop a large branch, feet dangling in the air. It’s reasonable to surmise that the intervening action may have been climb tree. Specifically, the agent is presented with a finite set of valid actions that could have been selected from the previous state and must choose which of them was most likely to have been selected given the text of the subsequent state. This auxiliary loss has been investigated in the context of video games like Super Mario Bros.
By training agents with this inverse dynamics auxiliary task, we show that they have stronger semantic understanding, as evidenced by their ability to generalize between semantically similar states in Figure 4.
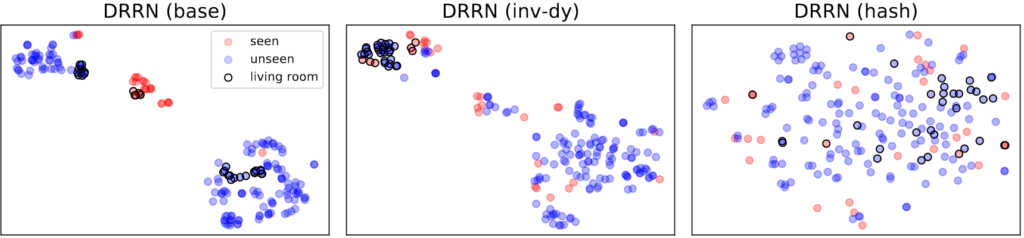
As an added benefit, we show that it’s possible to use the inverse-dynamics model to incentivize the agent to explore regions of the state space in which model predictions are inaccurate. This improved exploration led the agent to notably high single-episode scores of 54, 94, and 113 on Zork 1, compared to previous models that get stuck at a score of 55. Looking at the trajectories, we observe that the inverse-dynamics model uniquely exhibits some challenging exploration behaviors, such as navigating through “a maze of twisty little passages, all alike”; taking a coin at a specific spot of the maze (+10 score); or finding the “Cyclops Room” at the exit of the maze and then going up to the “Treasure Room” (+25 score). Thus, we find that by improving semantic understanding, approaches like inverse dynamics can also lead to better exploration in agents.
Leveraging human priors for action selection
Another way to build in semantic language understanding is to leverage it for action generation. Published in the Conference on Empirical Methods in Natural Language Processing (EMNLP 2020), “Keep CALM and Explore: Language Models for Action Generation in Text-based Games,” introduces a text game–oriented language model called CALM.
CALM (short for Contextual-Action Language Model) avoids the use of the valid-action handicap altogether by using a language model to generate a compact set of candidate actions. CALM starts from a pretrained GPT-2 model and is fine-tuned on a corpus featuring years of human-gameplay transcripts spanning 590 different text-based games. During this training process, CALM is instilled with priors that humans use when playing a large variety of text-based games.

As shown in Figure 5, conditioned on the observation text, randomly sampled actions are nonsensical (outlined in red). CALM, trained with an n-gram model, pairs common verbs with objects from the observation (outlined in blue), and CALM trained with GPT-2 (outlined in green) can generate actions that are more complex and highly relevant.
To quantify this effect, we compared the quality of CALM-generated actions to ground-truth valid actions on walkthrough trajectories from 28 games. We find higher precision and recall with CALM than with a comparably trained model trained using a bag-of-words representation.
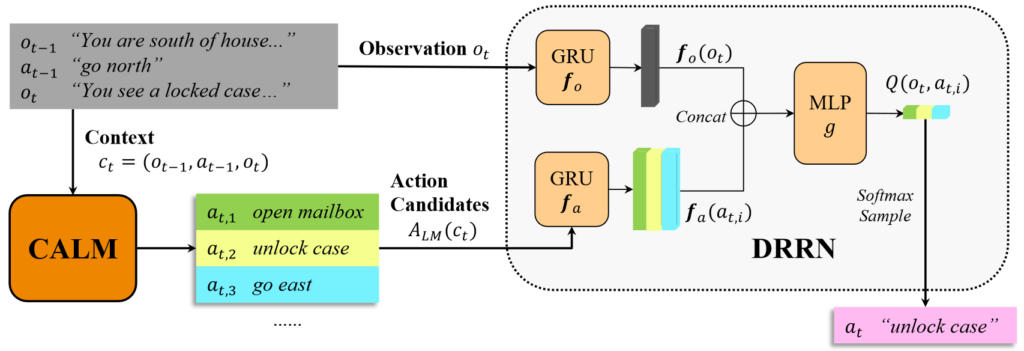
The figure above shows the full integration of the CALM language model with the DRRN learning agent. CALM is responsible for producing Action Candidates conditioned on the current context, while DRRN attempts to select the best Action Candidate from the produced set. This action is then executed in the environment and the cycle repeats.
We subsequently deployed CALM in the RL context on held-out games that were excluded from the training set. CALM acts as a drop-in replacement for the valid-action handicap by generating a small set of likely actions conditioned on the current text observation. We find that in eight of 28 game cases, CALM can entirely replace the need for Jericho’s valid-action and agents trained to pick from CALM-generated actions outperform those trained with the handicap.
We additionally compare against NAIL, a competition-winning general game-playing agent that uses handwritten rules to explore and act. We find that CALM generates an average normalized completion of 9.4% across games, compared to NAIL with 5.6%.
Valid-action identification and CALM: A springboard for furthering semantic understanding
Text-based games remain an exciting and challenging testbed for the development of language agents. Our recent work highlights the need for careful examination of the handicaps as they relate to the development of semantic understanding the text agents trained within. Our findings show that handicaps such as valid-action identification can allow agents to bypass the challenges of developing semantic language understanding. We outlined two different ways of increasing semantic understanding in text agents. First, we show better semantic clustering of text observations using an auxiliary task focused on inverse dynamics prediction. Second, we show compelling performance by using the contextual-action language model to create candidate actions and eliminating the valid-action handicap altogether.
More broadly, we aim to spark discussion with the community around the new methods and experimental protocols to encourage agents to develop better language understanding, and we are excited about the continued development of text-based agents with strong semantic understanding.
Read our paper here and find the source code here.
The post Building stronger semantic understanding into text game reinforcement learning agents appeared first on Microsoft Research.