
This post has been republished via RSS; it originally appeared at: Microsoft Research.

The amount of visual data we accumulate around the world is mind boggling. However, not all the images are captured by high-end DSLR cameras, and very often they suffer from imperfections. It is of tremendous benefit to save those degraded images so that users can reuse them for their own design or other aesthetic purposes.
In this blog, we are going to present our latest efforts in image enhancement. The first technique enhances the image resolution of an image file by referring to external reference images. Compared to traditional learning-based methods, the reference-based solution solves the ambiguity of computer hallucination and achieves impressive visual quality. The second technique restores old photographs, which contain a mix of degradations that are hard to model. To solve this, we propose a novel triplet domain translation network by leveraging real photos along with massive synthetic image pairs. The proposed technique revives the photos to a modern form. These two works enable users to enhance their photos with ease, and the techniques were presented at CVPR 2020 (Computer Vision and Pattern Recognition).
Learning texture transformer network for image super-resolution
Image super-resolution (SR) aims to recover natural and realistic textures for a high-resolution image from its degraded low-resolution counterpart, which is an important problem in the image enhancement field. Traditional single image super-resolution usually trains a deep convolutional neural network to recover a high-resolution image from the low-resolution image. Models trained with pixel-wise reconstruction loss functions often result in blurry effects for complex textures in the generated high-resolution results, which is far from satisfactory. Recently, some approaches adopt generative adversarial networks (GANs) to relieve the above problems, but the resultant hallucinations and artifacts caused by GANs further pose grand challenges to image SR tasks.
To address the above problems, reference-based image super-resolution (RefSR) is proposed as a new direction in the image SR field. RefSR approaches utilize information from a high-resolution image, which is similar to the input image, to assist in the recovery process. The introduction of a high-resolution reference image transforms the difficult texture generation process to a simple texture search and transfer, which achieves significant improvement in visual quality. We propose a novel Texture Transformer Network for Image Super-Resolution (TTSR). This approach can effectively search and transfer high-resolution texture information for the low-resolution input, which makes full use of the reference image to solve blurry effects and artifacts.
Texture transformer features
Transformer is widely used in natural language processing, which has achieved remarkable results. However, transformer is rarely used in image generation tasks. Researchers at Microsoft Research Asia propose a novel texture transformer for image super-resolution to successfully apply transformer in image generation tasks. As shown in Figure 1, there are four parts in the texture transformer: the learnable texture extractor (LTE), the relevance embedding module (RE), the hard-attention module for feature transfer (HA) and the soft-attention module for feature synthesis (SA). Details will be discussed below.
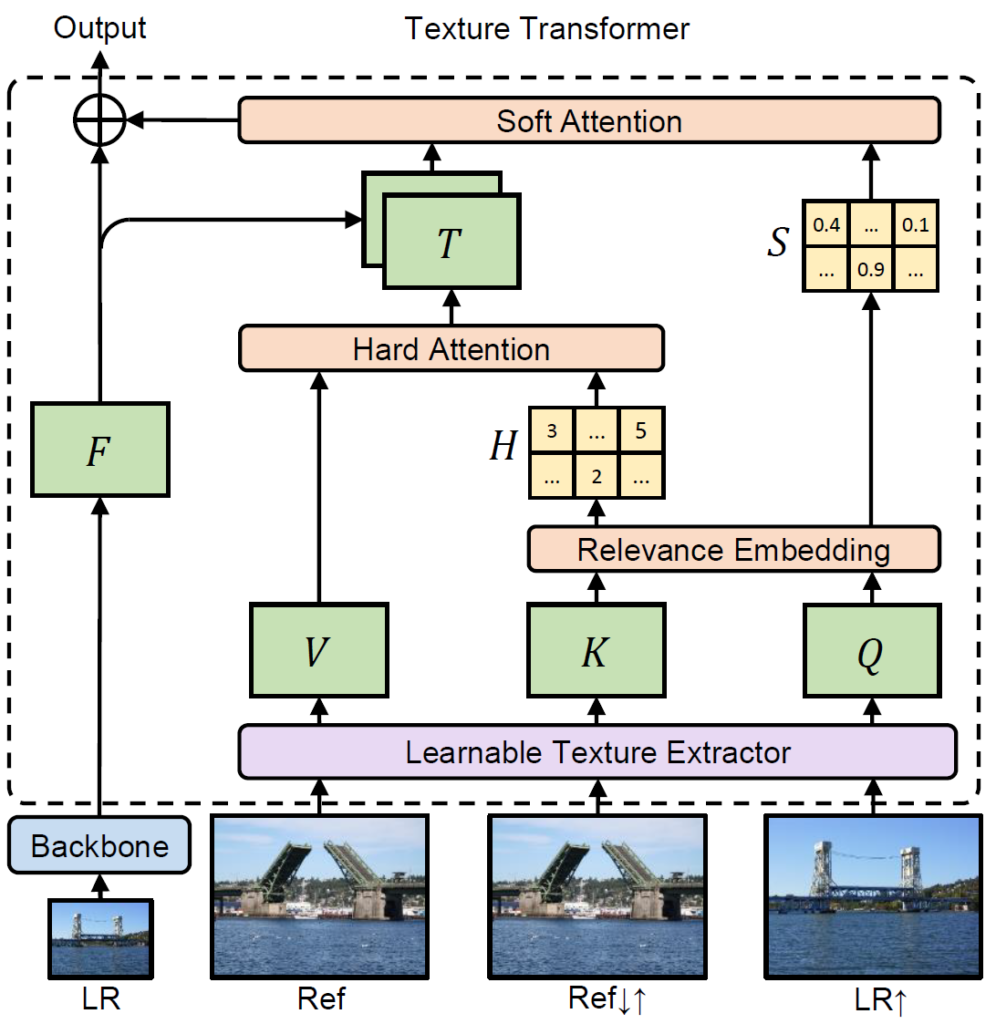
Figure 1: The proposed texture transformer.
- Learnable texture transformer. For texture extraction, recent approaches usually use semantic features extracted by a pre-trained classification model like VGG. However, such design has obvious drawbacks. First, the training objective of VGG network is a semantic classification label, and the high-level information is different from the low-level texture information. Therefore, it is not proper to use VGG features as the texture features. Second, the needed texture information is variable for different tasks. To solve the above problems, a learnable texture extractor, whose parameters will be updated during end-to-end training, is used. Such a design encourages a joint feature learning across the low-resolution (LR) and the reference (Ref) image, in which more accurate texture features can be captured, which provides a superior foundation for texture search and transfer to generate high-quality results.
- Relevance embedding. As shown in Figure 1, the same as traditional transformer, the proposed texture transformer also has Q, K, and V elements. Q (query) represents the texture information extracted from the low-resolution input image. The Ref image is sequentially applied bicubic down-sampling and up-sampling with the same factor (4x) to be domain-consistent with LR and to obtain texture information as K (key). V (value) indicates the texture features extracted from the original Ref image which is used to transfer. For Q and K, a relevance embedding module is proposed to build a relationship between the LR and Ref image. Specifically, this module unfolds both Q and K into patches and calculates the relevance between each Q patch and each K patch by normalized inner product. A larger inner product indicates higher relevance between two patches, which means more texture features can be transferred. In contrast, lower inner product indicates lower relevance, and therefore less texture features can be transferred. The relevance embedding module will output a hard-attention map and a soft-attention map. The hard-attention map records the position of the most relevant patch in K for each patch in Q, while the soft-attention map records specific relevance values, that is the inner products. These two maps will be applied in the hard-attention module and the soft-attention module.
- Hard attention. In the hard-attention module, we utilize the recorded positions in the hard-attention map to transfer corresponding patches, forming the transferred texture feature T. T contains the most relevant texture features of the Ref image in every position, and it will be synthesized with backbone features by concatenation operation.
- Soft attention. In the soft-attention module, the above synthesized features will be multiplied element-wise by the soft-attention map. In such a design, more relevant textures can be enhanced, while less relevant ones will be relieved. Therefore, the soft-attention module can utilize the transferred textures more accurately.
Cross-scale feature integration
A traditional transformer achieves more powerful representation by stacking, but in an image generation task, simple stacking is not effective . To solve this, the texture transformer can be further stacked in a cross-scale way with a cross-scale feature integration module. The proposed texture transformers are applied in three scales: 1x, 2x, and 4x. Features from different scales will be fused by up-sampling or strided convolution. In such a design, the texture features transferred from the stacked texture transformers are exchanged across each scale, which achieves a more powerful feature representation and further improves the performance of our approach.

Figure 2: Architecture of stacking multiple texture transformers in a cross-scale way with the proposed cross-scale feature integration module (CSFI).
There are 3 loss functions in this approach: reconstruction loss, adversarial loss, and perceptual loss. The overall loss can be interpreted as:

- Reconstruction loss. L1 loss is adopted since L1 is superior to L2 in generating clear images. This loss can be interpreted as:

- Adversarial loss. Compared to reconstruction loss, the adversarial has less constraints on low-level frequency. This loss requires the domain consistency between generated results and the original image to generate more clear and realistic textures. This loss is based on WGAN-GP which can be interpreted as:

- Perceptual loss. Perceptual loss is a special reconstruction loss imposed on the feature space of a neural network. There are two kinds of perceptual losses. The first one adopts VGG as the feature extraction network for the result image and the original high-resolution image. The second one adopts the proposed texture extractor to constraint features of the result image and the transferred features T. These two losses can be interpreted as:
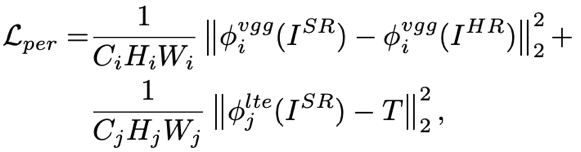
Experiment results
The proposed TTSR is quantitatively evaluated on CUFED5, Sun80, Urban100, and Manga109 dataset, which is shown in Table 1.
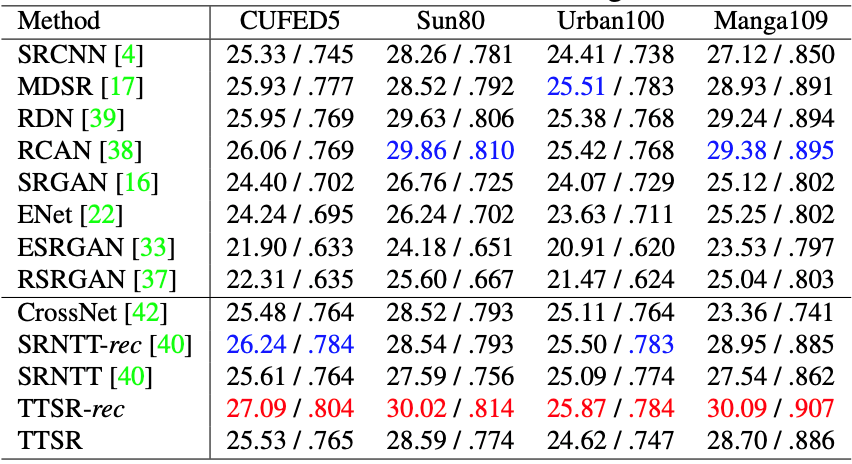
Table 1: Quantitative comparison between the proposed TTSR and other methods on different datasets.
On the other hand, a user study is conducted for qualitative evaluation. The proposed TTSR significantly outperforms other approaches with over 90% of users voting for ours, which verifies the favorable visual quality of TTSR. Figure 3 shows the results.

Figure 3: User study results.
Figure 4 shows the visual comparison between the proposed TTSR and other methods on different datasets. TTSR achieves the best visual quality.
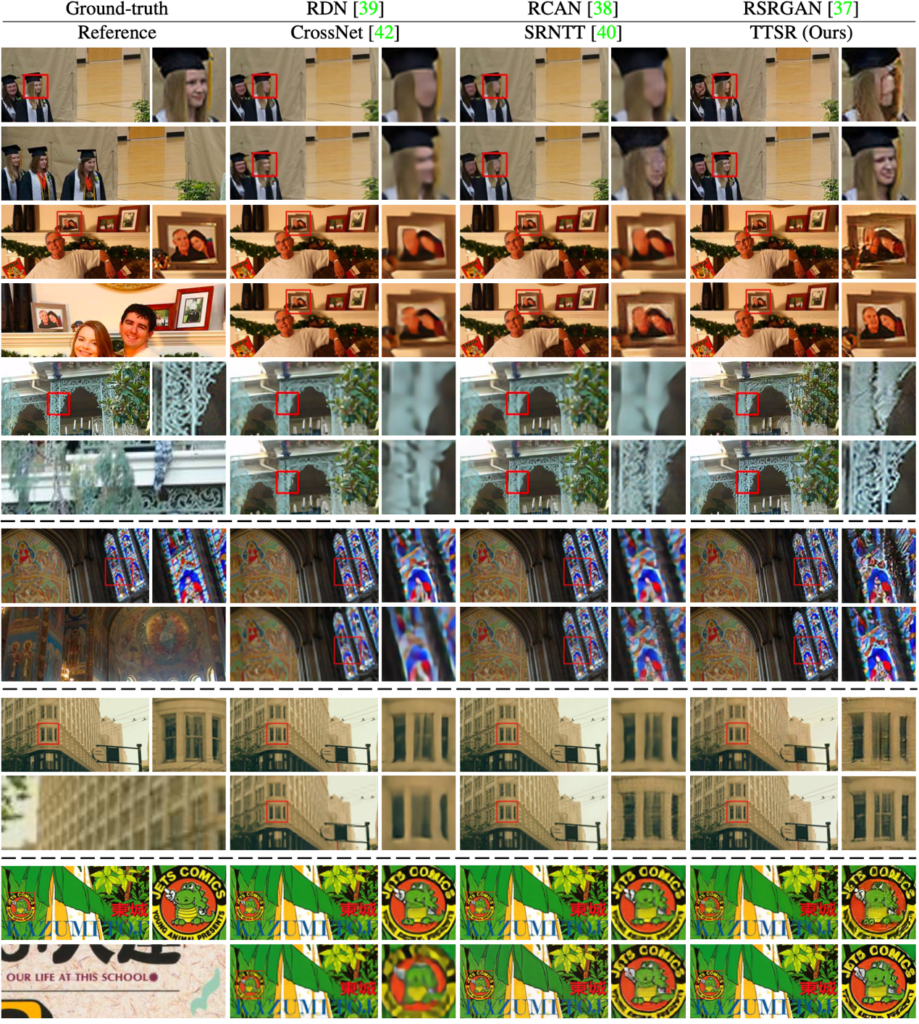
Figure 4: Visual comparison between TTSR and other methods compared to the ground truth and reference. Methods compared include RDN, CrossNet, RCAN, SRNTT, RSRGAN, and our own TTSR.
For more technical details, check out our CVPR 2020 paper “Learning Texture Transformer Network for Image Super-Resolution”. Source code and pre-trained models are available at https://github.com/researchmm/TTSR.
Bringing old photos back to life
People can be nostalgic and often cherish the happy moments in revisiting old times. There is a strong desire to bring old photos back to their original quality so that people can feel the nostalgia of travelling back to their childhood or experiencing earlier memories. However, manually restoring old photos is usually laborious and time consuming, and most users may not be able to afford these expensive services. Researchers at Microsoft recently proposed a technique to automate this restoration process, which revives old photos with compelling quality using AI. Different from simply cascading multiple processing operators, we propose a solution specifically for old photos and thus achieve far better results. This work will be presented in an upcoming CVPR 2020 presentation.
With the emergence of deep learning, one can address a variety of low-level image restoration problems by exploiting the powerful representation capability of convolutional neural networks, that is, learning the mapping for a specific task from a large amount of synthetic images. The same framework, however, does not apply to old photo restoration. This is because old photos are plagued with multiple degradations (such as scratches, blemishes, color fading, or film noises) and there exists no degradation model that can realistically render old photo artifacts (Figure 5). Also, photography technology consistently evolves, so photos of different eras demonstrate different artifacts. As a result, the domain gap between the synthetic images and real old photos makes the network fail to generalize.

Figure 5
We formulate old photo restoration as a triplet domain translation problem. Specifically, we leverage data from three domains: the real photo domain R, the synthetic domain X where images suffer from artificial degradation, and the corresponding ground truth domain Y that comprises images without degradation. The synthetic images in R have their correspondence counterpart in Y. We learn the mapping X→Y in the latent space. Such triplet domain translation (Figure 2) is crucial to our task as it leverages the unlabeled real photos as well as a large amount of synthetic data associated with ground truth.

Figure 6
As shown in Figure 6 , we propose mapping the synthetic images and the real photos to the same latent space with a shared variational autoencoder (VAE). Intuitively, synthetic images have a similar appearance to real old photos, so it is easier to align them into the same space due to their distribution overlap. In terms of network structure, we adopt VAE rather than vanilla autoencoder because VAE features denser latent representation due to the assumption of Gaussian prior for latent codes, which helps produce closer latent space with VAE1 and leads to a smaller domain gap. To further narrow the domain gap in this reduced space, we propose using an adversarial network to examine the residual latent gap.
Meanwhile, another VAE is trained to project clean images into the corresponding latent space. In this way, we obtain two latent spaces, the shared space Z_X (≈Z_R) for corrupted images and the latent space Z_Y for clean images. We now fix the encoders and decoders for both VAEs and train a mapping network that maps the latent spaces in between. This mapping network is learned by making use of paired data in R and Y. The mapping in the compact low-dimensional latent space is in principle much easier to learn than in the high-dimensional image space.
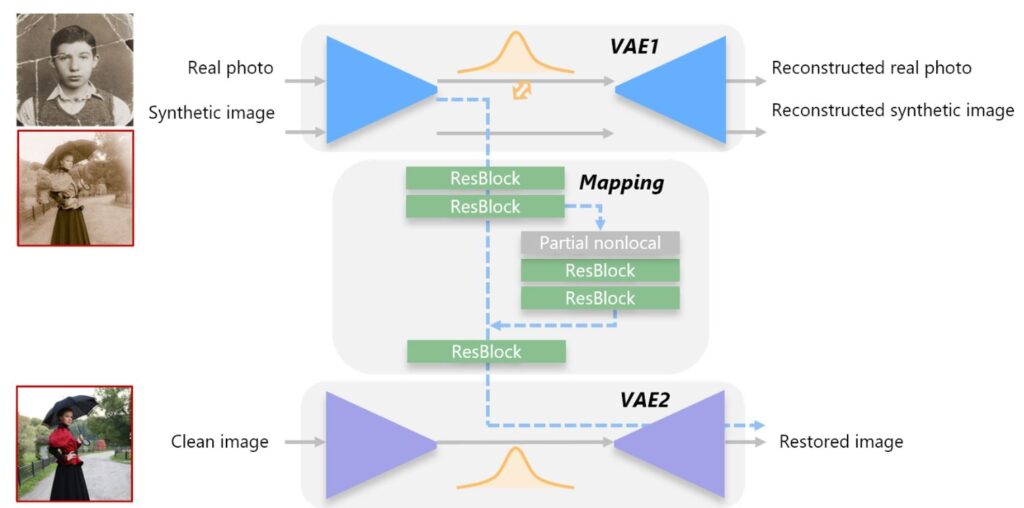
Figure 7
Furthermore, we propose global-local context fusion in the latent mapping network. This is motivated by the observation that artifacts existing in old photos can be categorized into two types. Unstructured defects such as film noise, blurriness, and color fading can be restored with spatially homogeneous filters by making use of surrounding pixels within the local patch. Structured defects such as scratches and blotches, on the other hand, should be filled in by considering the global context to ensure the structural consistency. In implementation, we train another scratch detection network to detect scratch areas in the photos, and we feed this mask information into the partial nonlocal block in the global branch so that the restoration excludes information in the corrupted regions during image inpainting.
Because the domain gap is greatly reduced in the latent space, the network during inference is capable of recovering old photos at the same quality of processing synthetic images. In addition, we crop faces in portraits and train a refinement network with a similar translation scheme on face dataset. The facial details—even under severe degradation—can be hallucinated at this stage, which improves the perceptual quality towards reconstructed photos.
Our method provides superior quality when comparing with several state-of-the-art methods in real photo restoration, as shown in Figure 8 . Our method appears the most sharp, vibrant, and realistic when compared to existing methods. During the subjective evaluation, our method is preferred as the best in 64.86% cases.

Figure 8
We present more results of our method in the following Figure 9. Our method works remarkably well to recover real photos from different periods.

Figure 9
Please refer to our paper, “Bringing Old Photos Back to Life,” for more technical details.
Apart from photo restoration, colorizing a legacy photo or video is another area of interest to many people. In fact, we have published another CVPR paper earlier (https://arxiv.org/abs/1906.09909). Here, we leave you with a photo demo of this technology.

The post Enhancing your photos through artificial intelligence appeared first on Microsoft Research.