
This post has been republished via RSS; it originally appeared at: Microsoft Research.

Picture a person walking in a park by a pond. The surrounding environment contains a number of moving objects that change the quality of the environment: clouds moving to hide the sun, altering the quality of light; ducks gliding across the pond, causing its surface to ripple; people walking along a path, their images reflecting on the water. If we’re creating an AI model for navigating to a given goal, for example, a robot navigating to a specific location in a park to deliver a package, we want this model to recognize the robot and any obstacle in its way, but not the changes in its surrounding environment that occur independently of the agent, which we define as exogenous noise.
Although reinforcement learning (RL) has proven to be a successful paradigm for training AI models in navigation tasks, often used in gaming, existing RL methods are not yet robust enough to handle exogenous noise. While they may be able to heuristically solve certain problems, such as helping a robot navigate to a specific destination in a particular environment, there is no guarantee that they can solve problems in environments they have not seen.
In this post, we introduce Path Predictive Elimination (PPE), the first RL algorithm that can solve the problem of exogenous noise with a mathematical guarantee. Specifically, for any problem that satisfies certain assumptions, the algorithm succeeds in solving the problem using a small number of episodes. We discuss this algorithm in detail in our paper, “Provable RL with Exogenous Distractors via Multistep Inverse Dynamics.”

Real-world RL and exogenous noise
To understand how PPE works, it’s important to first discuss how a real-world RL agent (the decision-maker) operates. Agents have an action space with \(A\) number of actions and receive information about the world in the form of an observation. In our example, the robot is the agent, and its action space contains four actions: a step forward, backward, left, or right.
After an agent takes a single action, it gets a new observation—that is, it receives more information about its environment—along with a reward. If the robot observes the park through a camera, the observation takes the form of an image. When an agent has a task to solve, such as reaching a specific destination, it must take a sequence of actions, each resulting in a reward. Its goal is to maximize the sum of rewards. When the robot takes a step forward, the camera generates a new observation of the park, and it receives a reward for this action. It may get a reward of 1 for the first action that takes it toward its goal and 0 otherwise.
Key challenges in real-world RL include how to handle complex observations and very large observation spaces. In our example, the robot in the park will have to work with an image that contains relevant information, such as the position of the destination, but this information is not directly accessible due to the exogenous noise and camera-generated image noise in the observation.
An image can be in a 500 x 500 x 3 pixel space, where each pixel takes 255 values. This would give us 255500 x 500 x 3 the number of different images which is an extremely large number of possibilities. However, the environment is much simpler to describe than this number suggests. This means the observation in an RL environment is generated from a much more compact but hidden endogenous state. In our park example, the endogenous state contains the position of the agent, the destination, and any obstacles around the agent.
In our paper, we assume that the endogenous state dynamics are near-deterministic. That is, taking a fixed action in an endogenous state always leads to the same next endogenous state in most cases. We also require that it is possible to extract the endogenous state from an observation. However, we make no assumptions about dynamics of exogenous noise or how observations are generated.
Most existing RL algorithms are either unable to solve problems containing complex observations or lack a mathematical guarantee for working on new, untried problems. This guarantee is desirable because the cost of failure in the real world can be potentially high. Many existing algorithms require an impractically large amount of data to succeed, requiring the agent to perform a large number of actions before it solves the task.
PPE takes an approach called hidden state decoding, where the agent learns a type of ML model called a decoder to extract the hidden endogenous state from an observation. It does this in a self-supervised manner, meaning it does not require a human to provide it with labels. For example, PPE can learn a decoder to extract the robot and any obstacle’s position in the park. PPE is the first provable algorithm that can extract the endogenous state and use it to perform RL efficiently.
Path Prediction and Elimination: An RL algorithm that is robust to exogenous noise
PPE is simple to implement and is fast to run. It works by learning a small set of paths that can take the agent to all possible endogenous states. The agent can technically consider all possible paths of length \(h\), enabling it to visit every endogenous state. However, as there are \(A^h\) possible paths of length \(h\), the number of paths will overwhelm the agent as \(h\) increases. The more paths the agent has to work with, the more data it needs to solve a given task. Ideally, if there are \(S\) number of endogenous states, we need just \(S\) number of paths, with only one unique path going to each endogenous state. PPE works by eliminating redundant paths that visit the same endogenous state by solving a novel self-supervised classification task.
PPE is similar in structure to the breadth-first search algorithm in that it runs a for-loop, where, in iteration \(h\) of the loop, the agent learns to visit all endogenous states that can be reached by taking \(h\) actions. At the start of iteration, the agent maintains a list of paths of length \(h\). This list has a path to visit every endogenous state that’s reachable after taking \(h\) actions. However, this list may also contain redundant paths, i.e., multiple paths that reach the same endogenous state. When this list is simply all paths of length 1, it corresponds to every action in the agent’s action space.
The top of Figure 2 shows agent’s initial list of paths, which contains at least three paths: \( \pi_1\), \(\pi_2\), and \(\pi_3\). The first two paths reach the same destination, denoted by the endogenous state \(s_1\). In contrast, the last path \(\pi_3\) reaches a different endogenous state \(s_2\). Figure 2 shows a sampled observation (or image) for each endogenous state.
Because PPE wants to learn a small set of paths to visit all endogenous states, it seeks to eliminate the redundant paths by collecting a dataset of observations coupled with the path that was followed to observe them. In Figure 2, both \(\pi_1\) or \(\pi_2\) reach the same endogenous state, so one of them can be eliminated. This is done by randomly selecting a path in its list, following this path to the end, and saving the last observation. For example, our dataset can contain a tuple (\(\pi_1, x\)) where \(\pi_1\) is the policy in our list and \(x\) is the image in top-right of Figure 2. PPE collects a dataset of many such tuples.
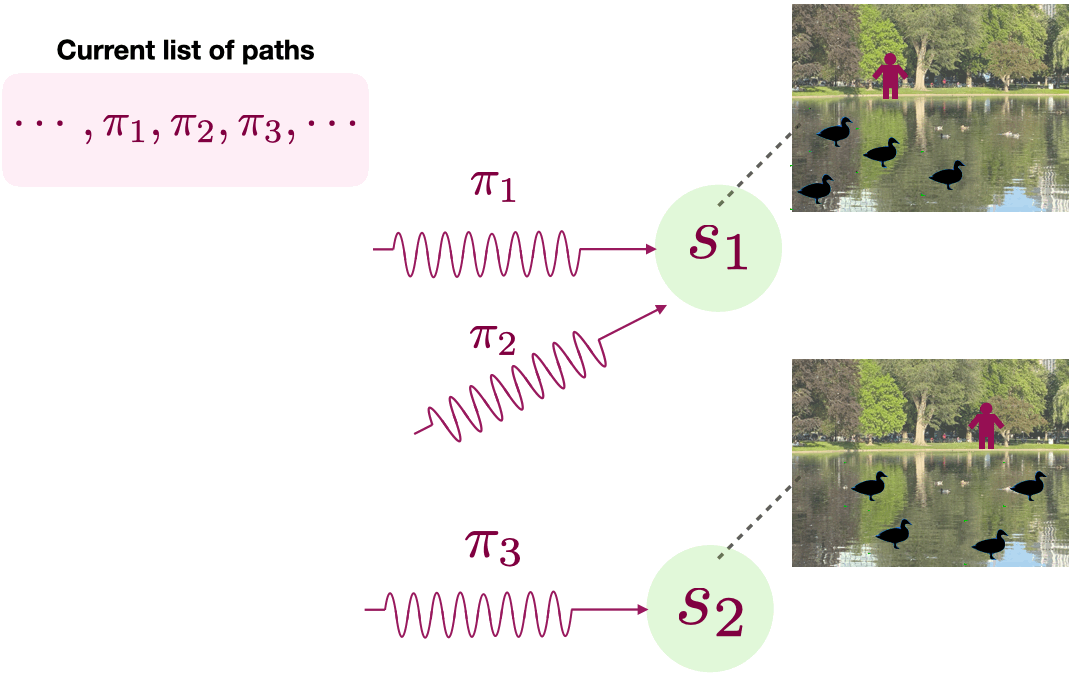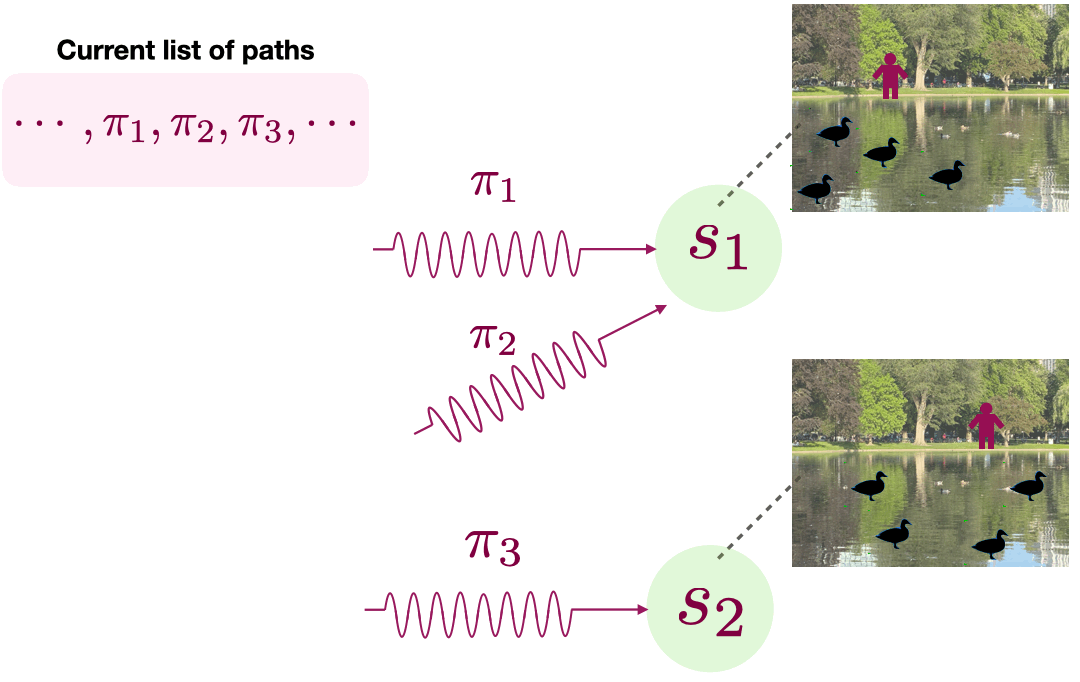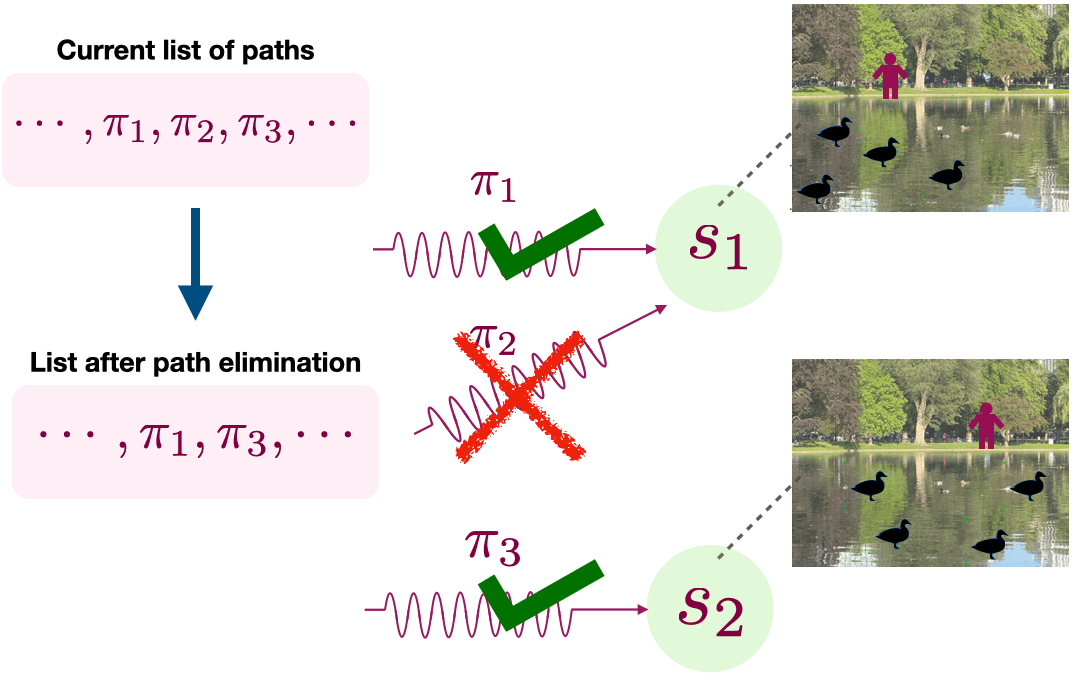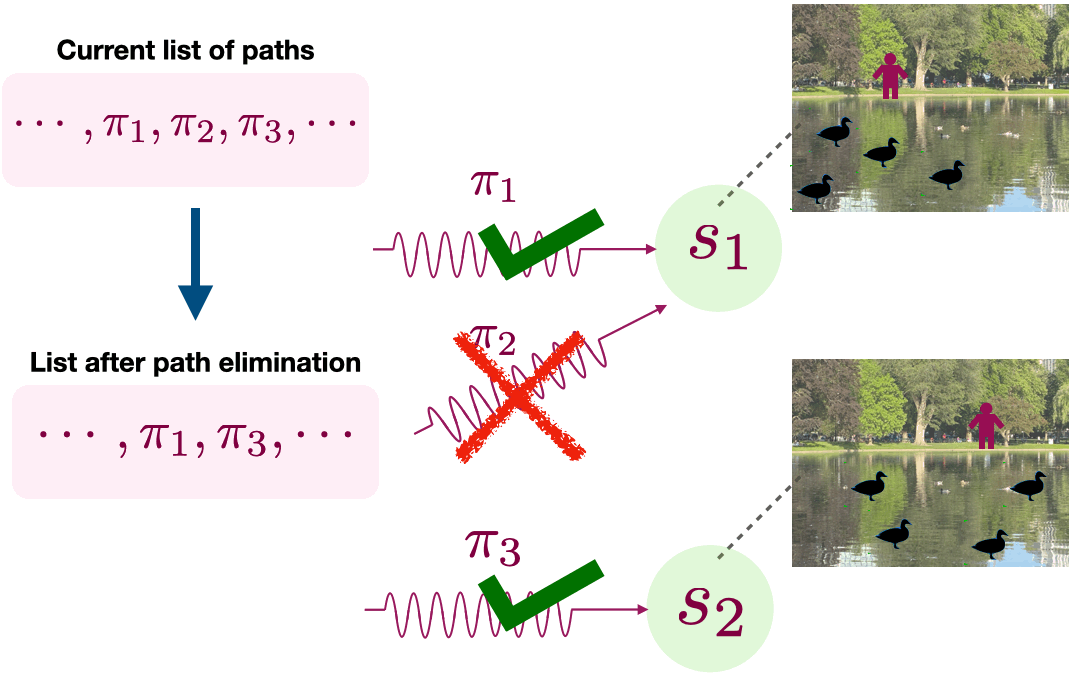
PPE then solves a multiclass classification problem to predict the index of the path from the last observation. The index of a path is computed with respect to the original list. This classification problem can be solved with any appropriate model class, such as deep neural networks, using PyTorch, TensorFlow, or a library of your choice. If two different paths, \(\pi_1\) and \(\pi_2\), reach the same endogenous state, the learned classifier won’t be able to deterministically predict which path was used to visit observations from this state. That is, the learned classifier predicts a high probability for both paths given an observation from this endogenous state. PPE uses this confusion signal to eliminate one of these paths because both paths reach the same endogenous state. PPE also learns a decoder as a result solving the classification problem described above, which maps an observation to the index of the leftover path with the highest probability under the learned classifier.
At the end of iteration \(h\) of the for-loop, PPE will have found a list of leftover paths that includes a unique path for every endogenous state that’s reachable after taking \(h\) actions. It then expands these leftover paths to create the list for the next iteration of the for-loop. For every path that’s left over, PPE creates \(A\) number of new paths by concatenating every action to the end of the path. The for-loop then continues with the next iteration.
Note that the above steps of PPE can be computed even in the absence of rewards. The output of these steps, namely the decoder and the learned leftover paths, can be cached and used to optimize any reward functions provided later. We discuss various strategies to optimize any given reward function in our paper, including both model-free and model-based approaches.
Proof, experiment, and code
The paper also provides a mathematical proof that PPE efficiently solves a large class of RL problems. Using a small amount of data, it can accurately explore, find a policy that achieves maximum sum of rewards, recover a decoder that maps the observation to its hidden endogenous state, and recover the dynamics of the endogenous state with a high probability. We describe various experiments where PPE successfully performs these tasks in line with its mathematical guarantee and outperforms various prior methods.
This is illustrated in Figure 3. It depicts a visual grid-world where the agent’s goal is to navigate to the slice of pizza on the other side of the pond, populated by two ducks that move independently of agent’s actions and are the source of exogenous noise. The endogenous state will consist of the position of the agent. The figure shows what PPE is expected to do in this task. It will gradually learn longer paths that reach various endogenous states in the environment. It will also learn a decoder and use it to extract the dynamics of the latent endogenous state, shown on the right.
The road ahead
While PPE is the first RL algorithm that offers a mathematical guarantee in the presence of exogenous noise, there is still work to do before we can solve every RL problem that includes exogenous noise. Some of the unanswered questions that we are pursuing include:
- How can we eliminate the assumption that PPE makes, that latent endogenous state dynamics are near-deterministic?
- Can we extend PPE to work in nonepisodic settings, where the agent generates a single long episode?
- How does PPE perform on real-world problems?
- Can we make PPE a truly online algorithm, eliminating the need to collect large datasets before it improves?
RL algorithms hold great promise for improving applications in a diverse range of fields, from robotics, gaming, and software debugging, to healthcare. However, exogenous noise presents a serious challenge in unlocking the full potential of RL agents in the real world. We’re hopeful that PPE will motivate further research in RL in the presence of exogenous noise.
The post PPE: A fast and provably efficient RL algorithm for exogenous noise appeared first on Microsoft Research.